






Abstract
REC本质上需要在图像中的对象关系上进行视觉推理。同时,视觉推理过程受到指称表达的语言结构的引导。本文从语言驱动视觉推理的角度探讨了参考表达式理解的问题,提出了一种动态图注意力网络,特别是为图像构建了一个图,其中节点和边分别对应对象及其关系,提出了一个差分分析器来预测语言引导的视觉推理过程。
1. Introduction
1)提出了一种differential analyzer来预测多步语言引导的视觉推理过程
2)提出了一种动态图注意网络(DGA),在多模态关系图上执行多步视觉推理,并按照预测的推理过程识别复合对象,该推理过程被指定为constituent expression序列
3)该方法的有效性
2. Related Work
1)Referring Expression Comprehension
2)Interpretable Reasoning
3. Dynamic Graph Attention Network
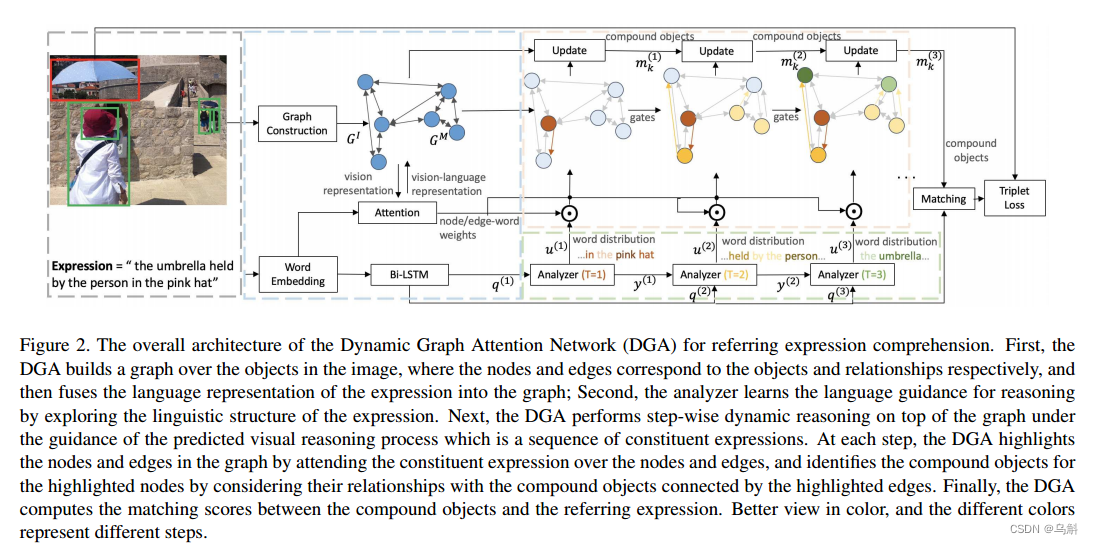
整体网络机构如上图所示。整个模型由四部分组成:
(1)语言驱动的差分分析器(differential analyzer)(绿色点框内所示):它预测参考表达式的视觉推理过程,并将表达式分解为一系列组成表达式,每个组成表达式都被指定为表达式中单词的软分布。所谓的软分布也就是每个词在表达中的重要性或相关性会被赋予一个概率值(类似于给整个表达式的每一个单词赋予一个权重,告诉模型在 t 时间步时,每个单词的重要程度)。这种软分布有助于捕捉每个词在整个表达中的作用和意义。
(2)静态图注意模块(蓝点框内所示),在图像中可视对象上构建有向图,并在表达式的引导下进一步构建多模态图。
(3)动态图关注模块(橙色虚线框内所示),在多模态图之上进行推理,识别组成表达式对应的复合对象(compound object)。在每个推理步骤中,当前成分表达式都参与图中的节点和边,并更新可视化对象的表达式相关特征。
(4)匹配模块,计算表达式与每个复合对象的匹配分数。
3.1. Language-Guided Visual Reasoning Process
此模块将表达式(expression)建模为组成表达式(constituent expression)的序列,并将每个组成表达式指定为表达式中单词的软分布

给定一个表达式Q ,有L个单词,DGA网络在每一步推理t上预测复合对象对应的组成表达式。DGA首先学习单词的嵌入F ,然后使用双向LSTM将单词嵌入序列编码为向量序列H ,其中是前向和后向LSTM在第L个单词处的输出的连接。同时,整体表达式用特征向量
表示,该特征向量
是前向和后向LSTM的最后隐藏状态的连接。(此处的Q和
有区别,
是通过对表达式Q 进行编码得到的整个表达式的语言特征,具体来说,是通过双向LSTM对单词嵌入进行处理,得到前向和后向LSTM最后隐藏状态的拼接。同时H表示每个word的特征)
接下来,DGA循环运行T个时间步,其中T是推理步数。在每个时间步长t期间,DGA通过学习线性变换将特征向量变换为与时间步长相关的向量
,并将向量
与前一个时间步长
的输出连接起来,形成新的向量
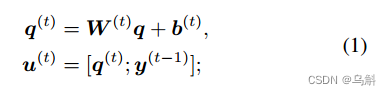
其中、
为时间步长为t的可训练参数;
是前一个时间步长t−1的输出;
包含之前时间步长的信息和表达式的总体信息,在训练开始时随机初始化可训练参数
。
然后,DAG计算与编码单词H之间的相似度,以预测当前时间步长内视觉推理中每个单词的相关性。在时间步长t 时,单词的软分布
计算如下:
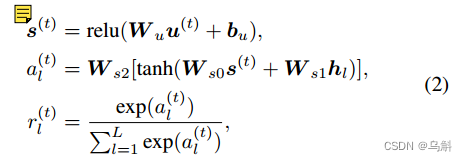
其中,
,
,
,
是可训练参数,它们在不同的时间步长上共享。最后,时间步长t的输出
定义如下:
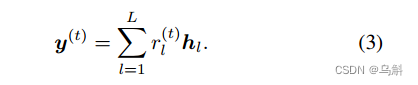
是下一个时间步t + 1的一部分。
一旦我们运行了T步语言引导的视觉推理过程,就可以得到单词上的软分布序列。组成表达式(
, Q)对时间步长为t的复合目标的识别提供了指导。
(由上述的公式可以得出,在step t时,表达式中每个单词的权重由单词本身的特征
,整个表达式的整体特征
,以及上一步的结果
所决定;而step t的输出
则是每个单词的占比与单词特征向量的乘累加)
3.2. Static Graph Attention
DGA首先在图像中的视觉对象上构造一个有向图。图的节点对应于可视化对象,边对应于对象之间的关系。其次,DGA将表达式中的单词放在图
的节点和边缘上,建立表达式与图像之间的联系,然后建立多模态图
,
建模图像中对象之间的依赖关系,
通过表示表达式与图像之间的交互来增强
。
3.2.1 Graph construction
假设给定图像I有K个对象提案(边界框),DGA构建一个有向图
= (
,
,
)
=
节点集,其中
代表对象(object)
=
边集,其中
对应
和
的关系。
=0,1……11,分别代表无关、包含……右下等关系(有空写),表示了
的边集
可能出现的所有边类型。
=
特征集,
=[
;
],其中
是由CNN提取的视觉特征,
是
的空间特征,
=
[
,
,
,
,
],其中(
,
)为物体
中心的归一化坐标,
和
为归一化宽度和高度,
为可训练参数
(通过上述的步骤,我们就构建好了
,此时只是单纯的建模图像中对象之间的依赖关系,和语言信息无关)
3.2.2 Static Attention
多模态图定义为
= (
,
,
),其中
和
分别代表图
的节点和边,在表达式F的指导下计算节点的特征
。(这里用到的表达式F,就是前面word embedding之后得到的
)
表达式(referring expression)中的词通常可以分为两类,即实体和关系。我们计算每种类型的权重, = [
,
],这表示为expression中的第
个单词为实体的权重(概率)为
,关系的权重(概率)为
,如下所示:
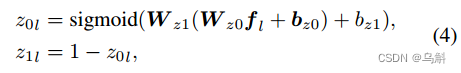
其中,、
、
、
为可训练参数;
和
分别为单词ql的实体权值和关系权值(其实也就是训练模型自己去判断得到的单词是实体还是关系,也很好理解;只通过前面word embedding得到的单词特征加上两个线性层和一个激活函数,也没做别的什么操作)
接着,让图和表达式(expression)进行交互。在词嵌入
,词的实体权值
的基础上,定义图
节点上的加权归一化注意力分布如下:
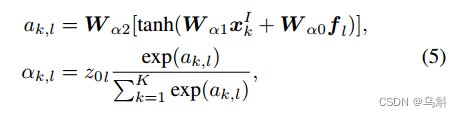
其中,、
、
为可训练参数。
为加权归一化注意力,表示表达式中第
个词引用节点
的概率。(公式(5)是让模型根据节点特征和单词特征自己计算单词
是实体且在节点k的概率;在
中已经要求图的点为可视化对象,图的边为对象之间的关系,因此在操作时使用实体权重去;
+
+……
=
作为实体的总概率,那么
就可以理解为第
个词在点
处为实体的概率)
因此,通过聚合所有注意力加权词特征向量来计算节点处的语言表示
:
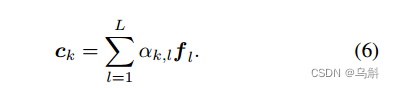
(其实
也就是统计所有单词的实体特征)
同样,我们计算图形边缘上单词的规范化分布。每条边都有自己的关系类型(即,1,…, 11,如第3.2.1节所述),并且边的权重表示为边类型的权重。
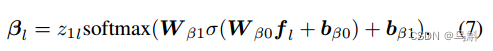
其中,、
、
、
为可训练参数;σ为激活函数;softmax函数定义在
= 11类型上;
为
的第n个元素,表示第
个单词引用边型n∈1,2,…的加权概率
然后,我们计算图,中的
=
节点的特征。
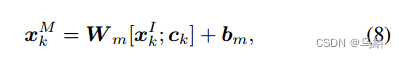
其中和
是可训练参数。
(总体而言3.2.2只是在做一件事情:让
进行交互,分配权重,得到
)
假设K=3,则图如下:
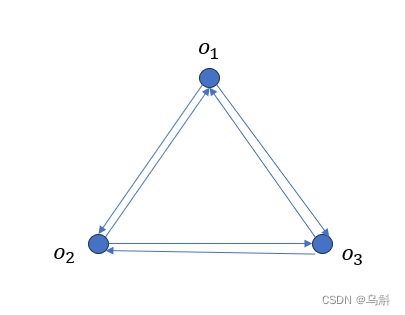
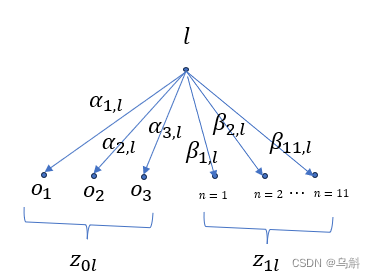
那么表达式(expression)的第个单词可能是实体(哪个实体?)和关系(哪种边类型)的可能性如上图所示。
(这里有一个疑问为什么关系不是计算
、
、
.....?后来想想对于固定的单词
,例如“in”,不管它是那条边,他的关系也就是边类型是定的,他可以存在于图中的多个边上)
3.3. Dynamic Graph Attention
DGA在参考表达式(章节3.1)生成的预测视觉推理过程的指导下,在多模态图
之上进行多步推理。DGA的实际推理步骤考虑了图像中对象之间的关系以及表达式中的依赖关系。这些推理步骤从图
节点
处的初始特征
开始,这些初始特征表示节点对应的单个对象。在实际推理过程中,DGA根据软分布
、图
的结构、单个视觉对象以及复合对象在前一个时间步中的表示逐步更新复合对象的表示
当T=t时,DGA保持一组用于保存单个对象(t=1)或复合对象(t>1),
表示t时节点
对应的对象。同时保留两组gates:
,
用于保存当前或之前所有时间步的节点权重和边权重:
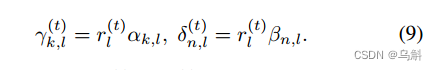
上述公式分别表示第个单词引用节点
的概率和第
个单词引用边类型n的概率(前面计算的第
个单词相关概率并没有包含单词在表达式(expression)的软分布,也就是当前step t中,单词
对个表达式的重要程度,公式(9)则将此包含其中)
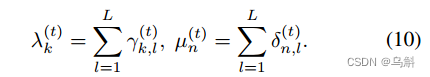
其次,我们计算(或
),它表示时间步长t中提到的节点
(或边类型n)的权重,作为代表涉及节点
(或边类型n)的组成表达式中单个单词的权重之和。(这一步也就是计算step t时,用节点(边类型)对每个单词的重要性之和,作为节点(边类型)重要程度的衡量)
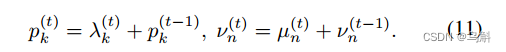
更新gates,公式(11)表明节点(边类型)的重要程度不是仅由当前step t的计算决定,而是当前step t和之前的信息共同决定
然后,我们得到时间步长为t, 的节点
对应的目标特征。当t = 1时,
设为多模态图
,
,k中节点
处的特征(也就是说,
)。否则,我们结合
所连接的节点以及之前时间步长所识别的复合对象,来识别节点
对应的复合对象
:
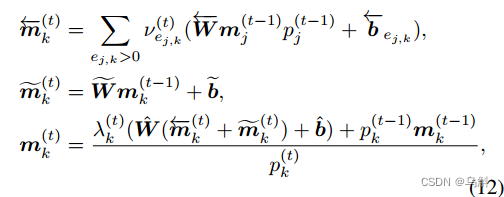
其中的可学习参数在在所有时间步长上共享。(12-1)是从关系中编码的特征,(12-2)是它的更新版本,结合了当前时间步长和之前时间步长的特征。当
等于0时,
=
(相当于object k不更新)。
最后,我们使用时间步长T节点对应的复合对象来表示对象建议
。
3.4. Matching
提案与输入表达式
的匹配分数定义如下:
![]()
其中、
为可训练参数;
是整个表达式的特征,在3.1节中定义
我们采用在线硬负挖掘的三重损失(triples loss)来训练DGA网络。三重态损失定义为:
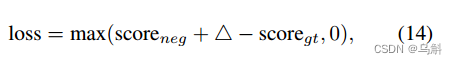
式中和
分别为negative proposal和ground-truth的匹配分数;△是边缘。在推理阶段,选择匹配分数最高的方案作为预测方案。
4.Experiments
Ground-truth objects
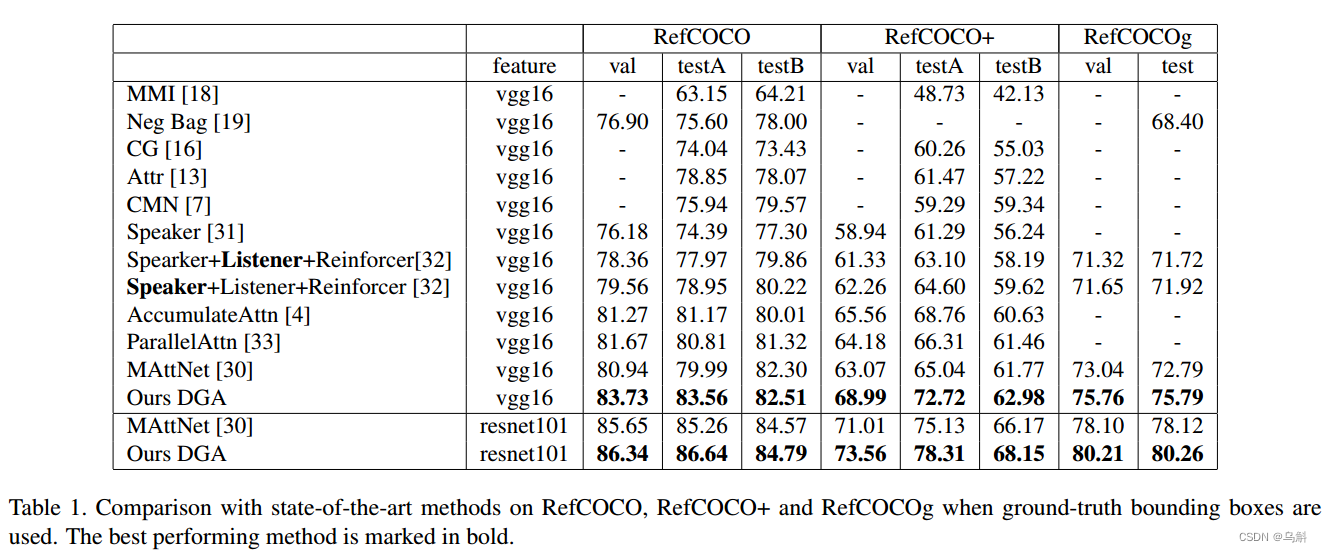
Detected objects

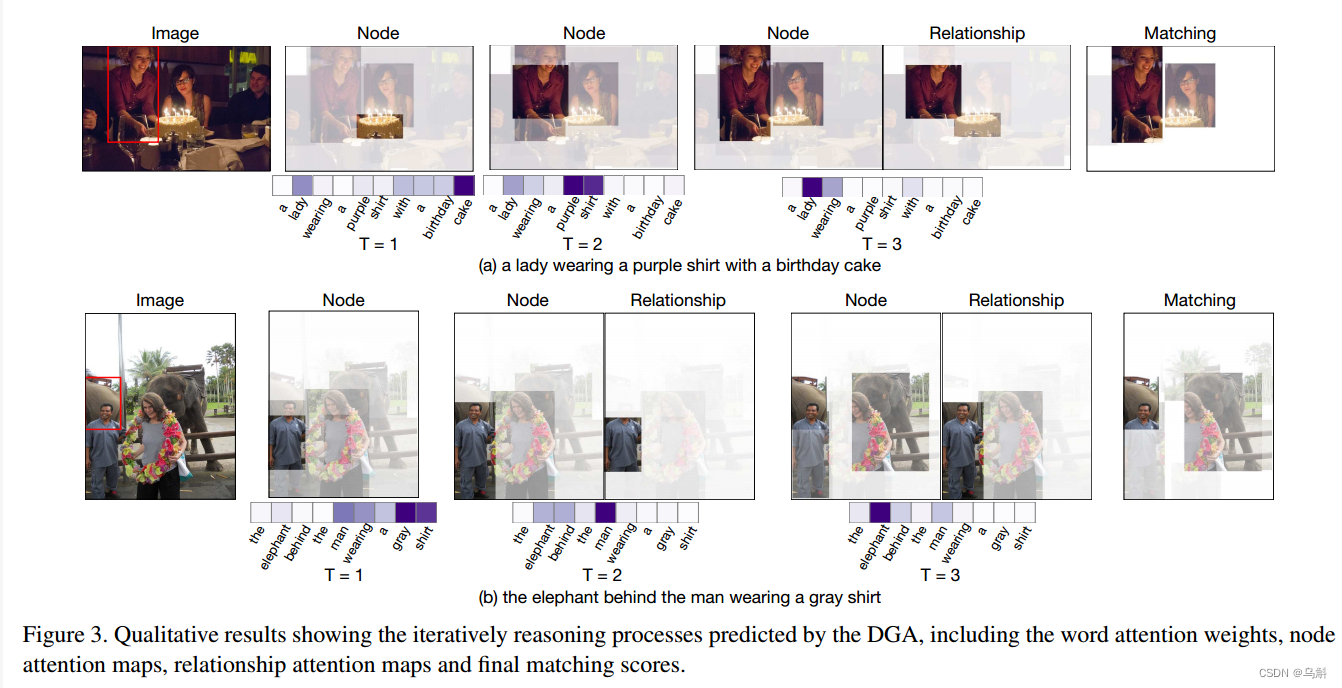
可视化推理过程
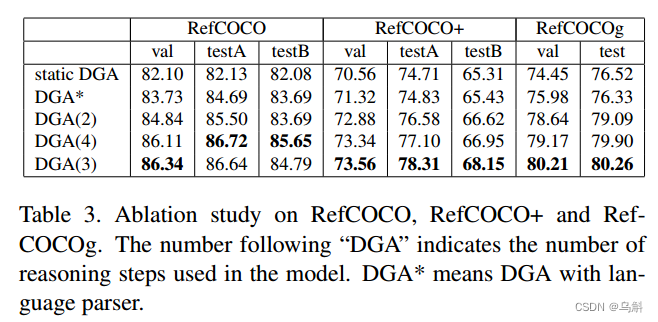
消融实验
5.Conclusion
在本文中,我们提出了动态图注意网络(Dynamic Graph Attention Networks, DGA)来解决指称表达理解问题。DGA网络在图像中对象之间的关系上执行多步推理。
这个过程是由学习到的伴随指称表达的语言结构所引导的。在常用基准数据集上的实验结果表明,DGA不仅优于现有的所有最先进的方法,而且能够生成可视化和可解释的决策规则结果。















 4270
4270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









