






目录
一.决策树的基本知识
1.概念:
决策树是一种基于树状结构的机器学习算法,用于解决分类和回归问题。它模拟人类在做决策时的思维过程,通过一系列的分支和判定条件来做出预测或分类。
2.结构:
决策树的结构类似于一个流程图,由节点和边组成。每个节点代表一个特征或属性,边表示基于该属性的取值进行的决策。根节点是起始点,内部节点表示决策条件,叶节点表示最终的分类或回归结果。
3.特征选取
特征(Feature):用于决策树分裂的输入变量或属性。决策树的构建依赖于选择最佳的特征进行分裂。
3.1常见特征选取的方法
3.1.1信息增益(Information Gain):
信息增益是根据信息论中的熵来衡量特征对于分类任务的重要性。它计算当前节点分裂前后的熵的差异,选择能够最大程度降低熵的特征作为分裂特征。
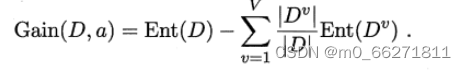
信息熵的计算:
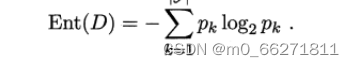
信息熵,是度量样本集合纯度的一种指标,Ent(D)的值越小,则样本集D的纯度越高;
3.1.2基尼指数(Gini Index)
基尼指数是衡量数据集的不纯度的指标,用于评估特征的重要性。在特征选择时,基尼指数会计算分裂前后数据集的基尼指数差异,选择能够最大程度降低基尼指数的特征作为分裂特征。
3.1.3均方差(Mean Squared Error)
均方差主要应用于回归问题中。在特征选择时,均方差会计算分裂前后数据集的均方差差异,选择能够最大程度降低均方差的特征作为分裂特征。
3.1.4增益率(Gain Ratio)
增益率是信息增益的一种变体,用于解决信息增益偏向于具有更多取值的特征的问题。增益率会考虑特征的取值数量,选择能够最大程度提高分裂质量的特征。
4.剪枝
决策树构建完成后,为了避免过度拟合,并且减少时间空间复杂度,可以对决策树进行剪枝操作。剪枝过程通过移除一些子树或节点来简化决策树。
4.2常见几种基本剪枝方法
-
预剪枝(Pre-pruning):预剪枝是在决策树构建的过程中,在进行节点分裂前就停止分裂的策略。它基于一些预定义的停止条件来判断是否应该停止分裂,常见的停止条件包括达到最大深度、节点中的数据数量小于某个阈值等。
-
后剪枝(Post-pruning):后剪枝是在决策树构建完成后,通过从底部开始逐步删除子树或节点的策略来简化决策树。具体操作可以通过计算剪枝前后验证集上的损失函数(如交叉熵、误分类率等)差异来确定是否剪枝。如果剪枝后的性能没有显著下降,则可以进行剪枝操作。
-
悲观剪枝(Pessimistic Error Pruning):悲观剪枝是一种基于错误率的剪枝方法,它假设剪枝后的性能不会好于剪枝前。具体操作是计算剪枝前后验证集上的错误率差异,如果剪枝后的错误率没有显著增加,则可以进行剪枝操作。
-
代价复杂性剪枝(Cost-Complexity Pruning):代价复杂性剪枝是一种基于代价复杂性的剪枝方法,它考虑到模型的复杂度和性能之间的权衡。具体操作是通过引入一个惩罚项来平衡模型的复杂性和性能,从而选择最优的剪枝节点。
上述剪枝方法可以分开使用,也可以结合使用,根据具体问题来灵活运用各种方法
二.决策树的构建
1.一般流程
-
数据收集:收集并准备用于训练模型的数据集。
-
特征选择:从数据集中选择最有价值的特征,以便构建决策树。
-
决策树构建:使用训练数据集来构建决策树,该过程包括选择根节点、选择分裂节点、确定分裂标准和停止条件等步骤。
-
决策树剪枝:在构建完成后,对决策树进行剪枝以避免过度拟合。
-
决策树的测试和应用:使用测试数据集评估决策树的性能,并将其应用于实际问题。
2.实战
2.1数据收集
这里准备的是一个关于毕业薪资水平的数据集
如图所示
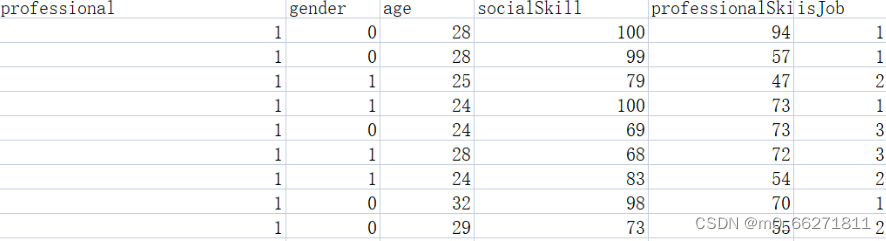
def createDataSet():
data = pd.read_csv('movie.csv')
print(np.array(data[0:10]))
# 将pandas转化成list
dataSet = np.array(data[0:10]).tolist()
print(type(dataSet))
labels = ['professional', 'gender', 'age', 'socialSkill', 'professionalSkill']
return dataSet, labels2.2计算信息熵
def _information_gain(self, parent, left_child, right_child):
# 计算信息熵
entropy = self._entropy(parent)
# 计算加权平均信息熵
p = float(len(left_child)) / (len(left_child) + len(right_child))
info_gain = entropy - p * self._entropy(left_child) - (1 - p) * self._entropy(right_child)
return info_gain
def _entropy(self, y):
# 计算信息熵
classes = set(y)
entropy = 0
for cls in classes:
p = float(len(y[y == cls])) / len(y)
entropy -= p * np.log2(p)
return entropy2.3根据特征和阈值划分样本子集
# 根据给定规则划分数据集
def splitDataSet(dataset, axis, val):
retDataSet = []
for featVec in dataset:
# 依据给定特征匹配,划分数据集
if featVec[axis] == val:
# reducedFeatVec存储去掉axis特征的集合
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet2.4构建决策树并进行剪枝
# 创建决策树
def createTree(dataset, labels, featLabels):
# 数据集的标签
classList = [example[-1] for example in dataset]
print(classList)
# 如果要进分类的标签相同,直接返回,无需分类
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataset[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataset)
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel: {}}
del labels[bestFeat]
featValue = [example[bestFeat] for example in dataset]
uniqueVals = set(featValue)
for value in uniqueVals:
sublabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataset, bestFeat, value), sublabels, featLabels)
return myTree
# 统计classList中出现最多的元素
def majorityCnt(classList):
classCount = {}
# 统计classList中每个元素出现的次数
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
# 字典降序排列
sortedclassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedclassCount[0][0]
2.5结果与分析
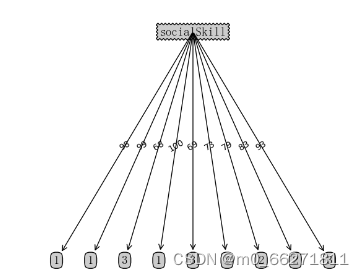
分析:得到该结果的原因是选取的数据中不一样的很多,这导致得到的决策树没有较好的泛化能力
2.6改进
我们可以改变数据集中的数据,如图
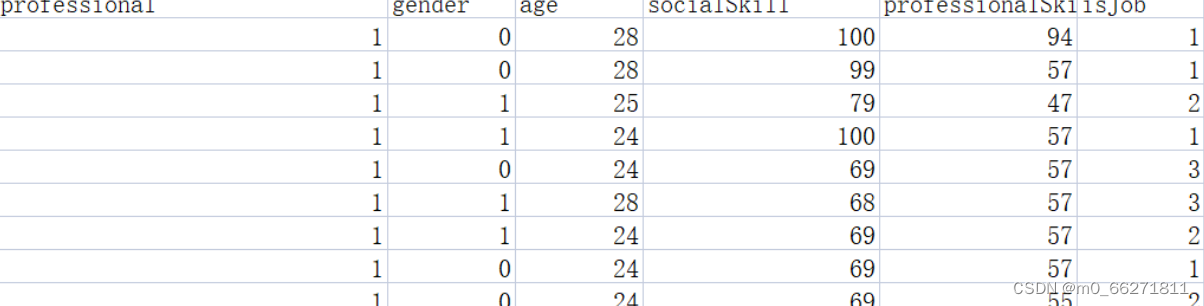
这样得到的决策树将更有价值
3.决策树的优缺点
经过以上实验,我们可以很明显的感受到决策树的优缺点
3.1优点
- 简单直观:决策树的模型可以很直观地表示数据的特征与类别之间的关系,易于理解和解释。
- 特征选择:决策树可以通过特征选择来确定最重要的特征,进而提取出对分类起决定性作用的特征。
- 适应多类型数据:决策树可以处理离散型和连续型特征,并且可以用于分类和回归问题。
- 鲁棒性:决策树对于异常值和噪声相对较为鲁棒,不会对其过度敏感。
3.2缺点
- 容易过拟合:决策树容易在训练数据上过拟合,如果没有合适的剪枝策略,决策树可能会生成过于复杂的模型,导致在新数据上表现不佳。
- 不稳定性:数据的微小变动可能会导致生成完全不同的决策树模型,这使得决策树在某些情况下比其他算法更不稳定。
- 忽略特征间的相关性:决策树在划分节点时,只考虑到当前节点上的最佳划分特征,可能忽略了其他特征之间的相关性。
- 类别不平衡问题:当训练数据中的类别分布不平衡时,决策树容易偏向于具有更多样本的类别。
3.3改进策略
- 剪枝策略:使用剪枝技术可以限制决策树的复杂度,减少过拟合的风险。
- 集成学习:通过集成多个决策树,如随机森林和梯度提升树,可以减小单个决策树的不稳定性,提高整体模型的泛化能力。
- 特征工程:通过特征选择、降维等方法,选择合适的特征,并处理特征间的相关性,以提高决策树模型的性能。
- 数据平衡处理:对于类别不平衡的数据集,可以使用欠采样、过采样等方法来平衡各个类别的样本数量,以避免决策树偏向于多数类别。















 6058
6058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









