






摘要:近期,开放世界环境中的基于动作的决策制定受到了广泛关注。在大规模网络数据集上预训练的视觉语言动作(Visual Language Action, VLA)模型在决策制定任务中展现出了潜力。然而,以往的研究主要聚焦于动作后训练,往往忽视了对基础模型本身的增强。针对这一问题,我们提出了一种新方法——基于视觉语言后训练的动作生成(Act from Visual Language Post-Training),该方法通过视觉和语言引导,以自监督的方式对视觉语言模型(Visual Language Models, VLMs)进行精炼。这种增强提升了模型在开放世界环境中的世界知识、视觉识别以及空间定位能力。遵循上述后训练范式,我们在《我的世界》(Minecraft)中获得了首批能够遵循人类指令完成超过1000种不同原子任务的VLA模型,这些任务包括制作、冶炼、烹饪、采矿和击杀等。我们的实验表明,在非轨迹任务上进行后训练,相较于最佳代理基线,在一系列多样化的原子任务上取得了显著的40%性能提升。此外,我们还证明了我们的方法在《我的世界》中超越了传统的基于模仿学习的策略,达到了最先进的性能。为了促进进一步的研究,我们已经开源了代码、模型和数据集。项目页面可在JARVIS-VLA找到。Huggingface链接:Paper page,论文链接:2503.16365
研究背景和目的
研究背景
近年来,随着人工智能技术的飞速发展,特别是深度学习在自然语言处理和计算机视觉领域的突破,基于视觉和语言信息的智能代理开始在各种复杂任务中展现出巨大的潜力。然而,尽管这些智能代理在封闭或受限环境中已经取得了令人瞩目的成果,但在开放世界环境中实现高效、鲁棒的决策制定仍然是一个巨大的挑战。开放世界环境通常具有高度的复杂性和不确定性,要求智能代理具备强大的感知、理解和决策能力。
在这一背景下,视觉语言动作(Visual Language Action, VLA)模型逐渐成为研究热点。VLA模型通过在大规模网络数据集上进行预训练,将视觉和语言信息紧密结合,实现了对复杂环境的理解和动作生成。然而,当前VLA模型的研究主要集中在动作后训练阶段,即通过模仿学习等方法优化模型在特定任务上的表现,而往往忽视了对基础模型本身的增强。这种研究范式限制了VLA模型在开放世界环境中的泛化能力和决策制定效率。
针对上述问题,本研究旨在提出一种新的训练框架,通过对大规模视觉语言模型进行后训练,显著提升其在开放世界环境中的决策制定能力。具体而言,本研究聚焦于《我的世界》(Minecraft)这一开放世界游戏环境,旨在开发能够遵循人类指令完成多样化任务的VLA模型。Minecraft作为一款高度复杂和动态的沙盒游戏,为测试智能代理的决策制定能力提供了理想的平台。
研究目的
-
提升VLA模型在开放世界环境中的决策制定能力:通过引入新的训练框架,增强VLA模型对世界知识的理解、视觉识别的准确性以及空间定位的能力,从而提升其在复杂和动态环境中的决策效率。
-
开发高效的VLA模型训练策略:研究并提出一种有效的视觉语言后训练(Act from Visual Language Post-Training, ActVLP)策略,通过自监督学习的方式,利用视觉和语言信息对VLA模型进行精炼,从而提升其基础能力。
-
在Minecraft中实现先进的VLA模型:基于上述训练策略,在Minecraft中开发能够遵循人类指令完成多样化任务的VLA模型,包括制作、冶炼、烹饪、采矿和击杀等原子任务。
-
推动VLA模型研究的进一步发展:通过开源代码、模型和数据集,为VLA模型的研究提供丰富的资源和平台,促进相关研究的进一步深入。
研究方法
模型结构
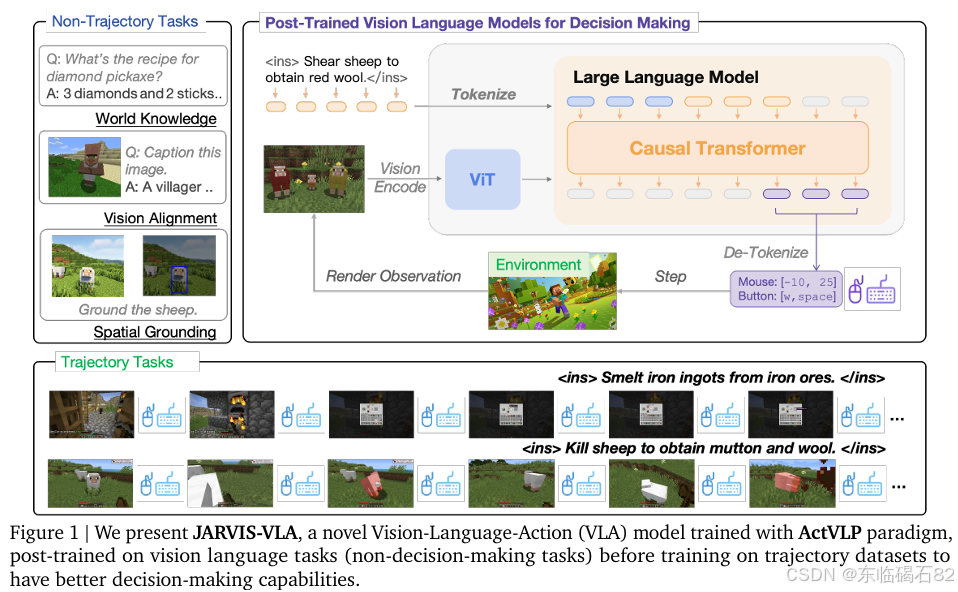
本研究提出的JARVIS-VLA模型采用了一种类似于Llava的架构,但进行了适当的修改以适应开放世界环境的需求。模型主要包含以下几个关键组件:
-
视觉编码器:采用视觉变换器(Vision Transformer, ViT)处理原始图像像素,并将其转换为固定大小的图像块序列。
-
图像投影模块:一个轻量级的两层多层感知器(MLP),将图像块嵌入投影到与词嵌入相同的表示空间中。
-
大型语言模型:一个强大的自回归语言模型,作为系统的核心,促进多模态推理和决策制定。
-
动作解码器:负责生成离散和连续动作。对于离散动作,将相关动作维度整合到统一类别中以提高效率;对于连续动作,将动作空间离散化为多个区间,并将其映射到离散令牌上,从而允许模型以统一的方式生成文本和基于动作的输出。
训练管道
本研究提出了一种多阶段的训练管道,包括三个阶段:
-
语言模型后训练:首先,在大规模文本数据集上对语言模型进行后训练,增强其对下游环境中决策制定上下文的理解。在此阶段,与视觉相关的组件(包括ViT和视觉适配器模块)被冻结。
-
视觉编码器和语言模型后训练:接下来,完全解冻VLM,并使用多模态视觉语言对齐和空间定位数据集对其进行微调。这一阶段确保了改进的视觉语言对齐,增强了模型将世界知识与视觉感知相结合的能力。
-
轨迹上的模仿学习:在最后阶段,使用轨迹数据对VLM进行微调,要求模型在给定的文本指令和当前观察图像的情况下模仿专家动作。在此阶段,视觉相关模块保持冻结状态,而语言标记器被修改为包含动作标记,并对语言变换器进行全参数微调。
数据集
为了支持上述训练管道,本研究构建了一个大规模多模态数据集,包括用于后训练的非轨迹任务数据集和用于下游模仿学习的轨迹数据集。非轨迹数据集分为三个类别:基于知识的问答、视觉语言对齐和空间定位,旨在在轨迹微调之前增强模型的决策制定能力。轨迹数据集则包含了超过740万帧的Minecraft游戏数据,包括来自人类玩家、YouTube视频和现有代理的专家动作。
研究结果
性能评估
本研究在Minecraft上对JARVIS-VLA模型进行了全面的性能评估,并与多种基线方法进行了比较。实验结果表明,JARVIS-VLA模型在几乎所有任务组别上都取得了最高的成功率,特别是在制作和冶炼等任务上,相较于基线模型实现了超过两倍的性能提升。
消融研究
本研究还进行了消融研究,以探究不同非轨迹任务数据集对模型性能的具体贡献。实验结果显示,空间定位任务对下游决策制定任务的性能提升最为显著,表明空间定位能力是开放世界环境中智能代理决策制定的关键因素之一。
缩放实验
本研究还探索了VLA模型的缩放行为,发现增加非轨迹视觉语言任务的数据量可以显著提升下游任务的性能,即使在固定数量的轨迹微调数据下也是如此。这一发现为未来通过扩展非轨迹任务数据集来进一步提升VLA模型性能提供了重要启示。
研究局限
尽管本研究在提升VLA模型在开放世界环境中的决策制定能力方面取得了显著进展,但仍存在一些局限性:
-
推理吞吐量受限:当前JARVIS-VLA模型的推理吞吐量受到其基于VLM的大参数规模的限制。这限制了模型在实时应用中的表现。
-
性能仍有提升空间:尽管JARVIS-VLA模型在Minecraft中的表现已经超越了之前的基线方法,但仍与人类玩家的最佳表现存在差距。这表明模型在复杂和动态环境中的决策制定能力仍有待进一步提升。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
-
提升推理效率:通过引入专家混合(Mixture of Experts, MoE)等技术,优化模型架构,提升推理效率,使模型能够在实时应用中表现更好。
-
增强模型能力:进一步探索如何结合自监督学习、强化学习等先进技术,增强模型对世界知识的理解、视觉识别的准确性以及空间定位的能力,从而提升其在复杂和动态环境中的决策制定效率。
-
拓展应用场景:将JARVIS-VLA模型的应用拓展到更多开放世界环境和任务中,如自动驾驶、机器人控制等,以验证其广泛适用性和鲁棒性。
-
开发新评估方法:针对现有评估方法的局限性,开发更加全面和准确的评估方法,以更好地反映模型在开放世界环境中的实际表现。
通过上述研究方向的深入探索,有望进一步提升VLA模型在开放世界环境中的决策制定能力,推动人工智能技术的进一步发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









