







激活函数与Loss
包括MSE和交叉熵
MSE
不需要开平方
函数F.mse_loss(torch.ones(1),x*w) : 第一个是预测的值,第二个是标签的值
函数 torch.autograd.grad(mse,[w]) : 接收两个参数,第一个是目标函数y,在这里是mse,第二个参数是目标函数的自变量,在这里是w
下面这个例子中y = 1
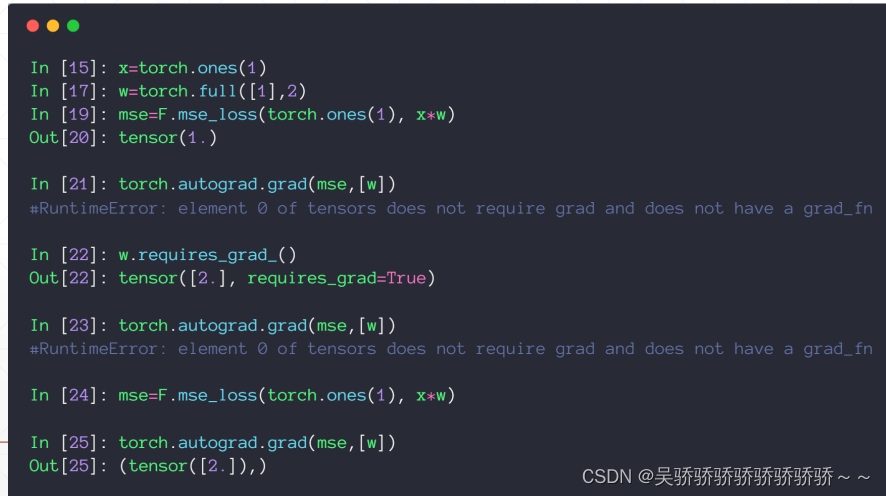
必须要对w信息进行更新,告诉pytorch w需要求导
也可以在初始化时 就是建立需要求导的信息 如
w = torch.full([1],2,requires_grad = True) # 告诉w需要求导信息
mse_loss()会建立动态图
mse.backward()会自动求解所有能求解的梯度值
这里补充一些范数的基本概念
softmax 激活函数 soft version of max

所有概率值之和为1
单层感知机的推导
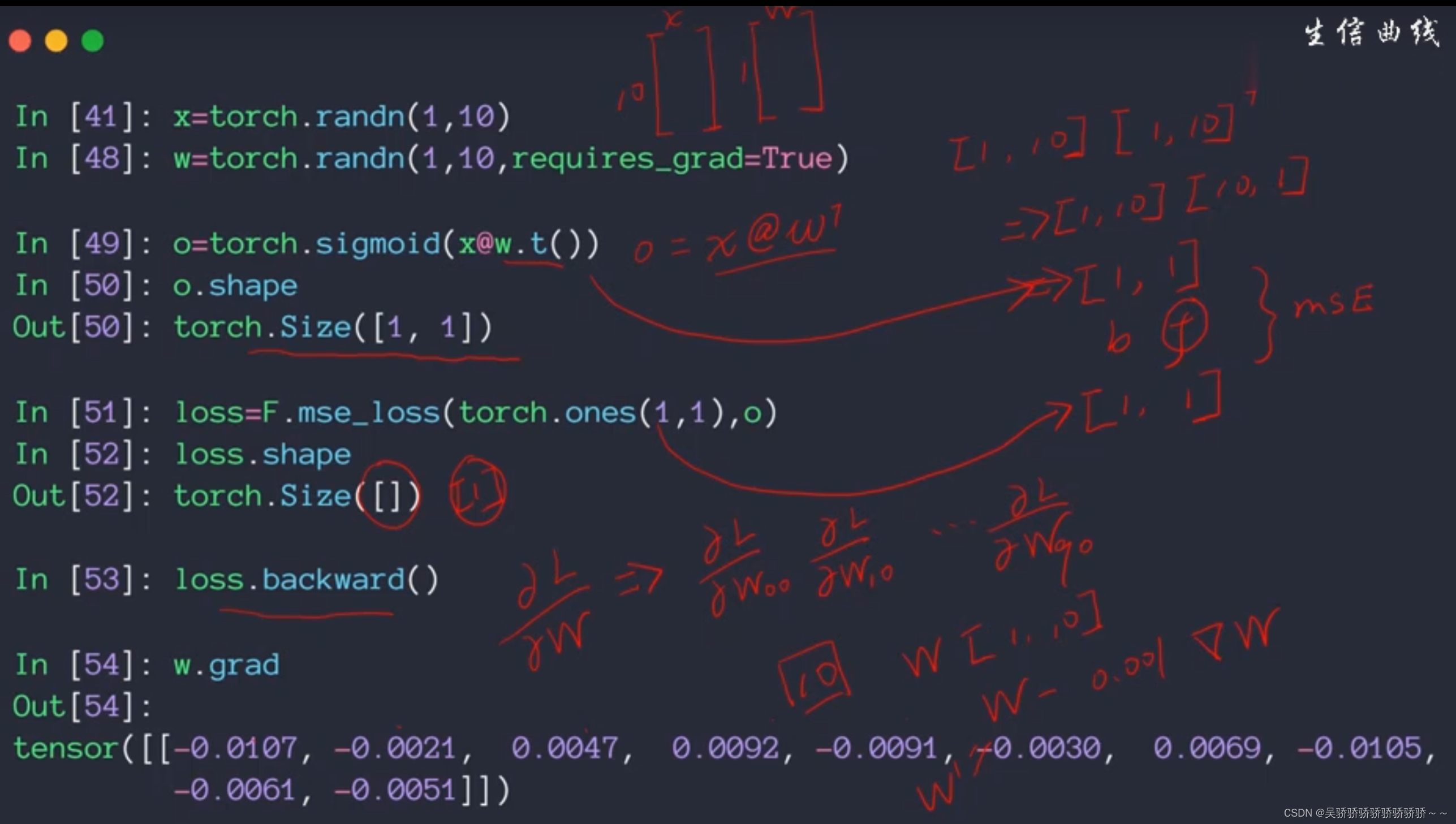
梯度更新的过程
在经过复杂的公式推导之后,直接看推导结果。从结果感性的理解梯度更新的过程。
如下面两图所示,当进行一次运算之后,已知的量包括:所有节点的输出,所有权值w在本轮运算的值
在经过之前的公式推导之后可以知道,这一层的梯度信息是可以通过这一层的输出与下一层的梯度信息相乘得到。而输出层的梯度信息是根据输出结果O与标签值t得到的。那么既然最后一层的梯度信息已知,每一层的输出也已知,就可以从后往前一步一步的推导得到每一层的梯度信息,从而更新本轮的所有参数的梯度信息。
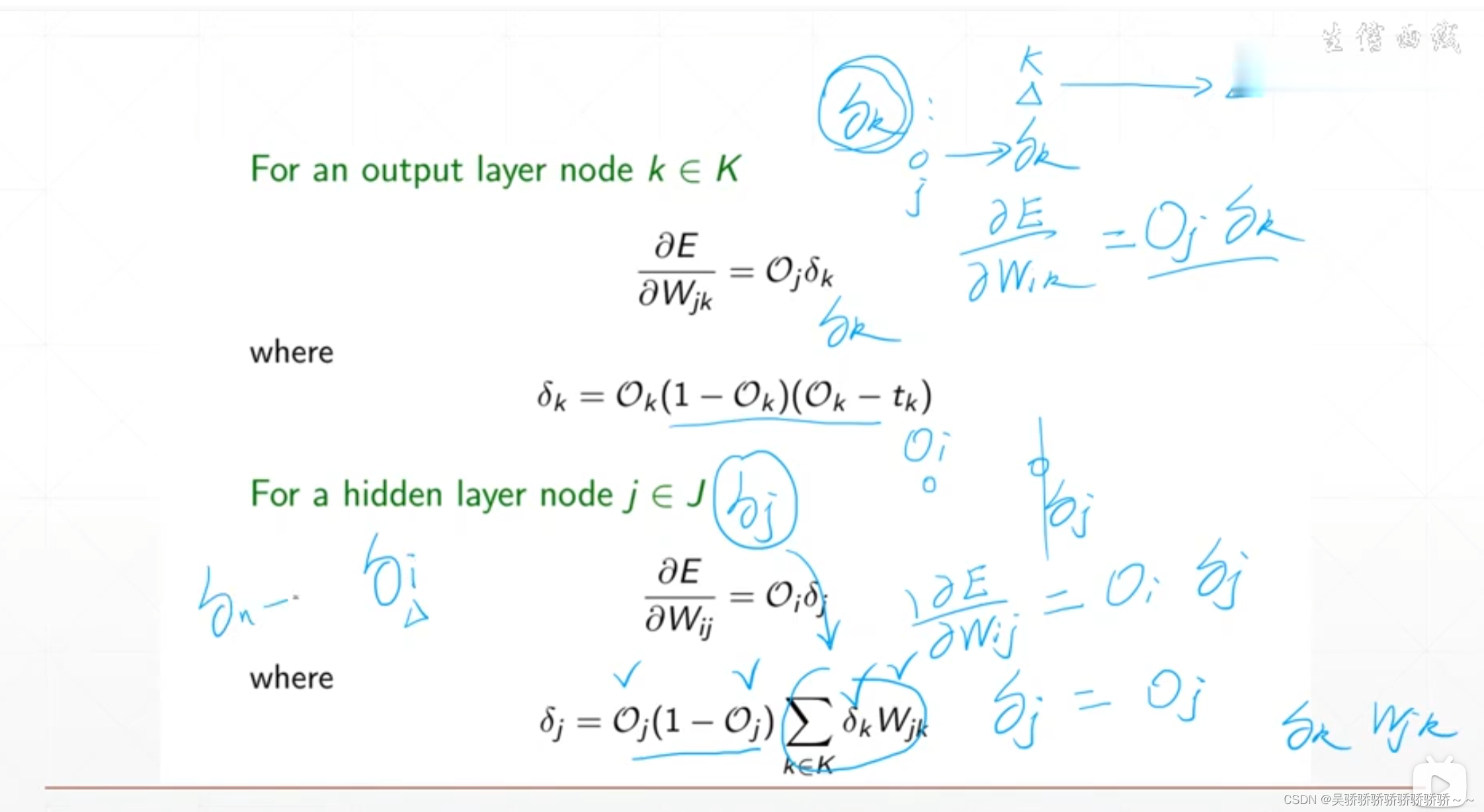
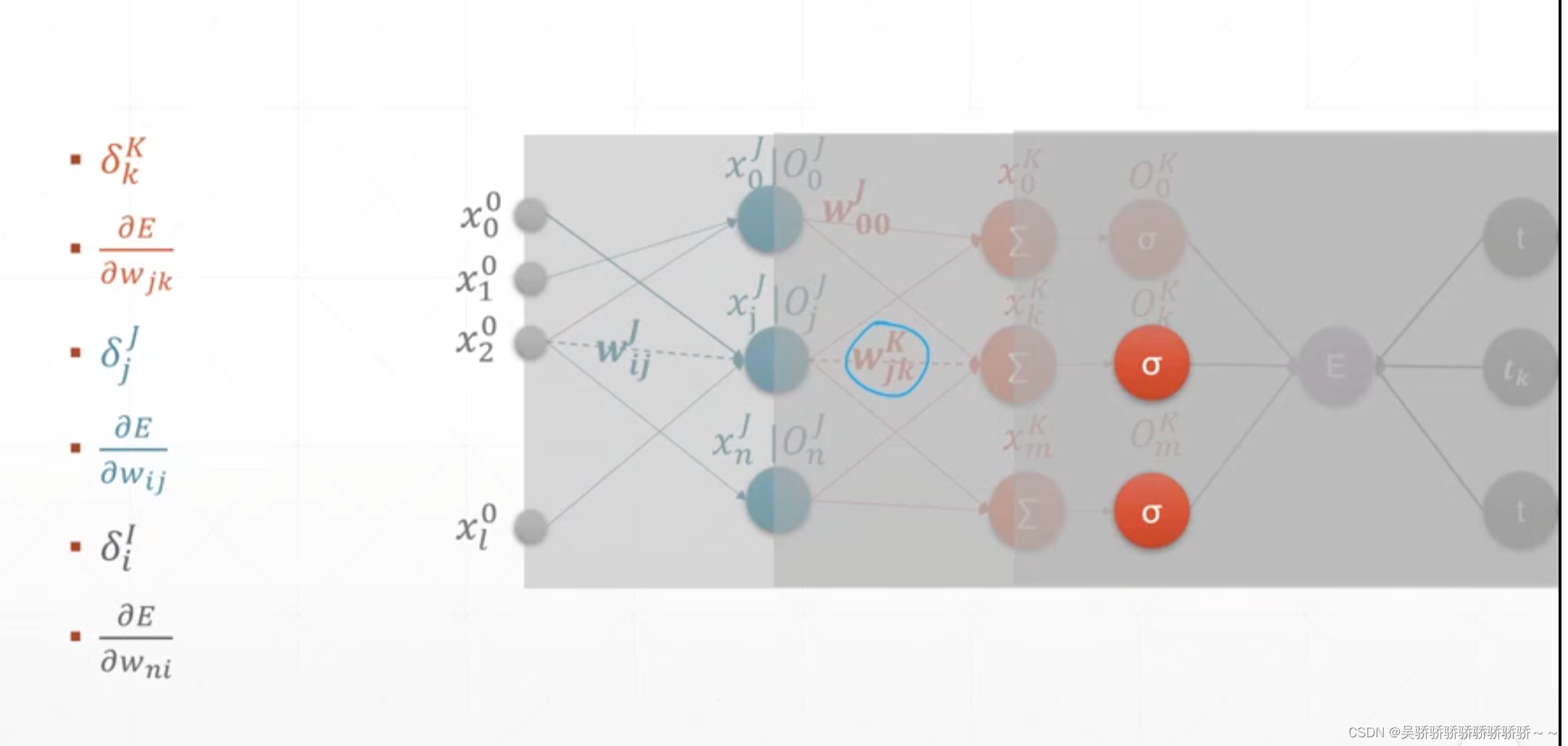
一个例子
如下图:在这里optimizer的操作就是实现使用求出的梯度信息来更新变量 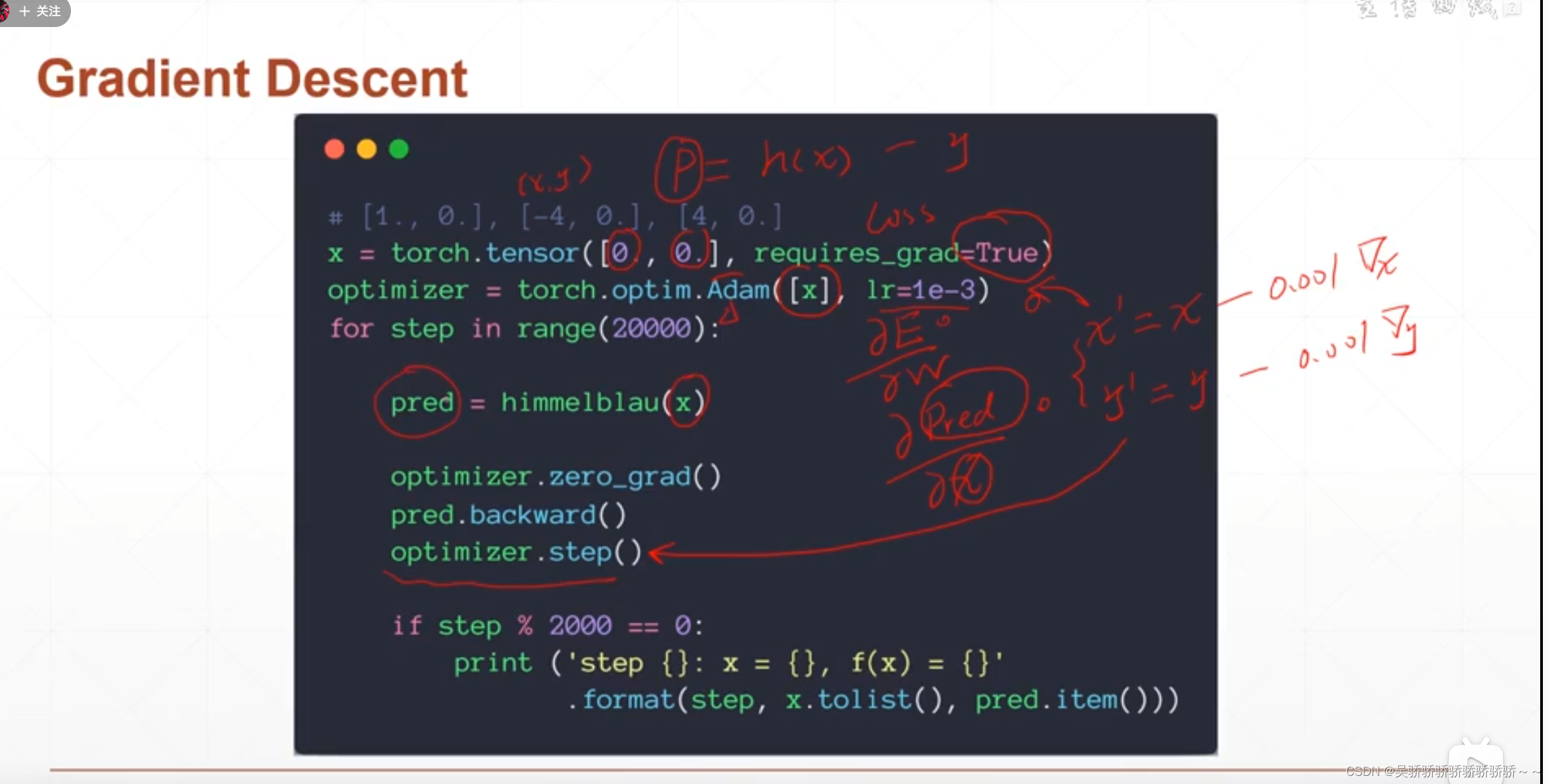
backwards方法更新梯度信息
后面再使用step操作
熵 交叉熵
熵表示的就是混乱程度 混乱程度越高 熵越高 所蕴含的可能及信息就越多
对于01分布 熵为0
交叉熵可以拆分为熵和KL散度,KL散度就是描述两个分布的离散程度。两份高斯分布完全重合,其KL散度就为0,因为完全不离散。
如果使用one-hot编码,那么交叉熵中的熵就为0,求交叉熵就等于求两个分布的KL散度。

二分类的优化目标

总体的计算流程
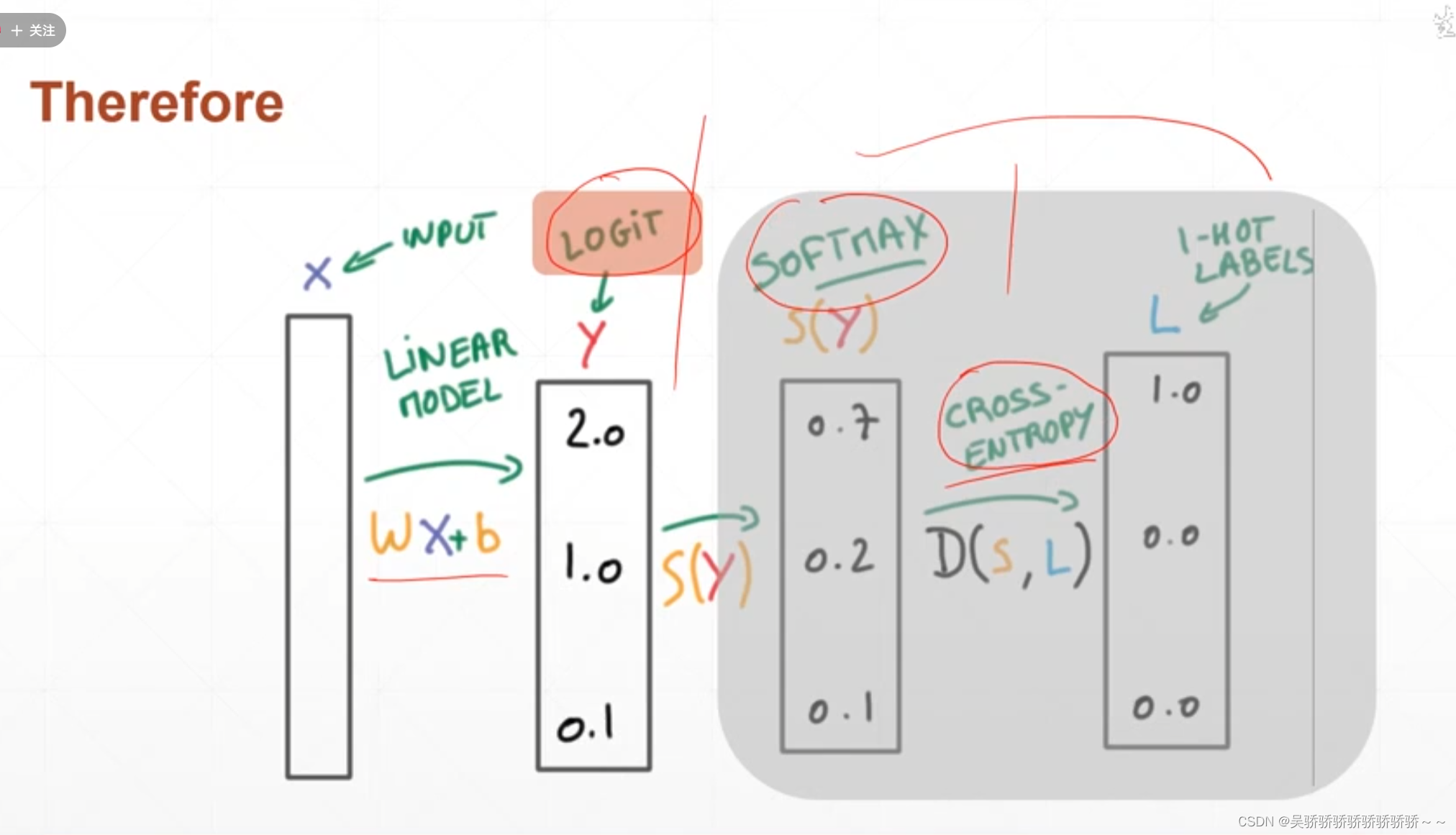
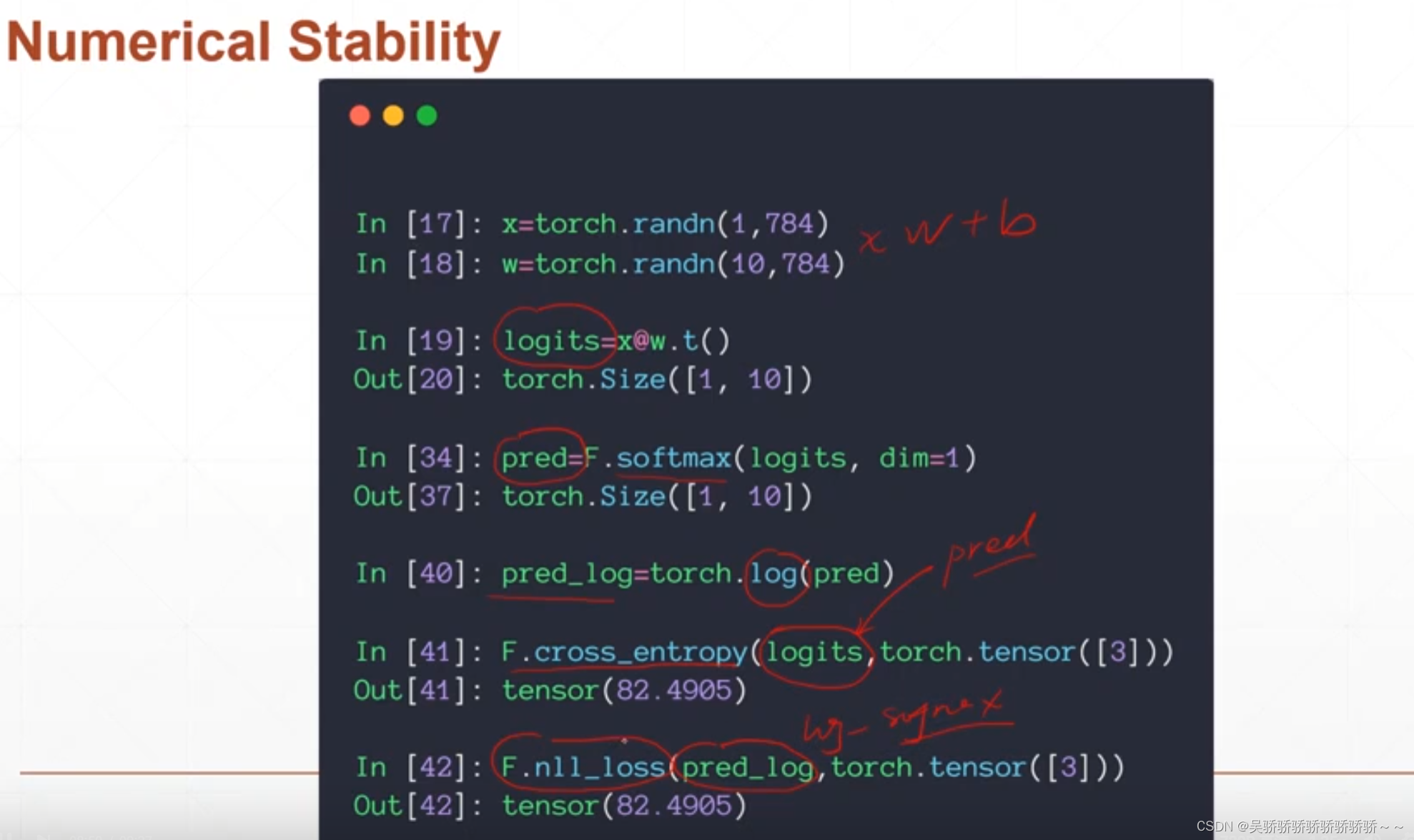
灰色部分直接打包成模块使用 就是corss_entropy = softmax + log + nll_loss















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









