







groupby一个索引的比较简单,这里主要讲两个索引的:
这里先设dataframe为下图
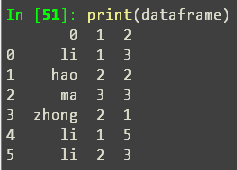
然后根据第0列和第1列来进行分组,再对第二列进行数量统计,这里用了nunique函数来进行数量统计

上图中最上面的2表示是根据原表的第3列即序号2的那一列使用的agg函数得到的结果。
unstack是把一维表转换成二维表,即把(0,1)这对分组条件分别写成表的行列索引,一一对应agg函数得到的结果,如下图:

stack是把二维表转换成一维表,类似花括号形式(就像是思维导图一层一层括出去),第一列写上原本的行索引,第二列再第一列的每个行索引上写上所有列索引:(即把分组根据的(0,1)对写为行索引)

这里有0是因为前面使用unstack时把null填为了0,否则会返回为原表















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









