







需求:想计算每个brand有几种type

如果直接用groupby().count(), 则会把type里的重复值也一起算了进去。
data.groupby(['brand'])[['type']].count().reset_index()
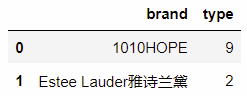
因此我们在计算之前要先去一次重
# 两种写法都可以
data.groupby(['brand']).nunique().reset_index()
# data.groupby(['brand']).agg({'type':pd.Series.nunique}).reset_index()

- pd.unique: 返回列中的不重复值,返回的是一个list
- pd.nunique: 返回列中不重复值的数量,返回的是一个数















 2353
2353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









