






摘要:尽管视频大型多模态模型(video-LMMs)取得了显著进展,但现有模型在长视频中实现有效的时间定位仍然是一个挑战。为了克服这一局限性,我们提出了时间偏好优化(Temporal Preference Optimization, TPO),这是一种新颖的后训练框架,旨在通过偏好学习增强视频大型多模态模型的时间定位能力。TPO采用自训练方法,利用在两个粒度上精心策划的偏好数据集,使模型能够区分定位准确和不太准确的时间响应:局部时间定位,专注于特定的视频片段;以及全面时间定位,捕捉整个视频序列中扩展的时间依赖关系。通过在这些偏好数据集上进行优化,TPO显著提升了时间理解能力,同时减少了对人工标注数据的依赖。在LongVideoBench、MLVU和Video-MME三个长视频理解基准数据集上的大量实验表明,TPO在两种最先进的视频大型多模态模型上均表现出有效性。值得注意的是,LLaVA-Video-TPO在Video-MME基准上确立了其作为领先7B模型的地位,凸显了TPO作为推进长视频理解中时间推理的可扩展且高效解决方案的潜力。项目页面:https://ruili33.github.io/tpo_website。Huggingface链接:Paper page , 论文链接:2501.13919
1. 引言
近年来,视频大型多模态模型(video-LMMs)在通用视频理解方面取得了显著进展。然而,尽管这些模型在图像和空间推理方面表现出色,但它们在建模视频中的时间依赖关系方面仍面临挑战,特别是对于长视频。现有方法通常遵循两阶段训练范式:首先在大规模多模态数据集上进行预训练,然后在经过精心策划的视频-文本指令调优数据集上进行监督微调(SFT)。然而,这些方法在时间建模方面存在显著局限,主要依赖于弱对齐的视频内容和指令调优对,缺乏对时间定位能力的明确优化。因此,这些方法在需要细粒度或长上下文时间定位的任务中表现不佳。
为了解决这一问题,本文提出了时间偏好优化(Temporal Preference Optimization, TPO),一种新颖的后训练框架,旨在通过偏好学习增强视频大型多模态模型的时间定位能力。TPO采用自训练方法,利用精心策划的偏好数据集,在局部和全面两个粒度上区分定位准确和不太准确的时间响应,从而显著提升模型的时间理解能力。
2. 相关工作
2.1 视频大型多模态模型
视频大型多模态模型通常结合大型语言模型(LLM)、视觉编码器和多模态投影器,以处理视频和文本输入。近年来,多种视频大型多模态模型被开发出来,如LLaVA、Video-LLaVA等,它们在视频理解方面表现出色。然而,这些模型在时间推理方面仍有待提升,特别是在长视频理解中。
2.2 时间定位
时间定位是视频理解中的一个重要任务,涉及在视频中找到与查询相关的时间段。现有方法包括密集视频标注、高亮检测和视频时间定位等。然而,这些方法在长视频理解中面临挑战,因为它们往往难以捕捉视频中的复杂时间依赖关系。
2.3 偏好学习
偏好学习是一种通过建模人类偏好来对齐模型行为与用户期望的方法。在大型语言模型和图像大型多模态模型中,偏好学习通常涉及收集人类对模型生成输出的反馈,并学习一个预测哪个输出更受欢迎的函数。直接偏好优化(DPO)是一种将人类偏好数据直接集成到模型参数优化中的方法,它在偏好学习中表现出色。
2.4 自训练
自训练是一种利用模型自身生成的数据来改进模型性能的方法。在大型多模态模型中,自训练已被用于增强模型的视觉和推理能力。通过自训练方法,模型可以在没有大量人工标注数据的情况下,通过利用自身生成的数据来不断改进。
3. 时间偏好优化(TPO)
3.1 概述
TPO是一种通过偏好学习增强视频大型多模态模型时间定位能力的后训练框架。它采用自训练方法,利用在两个粒度上精心策划的偏好数据集来优化模型。这些偏好数据集包括局部时间定位和全面时间定位两种类型,分别关注视频中的特定片段和整个视频序列中的扩展时间依赖关系。
3.2 偏好数据集策划
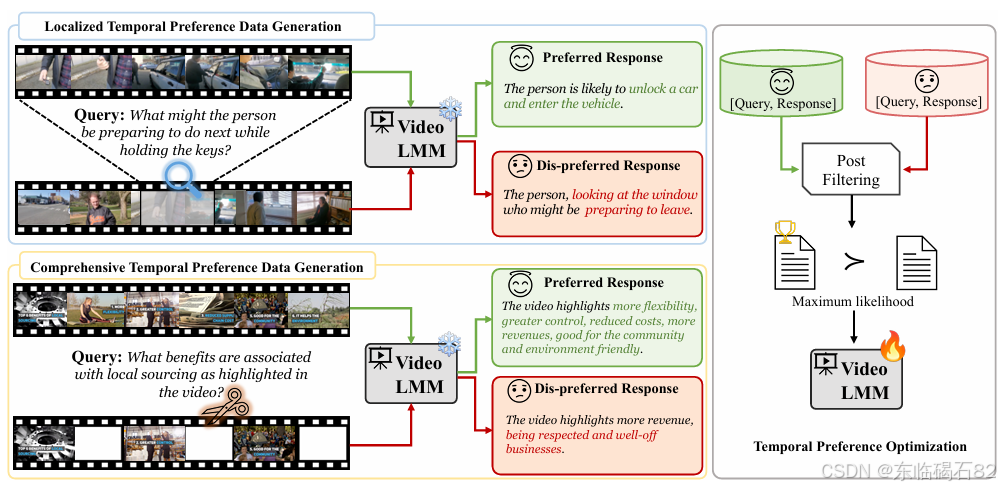
3.2.1 局部时间定位
在局部时间定位中,查询被设计为关注视频中的特定片段,而偏好响应则基于该片段生成。为了生成这些查询和响应,TPO首先从一个完整视频中采样一个子片段,然后使用图像-语言模型(如CogVLM2)为子片段中的帧生成字幕。接下来,这些字幕被用作生成针对该子片段的定制问题的基础。为了确保问题的多样性和相关性,TPO使用大型语言模型(如GPT-4o-mini)根据生成的字幕和问题生成提示,从而生成一系列候选问题。
偏好响应是通过将查询与用于策划查询的相同视频片段一起提供给模型来生成的。由于视频片段简短且直接相关于查询,模型更有可能生成高质量、时间定位准确的响应。相反,不偏好响应是通过从视频中裁剪掉与查询相关的子片段,并将剩余部分与查询一起提供给模型来生成的。这种设置模拟了模型完全错过相关内容的极端情况,从而导致模型产生时间推理错误的响应。
3.2.2 全面时间定位
在全面时间定位中,查询被设计为捕捉视频中的全面时间关系。为了生成这些查询,TPO使用预训练的图像-语言模型为从整个视频中稀疏采样的帧生成字幕,并将这些字幕输入到大型语言模型中生成查询。偏好响应是通过将用于查询生成的相同采样帧输入到视频大型多模态模型中生成的,从而确保模型能够识别出重要的关键帧并在整个时间序列上进行推理。
不偏好响应是通过将视频分成子片段并均匀丢弃特定子片段来创建的,从而生成一个信息不完整的视频版本。然后,这个截断的视频与全面查询一起提供给模型以生成不偏好响应。由于模型缺乏回答查询所需的全部相关信息,因此它往往会产生基于部分内容的次优响应。
3.3 偏好数据后过滤
在生成查询和偏好数据对后,可能存在一些不正确的对,如不偏好响应优于或等于偏好响应,或偏好响应与给定查询不相关。为了解决这个问题,TPO实现了一个后过滤管道,使用大型语言模型(如GPT-4o-mini)来过滤掉这些不正确的对。通过消除可能引入噪声的角落案例,后过滤步骤提高了偏好数据集的质量,从而支持更优化的过程。
3.4 训练目标
生成的偏好数据集随后被用于通过直接偏好优化(DPO)来优化视频大型多模态模型的时间偏好。DPO损失函数旨在驱动模型为偏好输出分配更高的概率,同时防止模型偏离其预训练分布太多。为了更好地将模型与偏好响应对齐,TPO还将监督微调目标合并到DPO训练框架中。这个组合目标由超参数α控制,允许模型在偏好优化和保持预训练知识之间取得平衡。
4. 实验
4.1 实验设置
为了评估TPO的有效性,本文在三个广泛认可的多模态视频理解基准数据集上进行了实验:LongVideoBench、MLVU和Video-MME。这些基准数据集特别关注长视频理解,涵盖了从11秒到1小时不等的视频长度。实验使用了两种最先进的视频大型多模态模型:LongVA-7B和LLaVA-Video-7B。
4.2 结果
4.2.1 与基线方法的比较
TPO与三种基线方法进行了比较:SFT Self、SFT LLM和Hound-DPO。实验结果表明,TPO在所有三个基准数据集上都显著优于基线方法。特别是在LongVideoBench和MLVU数据集上,TPO分别实现了2.9%和3.1%的性能提升。在Video-MME数据集上,尽管在短视频子集上表现略逊于SFT方法,但TPO在长视频和平均性能上均表现出色。
4.2.2 与最先进模型的比较
与当前最先进的视频大型多模态模型相比,TPO也表现出色。在Video-MME基准上,LLaVA-Video-TPO确立了其作为领先7B模型的地位,超越了包括NVILA在内的多个更大规模的模型。这些结果表明,TPO作为推进长视频理解中时间推理的可扩展且高效解决方案的潜力。
4.3 消融研究
4.3.1 不同输入帧数量的性能
实验结果表明,随着输入帧数的增加,LongVA模型的性能开始下降,而LongVA-TPO模型则持续受益。这表明LongVA-TPO模型在处理扩展输入和定位长序列中的相关信息方面更加稳健。
4.3.2 数据集大小的影响
通过在不同规模的数据集上训练LongVA-TPO模型,实验结果表明TPO具有出色的可扩展性。随着数据集规模的增加,TPO模型的性能持续提升,表明其在处理大规模数据方面的潜力。
4.3.3 不同数据粒度的影响
实验还评估了局部和全面时间定位在TPO中的作用。结果表明,虽然局部和全面TPO各自在特定数据集上表现出色,但它们的结合实现了最佳性能。这强调了构建多粒度偏好数据集以充分利用时间建模能力的重要性。
4.3.4 针对性任务
在“大海捞针”任务中,LongVA-TPO模型也表现出色。该任务涉及在长达3小时的视频中识别稀有或特定事件,并回答相应的图像问答问题。实验结果表明,LongVA-TPO模型在定位相关信息和提供准确答案方面优于LongVA模型。
4.4 定性分析
通过定性分析,可以进一步了解TPO如何改进视频大型多模态模型的时间定位能力。在两个视频示例中,LongVA-TPO模型在定位相关信息和提供准确答案方面均优于LongVA模型。这表明TPO通过偏好学习有效地增强了模型的时间推理能力。
5. 结论
本文提出了时间偏好优化(TPO),一种新颖的后训练框架,旨在通过偏好学习增强视频大型多模态模型的时间定位能力。通过在局部和全面两个粒度上利用精心策划的偏好数据集,TPO显著提升了模型的时间理解能力,同时减少了对人工标注数据的依赖。在三个长视频理解基准数据集上的大量实验表明,TPO在两种最先进的视频大型多模态模型上均表现出有效性,并确立了其在Video-MME基准上作为领先7B模型的地位。这些结果表明,TPO作为推进长视频理解中时间推理的可扩展且高效解决方案的潜力巨大。
6. 未来工作
未来的工作可以进一步扩展偏好数据集的规模和多样性,以提高TPO的泛化能力。此外,将TPO应用于更广泛和更大规模的视频大型多模态模型也将提供对其适应性和性能的更深入见解。通过不断改进和优化TPO框架,我们有望为长视频理解领域带来更多的突破和进展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









