






摘要:预训练的视觉基础模型(Vision Foundation Models, VFMs)为广泛的应用提供了强大的视觉表征。在本文中,我们以多模态的方式对主流的VFMs进行持续预训练,使它们能够轻松处理不同大小的视觉输入,并生成与语言表征更加对齐的视觉表征,无论其原始的预训练过程如何。为此,我们引入了CoMP,这是一个精心设计的多模态预训练流程。CoMP使用持续旋转位置嵌入(Continual Rotary Position Embedding)来支持原生分辨率的持续预训练,并通过语言原型在视觉和文本特征之间引入对齐损失(Alignment Loss),以实现多模态表征的对齐。通过三阶段训练,我们的VFMs不仅在多模态理解方面取得了显著的提升,而且在分类和分割等其他下游任务中也表现出色。值得注意的是,CoMP-SigLIP在搭配0.5B语言大模型(LLM)时,在ChartQA数据集上取得了66.7的分数,在DocVQA数据集上取得了75.9的分数,同时在ImageNet-1K数据集上保持了87.4%的准确率,在ADE20K数据集上取得了49.5的mIoU(平均交并比),且这些评估都是在冻结部分模型参数的情况下进行的。Huggingface链接:Paper page,论文链接:2503.18931
研究背景和目的
研究背景
随着计算机视觉和自然语言处理技术的不断融合,预训练的视觉基础模型(Vision Foundation Models, VFMs)在多个应用领域中展现了强大的能力。这些模型通过在大规模数据集上的预训练,学习到了丰富的视觉表征,为后续的各种下游任务提供了坚实的基础。然而,现有的VFMs在处理不同分辨率的视觉输入时仍存在局限,尤其是在处理高分辨率图像时,往往需要进行缩放或裁剪,这会导致关键信息的丢失。此外,VFMs的视觉表征与语言大模型(Large Language Models, LLMs)的表征之间存在一定的差距,这限制了多模态理解和生成任务的性能。
针对上述问题,本研究提出了一种新的持续多模态预训练框架(CoMP),旨在通过多模态的预训练方式,进一步提升VFMs处理不同分辨率视觉输入的能力,并使其视觉表征与LLMs的表征更加对齐。这不仅有助于提升VFMs在多模态理解任务中的性能,还能拓展其在分类、分割等下游任务中的应用潜力。
研究目的
-
提升VFMs处理不同分辨率视觉输入的能力:通过设计持续旋转位置嵌入(C-RoPE),使VFMs能够轻松处理不同大小的视觉输入,尤其是高分辨率图像,而无需进行缩放或裁剪。
-
对齐VFMs与LLMs的表征:通过引入对齐损失(Alignment Loss),在视觉和文本特征之间建立联系,使VFMs的视觉表征与LLMs的表征更加对齐,从而提升多模态理解和生成任务的性能。
-
提升VFMs在多模态理解和下游任务中的性能:通过CoMP框架的三阶段训练,使VFMs在多模态理解任务中取得显著的性能提升,并在分类、分割等下游任务中表现出色。
研究方法
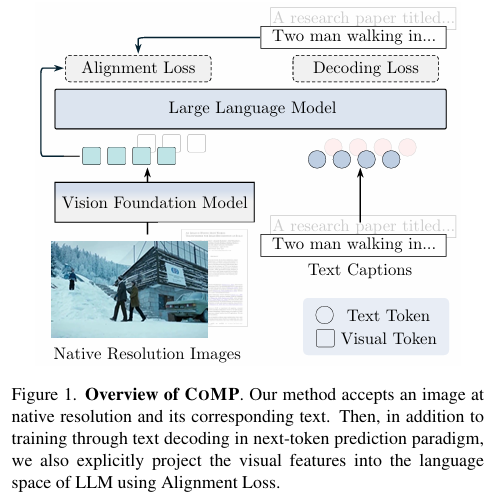
CoMP框架概述
CoMP框架是一个精心设计的多模态预训练流程,包括持续旋转位置嵌入(C-RoPE)和对齐损失(Alignment Loss)两个核心组件。通过三阶段训练,CoMP能够持续提升VFMs的性能。
持续旋转位置嵌入(C-RoPE)
为了支持原生分辨率的持续预训练,CoMP引入了C-RoPE。C-RoPE结合了标准RoPE-2D和学习到的一维位置嵌入,通过以下方式工作:
-
图像分割:将二维图像分割成多个补丁(patches),每个补丁被视为一个视觉标记(token)。
-
位置嵌入:对每个补丁应用学习到的位置嵌入,并通过双线性插值适应不同分辨率的输入。
-
旋转位置嵌入:在视觉编码器的每一层中,应用RoPE-2D对视觉标记进行旋转位置编码,以捕捉视觉元素之间的相对位置关系。
对齐损失(Alignment Loss)
为了对齐VFMs与LLMs的表征,CoMP引入了对齐损失。该损失通过以下方式工作:
-
特征提取:通过VFMs和LLMs分别提取视觉和文本特征。
-
原型映射:将视觉特征映射到LLMs的词嵌入空间中,作为原型(prototypes)。
-
对齐损失计算:通过交叉熵损失函数计算视觉和文本特征之间的对齐损失,以优化VFMs的参数。
三阶段训练流程
CoMP框架采用三阶段训练流程:
-
阶段一:视觉-语言适配器预热:在此阶段,冻结VFMs和LLMs的参数,仅训练视觉-语言适配器。通过固定低分辨率的图像输入,使适配器适应多模态任务。
-
阶段二:原生分辨率适应:在此阶段,解冻VFMs和LLMs的参数,并在固定的高分辨率和原生分辨率下训练整个模型。通过C-RoPE支持原生分辨率的输入。
-
阶段三:指令微调(可选):在此阶段,对整个模型进行指令微调,以适应不同类型的数据输入。通过LLMs的指令数据,进一步提升模型的多模态理解和生成能力。
研究结果
多模态理解任务性能提升
在多个多模态理解基准测试集上,CoMP框架训练的VFMs取得了显著的性能提升。具体结果如下:
- ChartQA:CoMP-SigLIP取得了66.7的分数,相比基线模型有显著提升。
- DocVQA:CoMP-SigLIP取得了75.9的分数,同样优于基线模型。
- VQAv2、GQA等:CoMP框架训练的模型在多个通用和现实世界的多模态理解任务上也取得了优异的表现。
下游任务性能保持
除了多模态理解任务外,CoMP框架训练的VFMs在分类和分割等下游任务中也表现出色。具体结果如下:
- ImageNet-1K分类:CoMP-SigLIP在224px和448px分辨率下分别取得了86.1%和87.1%的准确率,与基线模型相当甚至更高。
- ADE20K分割:CoMP-SigLIP在504px和672px分辨率下分别取得了49.5和49.1的mIoU(平均交并比),显著优于基线模型。
消融研究
通过消融研究,我们验证了C-RoPE和对齐损失在提升模型性能中的关键作用。具体结果如下:
- C-RoPE的有效性:相比仅使用学习到的位置嵌入或RoPE-2D,C-RoPE能够显著提升模型处理高分辨率输入的能力。
- 对齐损失的有效性:对齐损失在多模态理解任务中表现出色,尤其是在文本丰富的任务中。随着对齐损失应用时间的延长,模型性能进一步提升。
研究局限
尽管CoMP框架在多个任务中取得了显著的性能提升,但仍存在一些局限性:
-
大规模实验缺乏:目前的研究主要在相对较小规模的数据集上进行,缺乏在大规模文本到视频生成任务上的实验验证。
-
长视频处理能力有限:受限于可用数据集,目前的研究仅在最多300帧(约20秒)的视频上进行实验,未充分探索模型处理长视频的能力。
-
计算资源需求高:多模态预训练需要大量的计算资源,尤其是在处理高分辨率图像和长视频时。
未来研究方向
针对上述局限性,未来的研究工作可以从以下几个方面展开:
-
大规模实验验证:在大规模文本到视频生成任务上验证CoMP框架的有效性,进一步提升模型的性能和应用潜力。
-
长视频处理能力提升:模拟更长的视频数据集,以更好地评估模型处理长视频的能力,并探索如何进一步提升模型在长视频生成任务中的性能。
-
计算资源优化:研究如何优化模型结构和训练流程,减少计算资源的消耗,使CoMP框架能够在更广泛的计算环境下应用。
-
多模态融合策略探索:探索更有效的多模态融合策略,以进一步提升模型在多模态理解和生成任务中的性能。
综上所述,CoMP框架为提升VFMs的性能和应用潜力提供了新的思路和方法。通过持续的多模态预训练,CoMP不仅使VFMs能够轻松处理不同分辨率的视觉输入,还使其视觉表征与LLMs的表征更加对齐,从而在多个任务中取得了显著的性能提升。未来的研究工作将进一步拓展CoMP框架的应用范围,并探索更高效的模型结构和训练流程。

















 8378
8378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









