






目录
模型评估方法概述
机器学习模型评估是评估模型性能的过程,是机器学习的核心环节之一。其主要目的是通过使用某些评估指标来评估模型的预测能力,并且确定哪个模型最适合特定的数据集。
机器其学习中常见的两类问题有分类问题和回归问题,其中,分类问题主要使用精确率,召回率,F分数等进行评估,回归问题主要使用平均绝对误差,均方误差等方法。
1.数据集的划分
在机器学习中将数据集分为训练集和测试集,其中训练集用来训练模型,测试集用来验证模型性能,两者之比一般为8/2或者7/3.
划分数据集的一般方法有留出法,交叉验证法,和自助法等等。
2.常见评估指标
首先我们补充一些关于混淆矩阵的知识。混淆矩阵通过计算各种分类度量,指导模型的评估。
| 正例(Actual) | 负例(Actual) | |
| 正例(Predicted) | TP | FP |
| 负例(Predicted) | FN | TN |
真阳性(True Positive,TP):指被分类器正确分类的正例数据
真阴性(True Negative,TN):指被分类器正确分类的负例数据
假阳性(False Positive,FP):被错误地标记为正例数据的负例数据
假阴性(False Negative,FN):被错误地标记为负例数据的正例数据
2.1准确率(Accuray)
准确率是指模型中正确分类的样本数与检测样本总数的比值,是分类问题中常用的评估指标。准确率越高,证明模型越好。
公式:Accuray=(TP+TN)/(P+N)
2.2召回率(Recall)
召回率(敏感度,真实例率)是指模型中正元组中被预测准确的比例,可用于评估模型的完整性。
公式:Recal=TP/P
2.3精确率(Precision)
精确率是指在预测结果的正元组里真实正元组的比例。主要用于评估模型的准确性
公式:Precision=TP/(TP+FP)
2.4F1(F1 sorce)
F1是精确率和召回率的加权平均值。它是一个综合指标,可以同时评估模型的准确性和完整性。
F1=2*(Precision*Recall)/(Precision+Recall)
2.5AUC值(Area Under the ROC Curve)
AUC值是用于评估二分类模型性能的指标。它是ROC曲线下的面积,可以衡量模型预测正例和负例的能力。
其中ROC曲线是以横坐标为 FPR ,以纵坐标为 TPR ,画出的一条曲线。 ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。描述分类器的True Positive Rate与False Positive Rate之间的变化关系。
AUC的取值在0.5~1之间,AUC取值越大表示这个模型的效果越好。当AUC等于0.5时表示这个模型没有任何价值,当AUC取值为1时表示这个模型已经趋近完美。
曲线绘制代码:
import matplotlib.pyplot as plt from sklearn.metrics import roc_curve, auc# y_test:实际的标签, dataset_pred:预测的概率值。fpr, tpr, thresholds = roc_curve(y_test, dataset_pred)roc_auc = auc(fpr, tpr) #画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来 plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))plt.xlabel(\"FPR (False Positive Rate)\")plt.ylabel(\"TPR (True Positive Rate)\")plt.title(\"Receiver Operating Characteristic, ROC(AUC = %0.2f)\"% (roc_auc))plt.show()3.过拟合与欠拟合
3.1欠拟合
欠拟合是机器学习模型不能在训练集上获得足够小的误差,即训练误差太大,模型在训练集中没有训练好
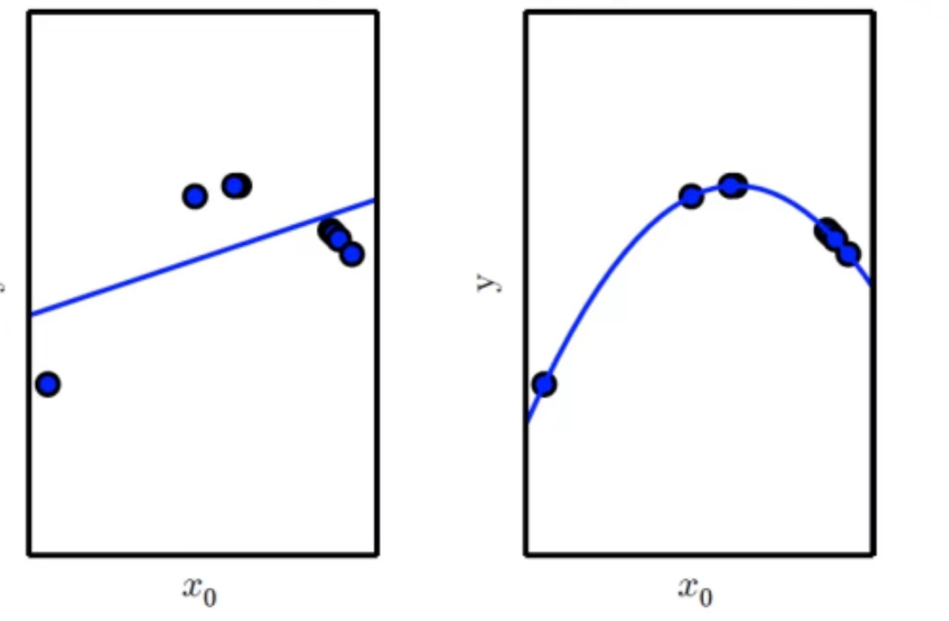
根本原因:欠拟合的根本原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大,训练不充分。
解决方法:1.可以通过增加数据维度,即为增加对数据集的训练
2.增加参数的大小
3.2过拟合
在训练集上误差低,在测试集上误差高

根本原因:模型将训练数据学习的太彻底的,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,模型泛化能力太差。
解决方法:1.减少特征维度。
2.正则化。即为保留特征,但是减少参数的大小
3.扩大数据集
3.3实例
3.4.偏差与方差
偏差:预计值的期望与真实值之间的差距;
方差:预测值的离散程度,也就是离其期望值的距离;
我们知道欠拟合是模型在训练集上误差过高,过拟合模型是在训练集上误差低,在测试集误差高,那么模型误差的来源是什么呢?其实,模型在训练集上的误差来源主要是偏差,在测试集上误差来源主要是方差。
欠拟合是一种高偏差的情况,过拟合是一种低偏差,高方差的情况
4.实战
4.1导入相关库
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)4.2数据集准备和划分
本次准备的是一个关于糖尿病的数据集,数据集如下所示
进行数据预处理
将数据集划分为测试集和训练集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
结果如下
4.3引入knn模型训练
n_neighbors:就是选取最近的点的个数k
p=2,metric='euclidean':使用欧几里得计算距离
classifier = KNeighborsClassifier(n_neighbors=11,p=2,metric='euclidean')
对测试集进行模型的训练
classifier.fit(X_train,y_train)
4.4交叉验证
交叉验证就是可以解决机器模型需要考试的问题,即为将训练集中的一部分数据作为验证集对机器学习进行验证,起到考试的作用。
本次实验我们调用了sklearn的库进行交叉验证
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
# K折抽取数据的对象
skflods = StratifiedKFold(n_splits=3, random_state=520 , shuffle= True)
for train_index, test_index in skflods.split(X_train, y_train_5):
# 将模型克隆一份
clone_clf = clone(sgd_clf)
# 将训练集划分为更小的训练集和验证集
X_train_folds = X_train.iloc[train_index]
y_train_folds = y_train_5.iloc[train_index]
X_test_folds = X_train.iloc[test_index]
y_test_folds = y_train_5.iloc[test_index]
# 训练克隆的模型
clone_clf.fit(X_train_folds, y_train_folds)
# 进行预测
y_pred = clone_clf.predict(X_test_folds)
# 计算当前交叉验证的预测正确的样本数
n_correct = sum(y_pred==y_test_folds)
# 输出当前交叉验证的准确率
print(n_correct / len(y_pred))
输出结果:0.97914411656667
0.97828506704218
0.98228494459070
这证明机器学习自己考试的效果很好
4.5模型评估
混淆矩阵
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf,X_train,y_train_5,cv = 3)
print(y_train_pred.shape)
print(X_train.shape)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5,y_train_pred)评估
from sklearn.metrics import precision_score,recall_score
# 准确率
print("precision_score:",precision_score(y_train_5,y_train_pred))
# 召回率
print("recall_score:",recall_score(y_train_5,y_train_pred))
# F1分数
print("f1_score:",f1_score(y_train_5,y_train_pred))输出:precision_score: 0.858335295502
recall_score: 0.794928698752
f1_score: 0.75673319977
4.6总结
模型评估的指标多种多样,例如ROC曲线主要用于评估分类模型性能,因此我们在不同的场景下需要选取不同的模型评估指标。















 1740
1740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









