







目录
在PyTorch中,torch.mm与torch.matmul有什么区别?
PyTorch模型的序列化和加载过程中常见的问题及解决方案是什么?
基本的功能和类
基本函数
-
创建张量:
torch.tensor (data, dtype=None, device=None, requires_grad=False, pin_memory=False):根据传入的数据返回相应形状的张量。torch.arange (min, max, stride):类似于Python中的range,用于生成一维的等差数列。
-
矩阵运算:
torch.mm (input, other):计算两个张量的矩阵乘法。torch.max (input, dim):求取指定维度上的最大值,并同时返回每个最大值的位置索引。
-
激活函数:
torch.nn.functional.relu (input):ReLU激活函数,用于对输入数据进行非线性处理。torch.nn.functional.tanh (input):Tanh激活函数,同样用于非线性处理。
-
卷积操作:
torch.nn.functional.conv2d (input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):二维卷积操作。 -
其他常用函数:
torch.reshape (input, shape)或torch.view (input, shape):用于对张量进行重塑。torch.save (obj, f)和torch.load (f):用于保存和加载模型。
基本类
-
Tensor:
PyTorch中的核心数据结构,可以看作是NumPy数组的等价物,支持各种数学运算和数据处理。
-
Module:
- 自定义层时需要继承这个类,并实现构造函数
__init__和前向计算函数forward。 nn.ModuleList:可以将任意nn.Module的子类(如nn.Conv2d,nn.Linear等)加入到这个list里面。nn.Sequential:用于按顺序堆叠多个模块。
- 自定义层时需要继承这个类,并实现构造函数
-
参数管理:
torch.nn.Parameter:用于定义可学习的参数,通常在模块初始化时通过nn.Parameter来定义。
这些基本函数和类构成了PyTorch框架的基础,能够帮助用户高效地进行深度学习模型的构建和训练。此外,PyTorch还提供了丰富的API文档和教程,以供进一步学习和探索.
PyTorch中如何实现自定义激活函数?
在PyTorch中实现自定义激活函数的步骤如下:
-
创建类并继承nn.Module:首先,需要创建一个类来实现激活函数。这个类应该继承自PyTorch的
nn.Module类,并实现forward()方法。在forward()方法中,应该调用自定义的非线性函数。 -
注册到模型中:最后,需要将自定义的激活函数注册到深度学习模型中,以便在训练过程中使用。
-
处理梯度传播:如果自定义的激活函数不是可导的,比如类似于ReLU的分段可导的函数,需要写一个继承
torch.autograd.Function的类,并自行定义forward和backward的过程。 -
实现前向传播和反向传播:对于常用的激活函数,如Sigmoid,需要实现其前向传播和反向传播。前向传播阶段,简单地将输入数据传递给激活函数;反向传播阶段,根据激活函数的导数计算梯度。
-
考虑是否需要可学习参数:如果需要为激活函数添加可学习的参数,可以参考PyTorch官方激活函数源码实现,如PReLU等。
实现自定义激活函数的关键在于创建一个继承自nn.Module的类,实现forward()方法,并根据需要处理梯度传播和反向传播。
在PyTorch中,torch.mm与torch.matmul有什么区别?
在PyTorch中,torch.mm 与torch.matmul 的主要区别在于它们处理矩阵乘法的方式和适用的场景。
-
torch.mm:torch.mm用于执行两个2D张量的矩阵乘法,不支持广播操作。这意味着两个输入张量必须具有兼容的形状,即第一个张量的列数必须与第二个张量的行数相同。例如,如果输入张量是(n×m)的,第二个张量是(m×p)的,那么输出张量将是(n×p)的。 -
torch.matmul:torch.matmul用于执行两个张量的矩阵乘法,支持广播操作。这意味着它可以处理不同形状的张量,只要它们可以被广播到相同的形状。例如,如果第一个张量是(n×m)的,第二个张量是(p×q)的,那么torch.matmul可以将它们转换为兼容的形状,然后执行矩阵乘法。这使得torch.matmul在处理不同形状的张量时更加灵活。
PyTorch中的卷积操作有哪些高级技巧和最佳实践?
在PyTorch中,卷积操作是深度学习中非常重要的一个环节,特别是在卷积神经网络(CNN)中。以下是一些高级技巧和最佳实践:
-
卷积核超参数选择:
卷积核的超参数选择是一个挑战,可以通过多种变换路线来优化。例如,可以尝试不同的卷积核大小、步长和填充策略,以找到最佳组合。
-
1x1卷积:
1x1卷积(也称为深度可分离卷积)可以用于减少计算量和参数数量。它将卷积操作分解为两个步骤:一个1x1卷积用于通道维度的压缩,另一个卷积用于特征提取。
-
填充和步长:
填充(padding)和步长(stride)是调整卷积输出大小的关键参数。填充可以用来保持输入和输出的尺寸一致,而步长决定了卷积窗口在输入上的滑动步长。
-
使用默认设置:
PyTorch中的默认设置对于2D卷积是
kernel_size=3,即3x3的卷积核。对于3D卷积,默认也是3x3x3的核。这些默认设置可以作为起点,但根据具体任务需求进行调整。 -
权重和偏置设置:
在定义卷积层时,可以指定权重张量形状和偏置。例如,使用
nn.Conv2d(in_channels, out_channels, kernel_size, bias=True)来启用偏置项。 -
输出形状调整:
使用不同的参数调整卷积层的输出形状。例如,通过设置
stride和padding来控制输出尺寸。 -
高级索引实现卷积:
PyTorch提供了高级索引功能,可以实现更复杂的卷积操作。例如,可以使用索引操作来实现特定的卷积模式。
-
激活函数选择:
卷积操作本质上是线性操作,因此通常在卷积层后使用非线性激活函数(如ReLU)来引入非线性。
-
多通道图像处理:
对于多通道图像,需要指定输入特征数量(
in_channels)和输出通道数(out_channels)。例如,处理RGB图像时,in_channels=3。
如何在PyTorch中高效地管理和优化参数?
在PyTorch中高效地管理和优化参数可以通过多种方法实现,以下是一些关键技巧和策略:
梯度裁剪:梯度裁剪可以防止在训练过程中出现梯度爆炸或梯度消失的问题,从而提高模型的稳定性和训练效率。
数据归一化和洗牌:通过数据归一化和洗牌,可以提高数据的分布均匀性,从而加快模型的收敛速度。
使用Module和ModuleList:在PyTorch中,使用
Module和ModuleList可以更好地组织和管理模型的结构,使得代码更加简洁和易于维护。自定义参数化方法:通过
torch.nn.utils.parametrize.register _parametrization,可以将自定义参数化方法应用于模块中的张量,这对于改变和控制模型参数的行为非常有用,特别是在需要对参数施加特定的约束或转换时。优化器的参数选项:在PyTorch中,优化器支持指定每个参数的选项,这可以通过传递一个包含参数组的字典来实现,从而为不同的参数组设置不同的优化器参数。
在DataLoader中使用workers:通过在DataLoader中使用多线程,可以提高数据加载的速度,从而加快模型的训练速度。
设置Pin memory:在数据加载过程中设置Pin memory可以提高数据传输的效率,特别是在CPU到GPU的传输过程中。
避免CPU与GPU间的传输:尽量在GPU上构建张量和进行计算,以减少CPU与GPU间的数据传输,从而提高计算效率。
PyTorch模型的序列化和加载过程中常见的问题及解决方案是什么?
在使用PyTorch进行模型的序列化和加载过程中,可能会遇到一些常见问题。以下是一些常见的问题及其解决方案:
-
模型版本不兼容:
- 问题描述:如果加载模型时报错,可能是由于保存的模型与当前环境的PyTorch版本不兼容。
- 解决方案:可以尝试升级或降级PyTorch版本,或者检查保存和加载模型时使用的PyTorch版本是否一致。
-
键不匹配:
- 问题描述:在使用
torch.load ()加载模型时,如果模型的键不匹配,会导致加载失败。 - 解决方案:可以使用
strict=False参数进行加载,这样即使键不匹配,也会忽略不匹配的键,继续加载其他键对应的值。
- 问题描述:在使用
-
包含
nn.DataParallel的模型:- 问题描述:在单GPU环境下使用
nn.DataParallel包装的模型时,加载时可能会出错。 - 解决方案:确保加载的模型与保存的模型具有相同的结构。可以通过查看模型的结构和保存的
state_dict的键来进行对比,确保没有不匹配的部分。
- 问题描述:在单GPU环境下使用
-
加载PKL模型:
- 问题描述:在使用PyTorch加载PKL模型时,有时可能会遇到模型加载结果与预期不符的情况。
- 解决方案:需要明确为什么会出现这种问题,并根据具体情况进行调整。
-
预训练模型权重加载:
- 问题描述:在加载包含预训练模型权重时,可能会出现调用权重出错的情况。
- 解决方案:在初始化预训练模型层时,确保正确加载其预训练权重。
-
多GPU环境下的模型加载:
- 问题描述:在单GPU环境下使用
nn.DataParallel包装模型时,可能会导致加载失败。 - 解决方案:在单GPU环境下使用
nn.DataParallel包装模型时,可以尝试将模型转换为单GPU模型后再进行加载。
- 问题描述:在单GPU环境下使用
具体示例
1.Tensor操作
Tensor是PyTorch中最基本的数据结构,类似于NumPy的数组,但可以在GPU上运行加速计算。
示例:创建和操作Tensor
import torch
# 创建一个零填充的Tensor
x = torch.zeros(3, 3)
print(x)
# 加法操作
y = torch.ones(3, 3)
z = x + y
print(z)
# 在GPU上创建Tensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.zeros(3, 3, device=device)
print(x)
运行结果: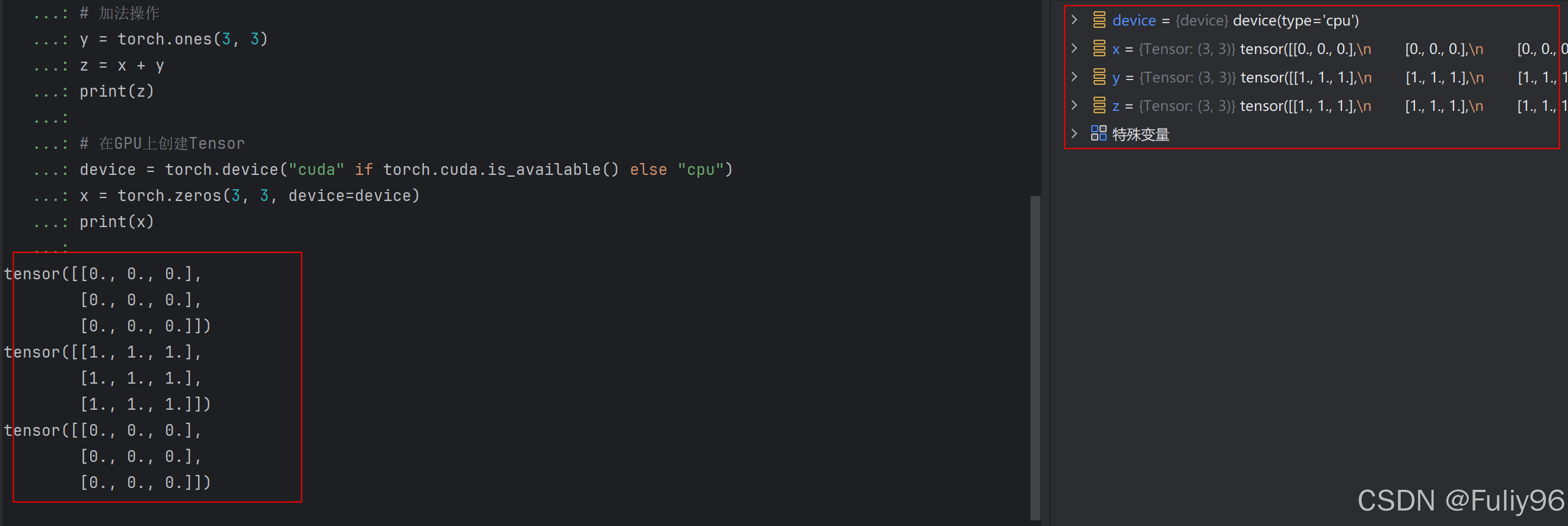
2. nn.Module和自定义模型
nn.Module是PyTorch中定义神经网络模型的基类,所有的自定义模型都应该继承自它。
示例:定义一个简单的全连接神经网络模型
import torch
import torch.nn as nn
# 自定义模型类
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc = nn.Linear(10, 5) # 线性层:输入维度为10,输出维度为5
def forward(self, x):
x = self.fc(x)
return x
# 创建模型实例
model = SimpleNet()
print(model)
运行结果:

3. DataLoader和Dataset
DataLoader用于批量加载数据,Dataset定义了数据集的接口,自定义数据集需继承自它。
示例:加载自定义数据集
import torch
from torch.utils.data import Dataset, DataLoader
# 自定义数据集类
class CustomDataset(Dataset):
def __init__(self, data, targets):
self.data = data
self.targets = targets
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x = self.data[index]
y = self.targets[index]
return x, y
# 假设有一些数据和标签
data = torch.randn(100, 10) # 100个样本,每个样本10维
targets = torch.randint(0, 2, (100,)) # 100个随机标签,0或1
# 创建数据集实例
dataset = CustomDataset(data, targets)
# 创建数据加载器
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 打印一个batch的数据
for batch in dataloader:
inputs, labels = batch
print(inputs.shape, labels.shape)
break
运行结果:

4. 优化器和损失函数
优化器用于更新模型参数以减少损失,损失函数用于计算预测值与实际值之间的差异。
示例:使用优化器和损失函数
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型(假设已定义好)
model = SimpleNet()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 前向传播、损失计算、反向传播和优化过程请参考前面完整示例的训练循环部分。
运行结果:
5. nn.functional中的函数
nn.functional提供了各种用于构建神经网络的函数,如激活函数、池化操作等。
示例:使用ReLU激活函数
import torch
import torch.nn.functional as F
# 创建一个Tensor
x = torch.randn(3, 3)
# 使用ReLU激活函数
output = F.relu(x)
print(output)
运行结果:

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











