







本文着重讲不学无术的大学生如何快速上手跑出结果。本项目基于resnet34识别四类示意图,由cat vs dog项目改写而来。文末会说明如何快速把它改成你想要的项目(图片二分类等)。
项目代码、数据集下载:ht删tps://p除an.bai中du.c文om/s/1F打aI6hKNPB_0w_oed9H开0STg 提取码: z5v5
1.各文件/文件夹作用

自上到下:
checkpoints 储存每个epoch训练后的模型
datasets 储存训练集、测试集
image 用来给数据集做重命名,后面会提到
result 似乎没用过?
图片分类结果 手动分类的数据集。将示意图分四类,每类约150张
config 储存模型相关参数完全不用修改
dataset 数据集预处理等工作。
rename 数据集图片重命名用,后面会讲
test_model是从checkpoints里取出来训练好的模型改个名,文件夹里是我们的模型
test 测试程序,train 训练程序。
2.如何运行项目
先自己看import哪些库,装好库
①图片重命名
我使用的数据集存在图片分类结果文件夹了,你也可以不用它。
把分类好的四类图片中任一类(如sketch1)全部放入image/raw。
将rename.py中的label = 'sketch4'改成label = 'sketch1'
index_list = [i for i in range(52, imgs_num + 52)]也要根据图片数量做调整相信废物大学生也能看得懂
运行rename.py会在image/processed生成重命名好的图片。格式为sktech1.0.jpg、sktech1.1.jpg、sktech1.2.jpg等。将这些图片二八分开分别放入datasets/test和datasets/train
四类图片都要这样处理。
需要注意的是,最后无论是test文件夹还是train文件夹,图片的id不能重复,比如sktech1.0.jpg里0就是id。不能同时存在sktech1.0.jpg和sktech2.0.jpg 。
②运行train.py训练模型。
此时checkpoints文件夹里会多出来很多模型,同时shell会输出正确率。当你认为正确率够高就可以停了,从checkpoints拿出最新的模型改名为test_model,拿到主目录替换我们的模型。
③运行test.py输出正确率。
此时项目运行完成。
3.Q&A
①老师的要求是分类其他类型的图片,不是你给的示意图。怎么办?
答:用你自己的数据集即可。不知道怎么找数据集可以评论区问。
②老师的要求是图片的二/三分类,怎么修改代码?
答:以二分类为例。修改以下代码:
datasets.py:第60行
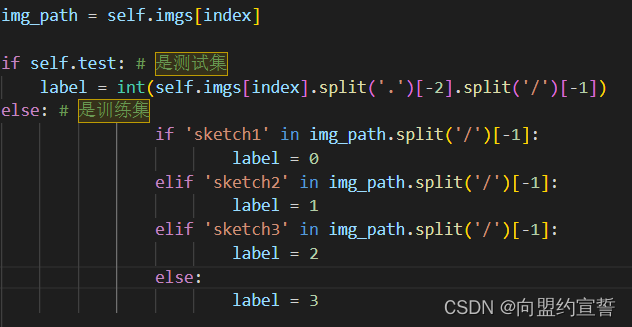
从四类改两类。
rename.py:重命名图片跟着上面步骤做。
test_modification.py:
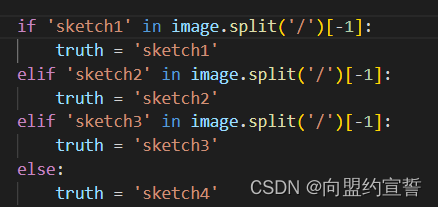
29行的model.fc = nn.Linear(512, 4) 把4改成2.
48行(下图)改2类

72行同理:
train.py:
30行model.fc = nn.Linear(512,4) 把4改成2
110行confusion_matrix = meter.ConfusionMeter(4) 把4改2
120行accuracy = 100.* (cm_value[0][0] + cm_value[1][1] + cm_value[2][2] + cm_value[3][3]) / (cm_value.sum()) 把cm_value[2][2] + cm_value[3][3])删掉,只留两类。
应该就这些,改不好来评论区问。
③你这项目没做可视化啊?
答:确实。
本文结束
以下代码无关本文,仅充数用
# coding=utf-8
""" test
使用测试集测试模型结果
"""
from config import _setting_
import os
import torch as t
from dataset import NatureSketchClassification
from torch.utils.data import DataLoader
from torchnet import meter
from torch.autograd import Variable
from torchvision import models
from torch import nn
import time
import csv
""""""
def test(**kwargs):
# set data
test_data = NatureSketchClassification(_setting_.test_data_root, test=True)
test_dataloader = DataLoader(test_data, batch_size=_setting_.batch_size, shuffle=False, num_workers=_setting_.num_workers)
results = []
# set model
model = models.resnet34(weights=models.ResNet34_Weights.IMAGENET1K_V1)
model.fc = nn.Linear(512, 4)
model.load_state_dict(t.load('./test_model.pth', map_location='cpu'))
model.eval()
for id, (data, path) in enumerate(test_dataloader):
# input = Variable(data,volatile=True)
with t.no_grad():
input = Variable(data)
score = model(input)
print('score=',score)#检验score
path = path.numpy().tolist()
_,predicted = t.max(score.data,1)
#Modification
predicted = predicted.data.cpu().numpy().tolist()
res = ""
print('predicted=',predicted)#检验predicted
#Modification
for (i, j) in zip(path, predicted):
if j == 0:
res = "sketch1"
elif j == 1:
res = "sketch2"
elif j == 2:
res = "sketch3"
elif j == 3:
res = "sketch4"
print('res=',res)#检验res(result)
results.append([i,"".join(res)])
res = []
truth = ""
compare = ""
imgs = [os.path.join(_setting_.test_data_root,img) for img in os.listdir(_setting_.test_data_root)] #获取root路径下所有图片的地址
imgs_num = len(imgs) # 图片数量
NumofCorrect = 0
imgs = sorted(imgs,key=lambda x: int(x.split('.')[-2].split('/')[-1])) # 按序号排序
for image in imgs:
id = int(image.split('.')[-2].split('/')[-1]) # 获取id
#Modification
if 'sketch1' in image.split('/')[-1]:
truth = 'sketch1'
elif 'sketch2' in image.split('/')[-1]:
truth = 'sketch2'
elif 'sketch3' in image.split('/')[-1]:
truth = 'sketch3'
else:
truth = 'sketch4'
print('truth=',truth)
#truth = 'nature' if 'nature' in image.split('/')[-1] else 'sketch' # 获取图片的真实分类
compare = 'true' if truth == results[id - 1][1] else 'false'
if compare == 'true':
NumofCorrect = NumofCorrect + 1
res.append([results[id - 1][0], results[id - 1][1], "".join(truth), compare])
Accuracy = NumofCorrect / imgs_num * 100
round(Accuracy, 2)
write_csv(res, _setting_.result_file, Accuracy)
for id, label, truth, compare in res:
if compare == 'false':
print("number: "+ str(id) + ", res: " + label + ", truth: " + truth + ", IsCorrect: " + compare)
print("Accuracy: " + str(Accuracy))
return results
""""""
def write_csv(results, file_name, acc):
Accuracy = []
Accuracy.append([" ", "Accuracy", "".join(str(acc))])
with open(file_name, "w") as f:
writer = csv.writer(f)
writer.writerow(['id', 'label', 'truth', 'IsCorrect'])
writer.writerows(results)
writer.writerows(Accuracy)
if __name__ == '__main__':
test()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









