







第二章 机器学习之模型评估与选择
目录
一、经验误差与过拟合
误差(error):学习器的实际预测输出与样本的真实输出之间的差异
错误率 = 分类错误的样本数 样本总数 错误率= \frac {分类错误的样本数}{样本总数} 错误率=样本总数分类错误的样本数
训练误差(training error)/经验误差(empirical error):学习器在训练集上的误差。尽可能小
泛化误差(generalization):学习器在新样本上的误差
过拟合(overfitting):模型在训练数据上表现得非常好,但在测试数据或实际应用中表现不佳的现象。通常是由于学习能力过于强大
欠拟合(underfitting):对训练样本的一般性质尚未学好。
选择合适的模型(模型算法+参数配置)将一定程度上避免过拟合和欠拟合。
二、评估方法
测试集(testing error):通常,我们通过实验测试来对学习器的泛化误差进行评估并进而做出选择。需要一个测试集来测试学习器对新样本的判别能力。
测试集上的测试误差 ~ 泛化误差
对一个包含
m
m
m个样例的数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
m
,
y
m
)
}
D=\lbrace( x_1,y_1),(x_2,y_2),\ldots,(x_m,y_m)\rbrace
D={(x1,y1),(x2,y2),…,(xm,ym)}进行适当的处理,从中产生训练集
S
S
S和测试集
T
T
T。下面是几种常见的做法。
1.留出法
留出法(hold-out):直接将数据集 D D D划分为两个互斥的集合,其中一个集合作为训练集 S S S,另一个作为测试集 T T T。
- 1 给测试集的量要足够
- 2 训练集测试集划分尽量保持数据分布的一致性。比如在分类任务中至少要保持样本的类别比例相似。分层采样
- 3 一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果
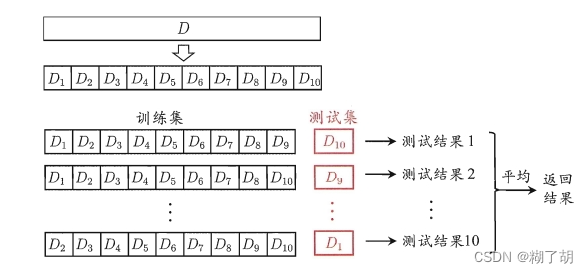
2.(k折)交叉验证法
交叉验证法:先将数据集
D
D
D划分
k
k
k个大小相似的互斥子集;然后,每次用
k
−
1
k-1
k−1个子集的并集作为训练集,余下的子集作为测试集,获得
k
k
k组训练/测试集;从而可以进行
k
k
k次训练和测试,最终返回的是
k
k
k个测试结果的均值。
留一法(Leave-One-Out,简称LOO)——交叉验证法的特例
数据集
D
D
D中包含
m
m
m个样本,令
k
=
m
k=m
k=m
优点:评估结果比较准确
缺点:在数据比较大时,计算开销大,算法调参工作量大
3.自助法
自助法(bootstrapping):给定包含
m
m
m个样本的数据集
D
D
D,采样产生数据集
D
′
D'
D′:每次随机从
D
D
D中挑选一个样本。将其拷贝放入
D
′
D'
D′,然后再将该样本返回初始数据集
D
D
D中。
这个过程重复执行
m
m
m次后,得到包含
m
m
m个样本的数据集
D
′
D'
D′,得到自主采样的结果。
D
′
D'
D′作训练集。
D
D
′
\frac{D}{D'}
D′D作测试集。
适用情况:数据集较小、难以有效划分训练/测试集
优点:对集成学习等方法有很大好处
缺点:产生的数据集改变了初始数据集的分布,会引入估计偏差。
4.调参与最终模型
调参(parameter tuning):除了要对适用学习算法进行选择,还需要对算法参数进行设定。
通常把学得模型在实际使用中遇到的数据称为测试数据,模型评估与选择中用于评估测试的数据集常称为“验证集(validation set)”。
三、性能度量
性能度量(performance measure):衡量模型泛化能力的评价标准。反映了任务需求。
给定样例集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
m
,
y
m
)
}
D=\lbrace( x_1,y_1),(x_2,y_2),\ldots,(x_m,y_m)\rbrace
D={(x1,y1),(x2,y2),…,(xm,ym)},其中
y
i
y_i
yi是示例
x
i
x_i
xi的真实标记。
均方误差(mean squared error)
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
E(f;D)=\frac1m\sum\limits_{i=1}^{m}(f(x_i)-y_i)^2
E(f;D)=m1i=1∑m(f(xi)−yi)2
更一般地,数据分布
D
D
D和概率密度函数$p(·)
E
(
f
;
D
)
=
∫
x
∼
D
(
f
(
x
)
−
y
)
2
p
(
x
)
d
x
E(f;D)= \int_{x\sim\mathcal{D}} (f(x)-y)^2p(x)dx
E(f;D)=∫x∼D(f(x)−y)2p(x)dx
1.错误率与精度
对于样例集 D D D,
错误率
=
分类错误的样本数
样本总数
错误率= \frac {分类错误的样本数}{样本总数}
错误率=样本总数分类错误的样本数
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
I
(
f
(
x
i
)
≠
y
i
)
E(f;D)=\frac1m\sum\limits_{i=1}^{m}\mathbb{I}(f(x_i)\neq{y_i})
E(f;D)=m1i=1∑mI(f(xi)=yi)
精度
=
分类正确的样本数
样本总数
精度= \frac {分类正确的样本数}{样本总数}
精度=样本总数分类正确的样本数
a
c
c
(
f
;
D
)
=
1
m
∑
i
=
1
m
I
(
f
(
x
i
)
=
y
i
)
=
1
−
E
(
f
;
D
)
acc(f;D)=\frac1m\sum\limits_{i=1}^{m}\mathbb{I}(f(x_i)={y_i}) =1-E(f;D)
acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
2.查准率、查全率与F1
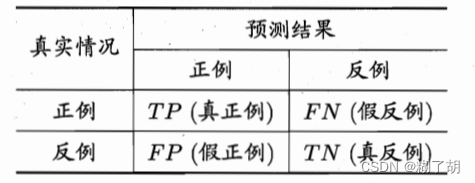
样例真实类别:真(true) / 假(false)
学习器类别:正例(positive) / 假例(negative)
分类结果混淆矩阵(confusion matrix)
查准率(precision):
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
查全率(recall): R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
P-R曲线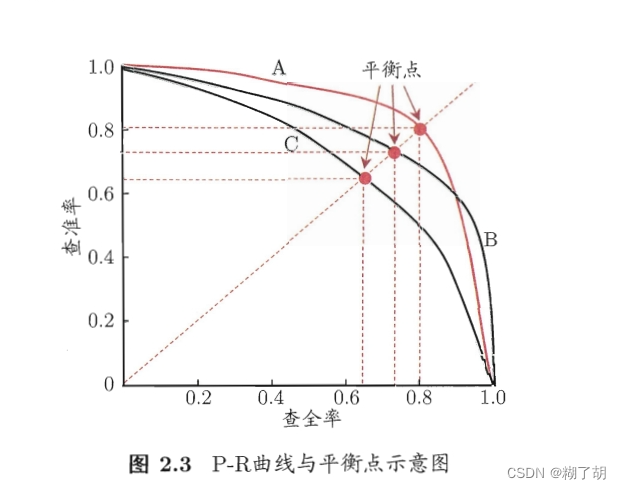
平衡点(Break-Event Point):查准率 = 查全率
F1度量: F 1 = 2 × P × R P + R = 2 × T P 样例总数 + T P − T N F1=\frac{2 \times P \times R}{P+R}=\frac{2 \times TP}{样例总数+TP-TN} F1=P+R2×P×R=样例总数+TP−TN2×TP
F1度量一般形式: F 1 = ( 1 + β 2 ) × P × R P + R F1=\frac{(1+\beta^2) \times P \times R}{P+R} F1=P+R(1+β2)×P×R
在
n
n
n个二分类混淆矩阵上综合考虑查准率和查全率。
宏查准率
:
m
a
c
r
o
−
P
=
1
n
∑
i
=
1
n
P
i
宏查准率:macro-P=\frac{1}{n}\sum\limits_{i =1}^nP_i
宏查准率:macro−P=n1i=1∑nPi
宏查全率
:
m
a
c
r
o
−
R
=
1
n
∑
i
=
1
n
R
i
宏查全率:macro-R=\frac{1}{n}\sum\limits_{i=1}^{n}R_i
宏查全率:macro−R=n1i=1∑nRi
m
a
c
r
o
−
F
1
=
2
×
m
a
c
r
o
−
P
×
m
a
c
r
o
−
R
m
a
c
r
o
−
P
+
m
a
c
r
o
−
R
macro-F1=\frac{2 \times macro-P \times macro-R }{macro-P +macro-R}
macro−F1=macro−P+macro−R2×macro−P×macro−R
3.ROC与AUC
受试者工作特征(Receiver Operating Characteristic)曲线:根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横纵坐标作图。纵轴是“真正例率”(True Positive Rate,简称TPR),横轴是“假正例率”(False Positive Rate,简称FPR)
T
R
P
=
T
P
T
P
+
F
N
TRP=\frac{TP}{TP+FN}
TRP=TP+FNTP
F
P
R
=
F
P
T
N
+
F
P
FPR=\frac {FP}{TN+FP}
FPR=TN+FPFP
学习器性能比较:比较ROC曲线下面积,即AUC(Area Under ROC Curve)
A
U
C
=
1
2
∑
i
=
1
m
−
1
(
x
i
−
1
−
x
i
)
(
y
i
+
y
i
+
1
)
=
1
−
l
r
a
n
k
AUC=\frac{1}{2} \sum \limits_{i=1}^{m-1}(x_{i-1}-x_i) (y_i+y_{i+1}) =1-l_{rank}
AUC=21i=1∑m−1(xi−1−xi)(yi+yi+1)=1−lrank
“损失”(loss)——ROC曲线之上的面积:
l
r
a
n
k
=
1
m
+
m
−
∑
x
+
∈
D
+
∑
x
−
∈
D
−
(
I
(
f
(
x
+
)
<
f
(
x
−
)
)
+
1
2
I
(
f
(
x
+
)
=
f
(
x
−
)
)
)
\mathcal{l}_{rank} =\frac{1}{m^+m^-} \sum\limits_{x^+\in{D^+}}\sum\limits_{x^-\in{D^-}}\Big(\mathbb{I}\big(f(x^+)<f(x^-)\big)+\frac{1}{2}\mathbb{I}\big(f(x^+)=f(x^-)\big)\Big)
lrank=m+m−1x+∈D+∑x−∈D−∑(I(f(x+)<f(x−))+21I(f(x+)=f(x−)))
即考虑每一对正、反例,若正例的预测值小于反例,则记一个“罚分”;
若相等,则记0.5个罚分。
4.代价敏感错误率与代价曲线
把坏瓜认成好瓜和把好瓜认成坏瓜的严重程度不一样。
以二分类任务为例,根据任务的领域知识设定一个“代价矩阵”。
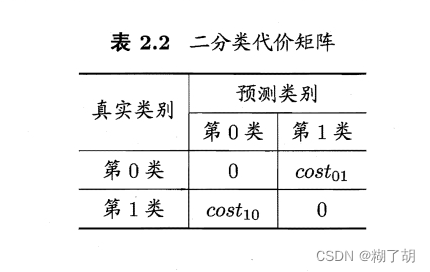
其中,
c
o
s
t
i
j
cost_{ij}
costij表示将第
i
i
i类样本预测为第
j
j
j类样本的代价。
一般来说,
c
o
s
t
i
j
=
0
cost_{ij}=0
costij=0
若将第0类判别为第1类所造成的损失更大,则
c
o
s
t
01
>
c
o
s
t
10
cost_{01}>cost_{10}
cost01>cost10,损失程度相差越大,
c
o
s
t
01
与
c
o
s
t
10
cost_{01}与 cost_{10}
cost01与cost10值的差别越大。
规范化(normalization):是将不同变化范围的值映射到相同的固定范围中,常见的是[0,1],此时亦称 “归一化” 。
四、比较检验
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据。基于假设检验结果我们可以推断出,若在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及这个结论的把握有多大。
未完待续。。。















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









