






摘要:基于大型语言模型(LLM)的代理的出现代表了人工智能领域的一次范式转变,使自主系统能够在与动态环境交互的过程中进行规划、推理、使用工具以及维持记忆。本文首次全面综述了针对这些能力日益增强的代理的评估方法。我们系统地分析了四个关键维度下的评估基准和框架,包括:(1)代理的基本能力,如规划、工具使用、自我反思和记忆;(2)针对网络、软件工程、科学和会话代理等特定应用的基准;(3)针对通用代理的基准;以及(4)用于评估代理的框架。我们的分析揭示了新兴趋势,包括向更真实、更具挑战性的评估转变,以及持续更新的基准。我们还指出了未来研究必须解决的关键空白,特别是在评估成本效益、安全性和鲁棒性方面,以及开发细粒度和可扩展的评估方法。本综述描绘了代理评估这一快速发展领域的全景,揭示了该领域的新兴趋势,指出了当前的局限性,并提出了未来研究的方向。Huggingface链接:Paper page,论文链接:2503.16416
研究背景和目的
研究背景
随着大型语言模型(LLMs)技术的飞速发展,其在自然语言处理(NLP)领域的应用日益广泛。基于LLMs的代理(Agents)作为LLMs技术的一个重要应用领域,正逐渐成为研究热点。这些代理不仅能够理解和生成自然语言,还能在与动态环境交互的过程中进行规划、推理、使用工具以及维持记忆,从而展现出高度的自主性和智能性。基于LLMs的代理在多个领域展现出巨大的应用潜力,如网络自动化、软件工程、科学研究和对话系统等。然而,随着这些代理能力的不断提升,如何准确、全面地评估其性能成为了一个亟待解决的问题。
传统的评估方法往往侧重于对单一任务或能力的评估,难以全面反映代理在实际应用中的复杂性和多样性。此外,随着技术的不断进步,新的评估需求也不断涌现,如成本效益、安全性和鲁棒性等方面的评估。因此,对基于LLMs的代理的评估方法进行系统梳理和深入分析,具有重要的理论意义和实践价值。
研究目的
本文旨在全面综述基于LLMs的代理的评估方法,为代理的性能评估提供一套系统、全面的框架。具体研究目的包括:
- 梳理现有评估方法:系统梳理当前基于LLMs的代理的评估方法,包括定量评估、定性评估以及结合人类反馈的评估等,为后续研究提供理论基础。
- 分析评估基准和框架:从基本能力、特定应用基准、通用代理基准以及评估框架四个关键维度,对现有评估基准和框架进行深入分析,揭示其优缺点和适用范围。
- 揭示新兴趋势:通过对现有评估方法的综合分析,揭示代理评估领域的新兴趋势,如向更真实、更具挑战性的评估转变,以及持续更新的基准等。
- 指出研究空白:识别当前评估方法中存在的关键空白,特别是在评估成本效益、安全性和鲁棒性方面,为未来研究提供方向。
- 提出未来研究方向:基于对现有评估方法的分析和新兴趋势的揭示,提出未来研究的方向和建议,以促进代理评估技术的进一步发展。
研究方法
文献综述法
本文采用文献综述法作为主要研究方法,通过广泛搜集和整理国内外相关文献,对基于LLMs的代理的评估方法进行系统梳理和深入分析。文献来源包括学术期刊、会议论文、技术报告等,涵盖了代理评估领域的各个方面。
比较分析法
在文献综述的基础上,本文采用比较分析法对不同评估方法、基准和框架进行深入比较和分析。通过对比不同方法的优缺点、适用范围以及实际效果等,揭示其内在规律和联系,为后续研究提供理论支持。
案例研究法
为了更具体地展示评估方法在实际应用中的效果,本文还采用了案例研究法。通过选取具有代表性的代理评估案例进行深入分析,揭示评估方法在实际应用中的问题和挑战,并提出相应的解决方案和建议。
研究结果
现有评估方法梳理
通过对现有文献的梳理和分析,本文系统地总结了基于LLMs的代理的评估方法。这些方法主要包括定量评估、定性评估以及结合人类反馈的评估等。定量评估方法主要通过一系列客观指标来衡量代理的性能,如准确率、召回率、F1值等;定性评估方法则主要通过人类专家的主观判断来衡量代理的性能,如语言流畅性、语法正确性和语义准确性等;结合人类反馈的评估方法则通过引入人类专家的反馈来指导代理的训练和优化过程。
评估基准和框架分析
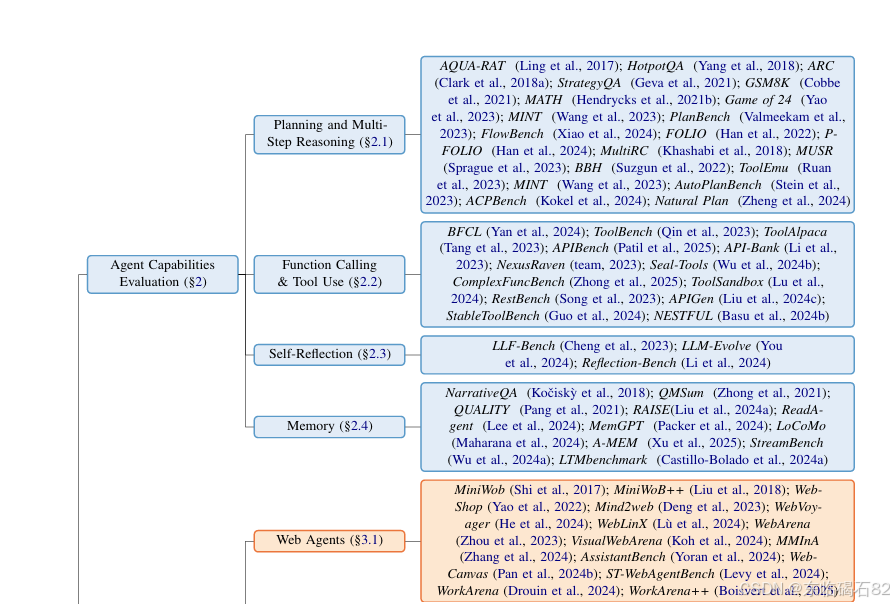
本文从基本能力、特定应用基准、通用代理基准以及评估框架四个关键维度对现有评估基准和框架进行了深入分析。在基本能力方面,主要评估代理的规划、工具使用、自我反思和记忆等能力;在特定应用基准方面,针对网络、软件工程、科学和会话代理等特定应用领域设计了相应的评估基准;在通用代理基准方面,则设计了适用于多种应用场景的通用评估基准;在评估框架方面,则提供了用于评估代理性能的综合框架。
新兴趋势揭示
通过对现有评估方法的综合分析,本文揭示了代理评估领域的新兴趋势。随着技术的不断进步和应用场景的不断拓展,代理评估正逐渐向更真实、更具挑战性的方向转变。同时,为了保持评估的有效性和准确性,评估基准也在不断更新和完善。
研究空白指出
本文还指出了当前评估方法中存在的关键空白。特别是在评估成本效益、安全性和鲁棒性方面,现有评估方法往往难以全面反映代理在实际应用中的复杂性和多样性。此外,在开发细粒度和可扩展的评估方法方面也存在较大挑战。
研究局限
尽管本文在基于LLMs的代理的评估方法方面进行了全面综述和分析,但仍存在一些局限性。首先,由于代理评估领域发展迅速,新的评估方法和基准不断涌现,因此本文可能无法涵盖所有最新的研究成果。其次,由于代理评估涉及多个方面和维度,因此本文可能无法对所有评估方法和基准进行深入剖析和比较。最后,由于代理评估的复杂性和多样性,本文可能无法为所有应用场景提供统一的评估框架和标准。
未来研究方向
针对当前评估方法中存在的局限性和挑战,本文提出了未来研究的方向和建议。首先,应进一步加强对成本效益、安全性和鲁棒性等方面的评估方法研究,以更全面地反映代理在实际应用中的性能表现。其次,应开发更加细粒度和可扩展的评估方法,以适应不同应用场景和复杂度的评估需求。最后,应加强对评估框架和标准的研究和制定工作,为代理评估提供统一、规范的指导。
此外,未来研究还应关注以下几个方面:一是加强跨学科合作与交流,借鉴其他领域的研究成果和经验来推动代理评估技术的发展;二是加强对代理评估的理论研究和方法创新工作,提出更加科学、合理的评估方法和框架;三是加强对代理评估的实证研究与应用验证工作,通过实际应用来检验评估方法和框架的有效性和实用性。
综上所述,本文全面综述了基于LLMs的代理的评估方法,并指出了当前评估方法中存在的局限性和未来研究的方向。希望本文能够为代理评估领域的研究人员和实践者提供参考和借鉴价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









