







简介:个人爬虫学习分享,如有错误,欢迎批评指正。
爬虫小案例1:爬取网页图
打开浏览器,搜索任意网络图像,如下红圈图像,
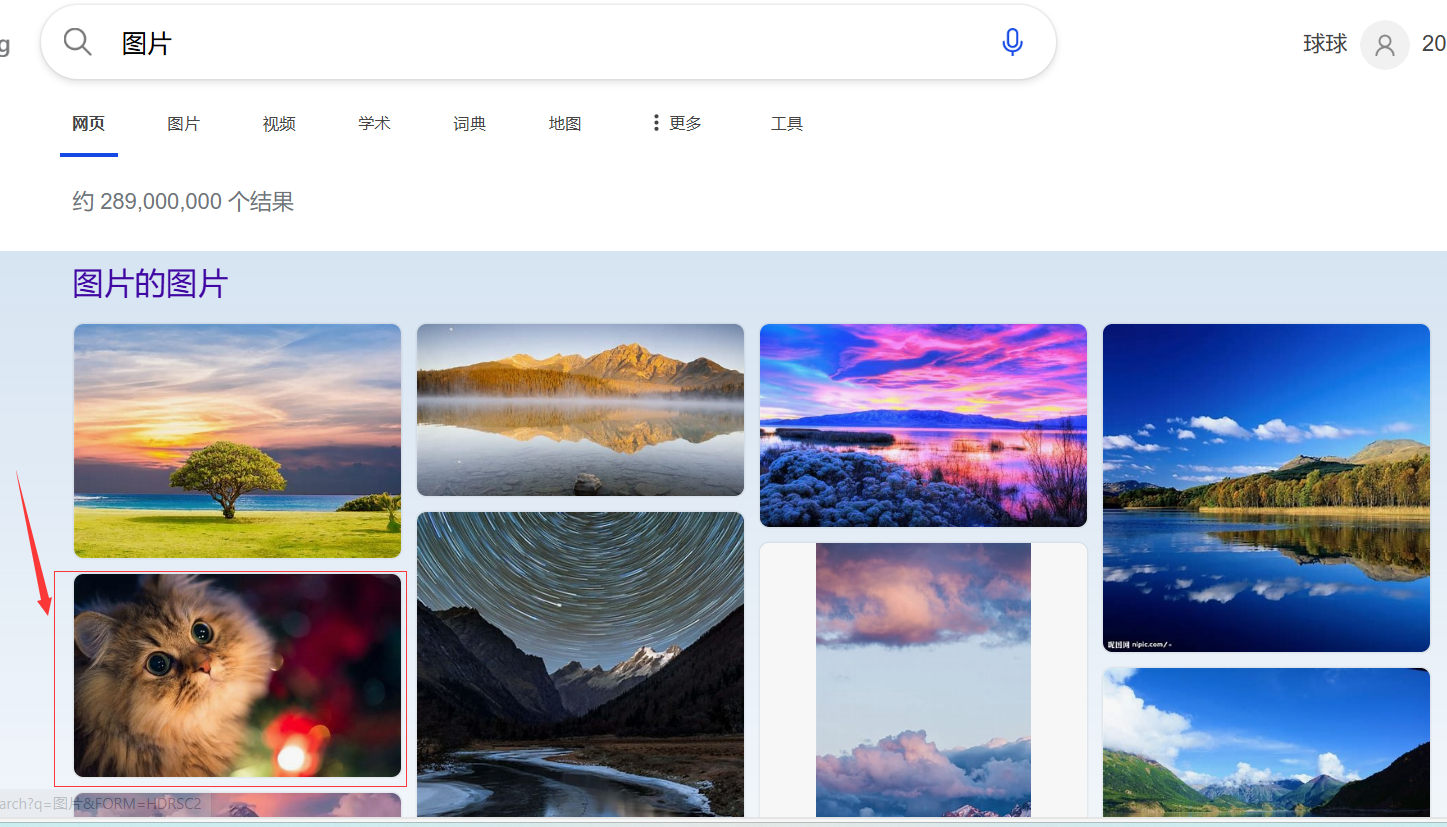
单击图像,后再点击鼠标右键,选复制图像链接,该链接就是这个图像的url地址。
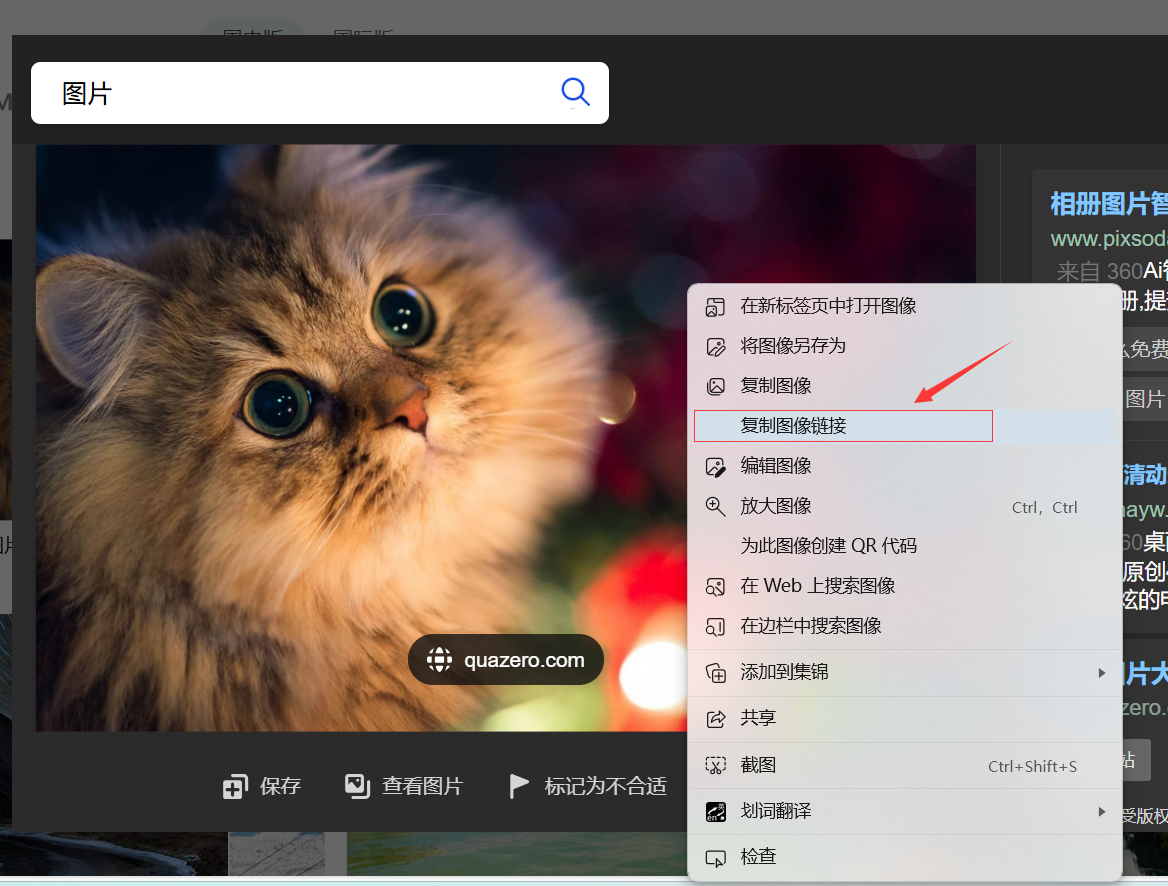
运行如下代码,将上面复制的图像链接(url)代替下面代码中url=' '的那串字符串,即可爬下该图像,不同图像如上一样,更换url地址即可。
import requests
# 网络图像的URL地址
url = 'https://ts1.cn.mm.bing.net/th/id/R-C.66d7b796377883a92aad65b283ef1f84?rik=sQ%2fKoYAcr%2bOwsw&riu=http%3a%2f%2fwww.quazero.com%2fuploads%2fallimg%2f140305%2f1-140305131415.jpg&ehk=Hxl%2fQ9pbEiuuybrGWTEPJOhvrFK9C3vyCcWicooXfNE%3d&risl=&pid=ImgRaw&r=0'
# 加载图像
data = requests.get(url).content
print(data)
# 保存图像为JPG格式
with open('1.jpg','wb') as f :
f.write(data)
爬虫小案例2:爬取百度贴吧图像
首先进入我们的目标网页:“https://tieba.baidu.com/p/5475267611”。
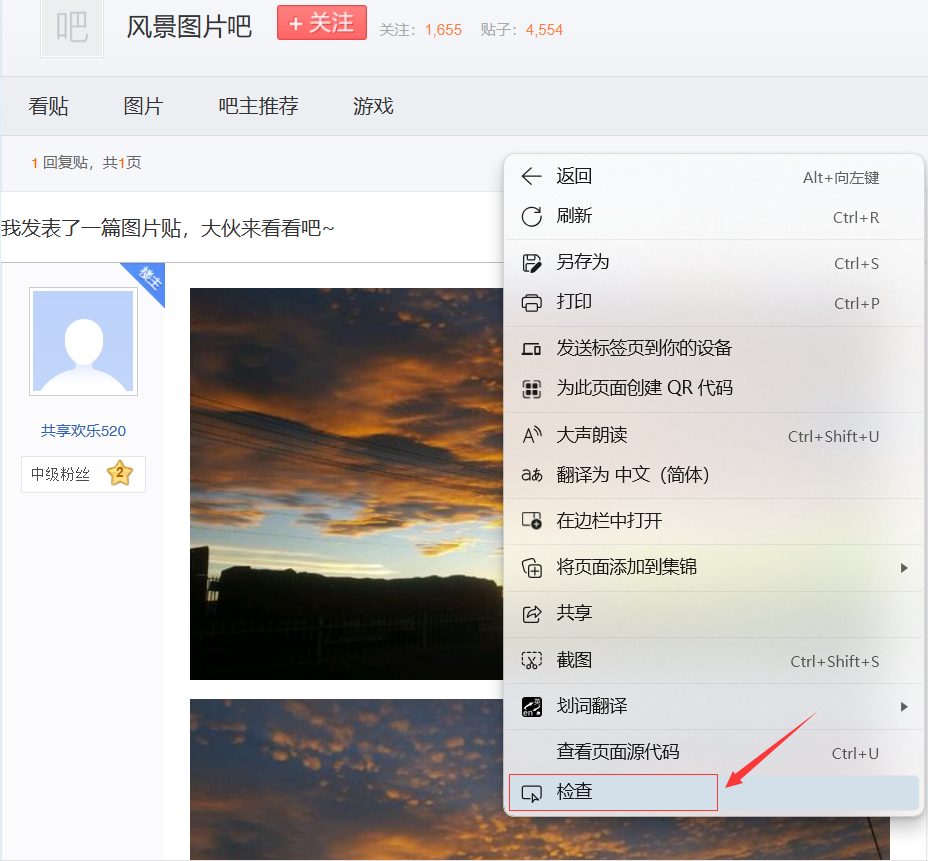
因为贴吧里面不只有图像本身,还有一些其他内容,因此爬取会复杂些许。首先点击鼠标右键,选择最后一项检查。
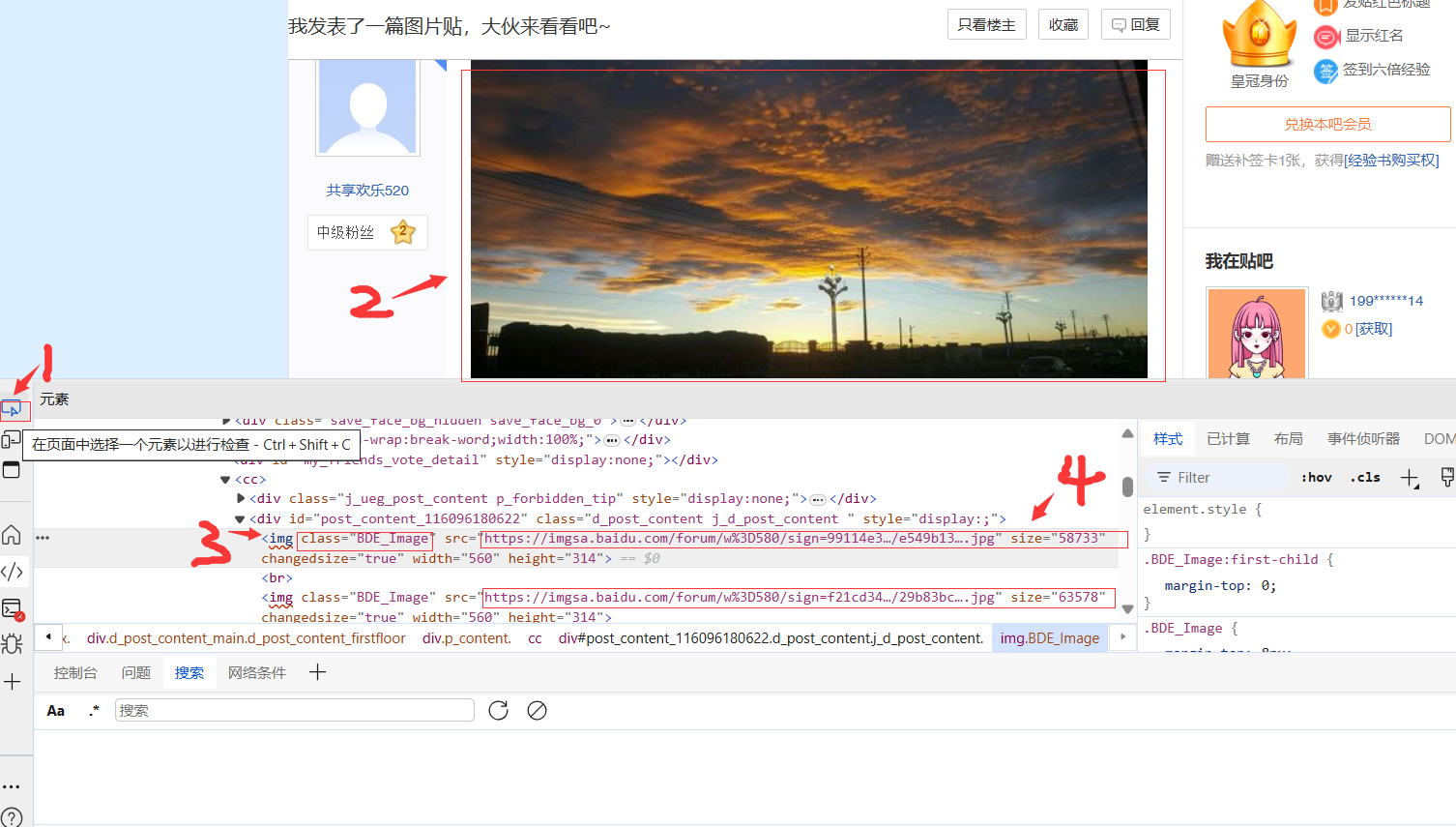
点击检查后得到如上图像,点击图中1后可以选择一个元素开始检查,简而言之,就是你把鼠标放在网页的那个位置,下面源代码也定位到相应的位置。因此,当我把鼠标放在图中2时,即我们的目标图像,下面的源代码也定位到了该图像所在位置,其中4就是目标图像的url地址,3是我们需要用到的定位关键词。具体任务如下,首先通过网页url获取到网页数据,再通过lxml对源代码数据进行解析,通过定位关键词找到目标图像的url,再通过迭代每一个图像的url将每一个图像数据取出来,单独保存为jpg格式。完整代码如下:
"""百度贴吧图像下载"""
import requests
from lxml import etree
index_url = 'https://tieba.baidu.com/p/5475267611'
# 通过requests拿到网页的源代码数据
response = requests.get(index_url).text
# 通过lxml对源代码数据进行解析,拿到图片的url地址
selector = etree.HTML(response)
image_urls = selector.xpath('//img[@class="BDE_Image"]/@src')
# 其中'//img[@class="BDE_Image"]/@src'是我们通过网页源代码找到的定位关键词
offset = 0
# 依次对图像地址发送网络请求
for image_url in image_urls:
# print(image_url)
image_content = requests.get(image_url).content
# 把图像的原始内容写入图像文件
with open('{}.jpg'.format(offset), 'wb') as f:
f.write(image_content)
offset = offset + 1
结~~~

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









