






目录
一、实验目的
使用 CIFAR10 数据集作为训练和测试数据,使用 pytorch 作为深度学习框架,实 现一个简单的实用神经网络。(P.81)
二、实验原理
2.1 cifar10数据集
CIFAR-10数据集是一个广泛应用于机器学习和计算机视觉领域的标准数据集,该数据集常用于教学和初学者理解计算机视觉及深度学习的基础, 如:基础物体的识别任务。
cifar10数据集内容包括:
图像尺寸:每张图片的分辨率为32x32像素,采用RGB三通道彩色格式。
类别:包含10个类别,分别是飞机、汽车、鸟类、猫、鹿、狗、青蛙、船和卡车。
数量:总共有60,000张图像,分为50,000张训练图像和10,000张测试图像,每个类别均有相同数量的图像(训练集每类5,000张,测试集每类1,000张)。
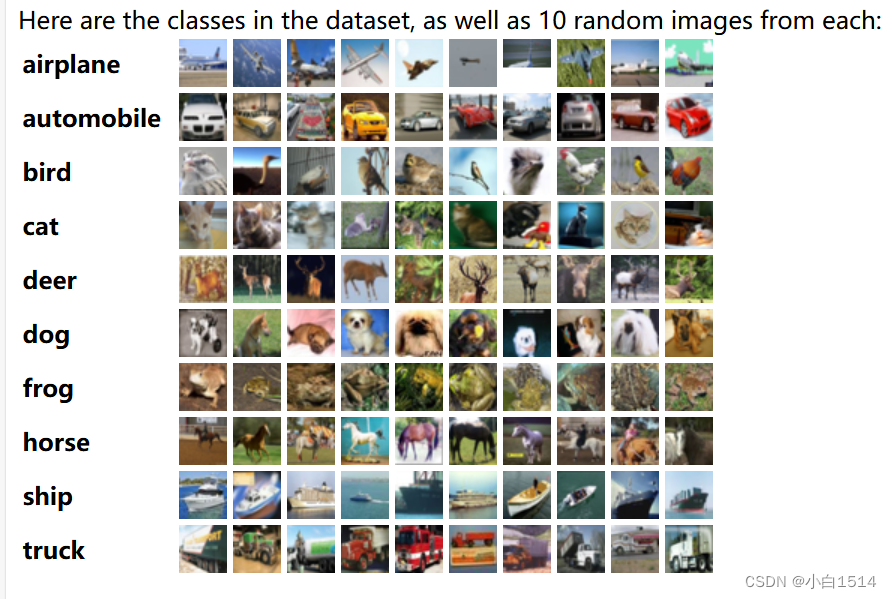
cifar10 Dataset
2.2 卷积神经网络(CNN)
CNN的基本功能实现源于数学的卷积计算,一般对图像进行滤波或者对噪声进行处理时,会采用固定的卷积核进行相关计算处理,但是对于这种大量数据的处理中,使用数据去训练学习卷积核的参数是一种更优的解决问题的方式。
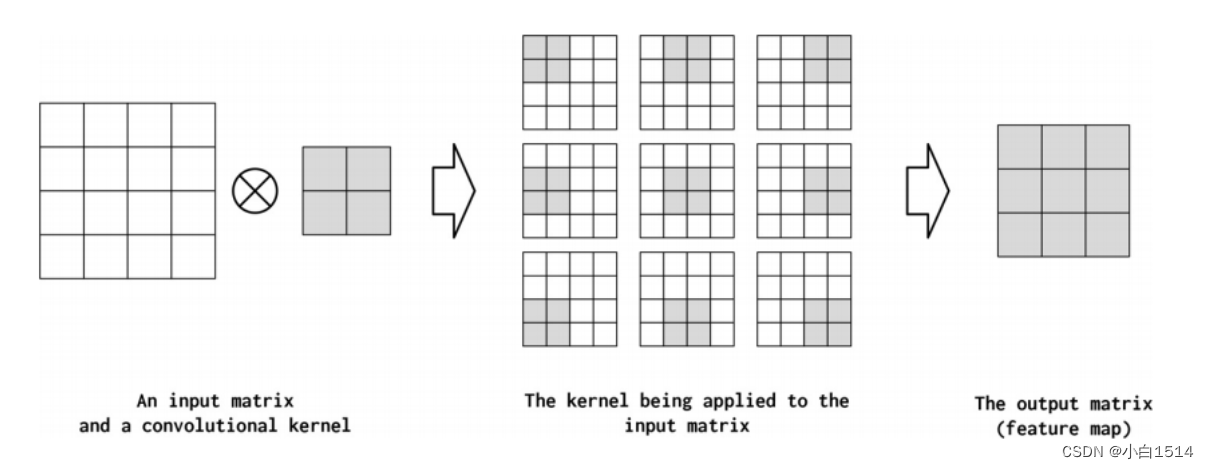
卷积的计算思想
将输入矩阵与卷积核进行卷积运算,我们可以得到特征映射后的输出矩阵,其中卷积核的大小,与输入矩阵相乘的位置(上图是每个位置都进行一次相乘),输出矩阵的大小都可以经过一些超参数来进行调控。
由此可以看出,卷积神经网络是一种非常适合检测空间子结构(并因此创建有意义的空间子结构)的神经网络。CNN通过使用少量的权重(卷积核)来扫描输入数据张量来实现这一点,即通过不断优化的卷积核提取任务所需的相关特征。通过这种扫描,它们可以减少输出的尺寸,提取数据中最关键的特征,用更少的参数量来实现更多运算和模型训练以及更精确的模型学习。

CNN 模型实例——VGG16
三、实验内容
3.1 数据预处理
由于本次实验中CNN模型读取的文件格式为npy文件,下载的cifar10数据集需要转换形式(从可以用Python处理的文件转换为npy文件)
import pickle
import numpy as np
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def convert_to_npy():
# 训练数据
train_data = np.zeros((50000, 3, 32, 32), dtype=np.uint8)
train_labels = np.zeros(50000, dtype=np.uint8)
for i in range(1, 6):
batch_file = f'cifar-10-python/cifar-10-batches-py/data_batch_{i}'
data_dict = unpickle(batch_file)
train_data[(i - 1) * 10000:i * 10000] = data_dict[b'data'].reshape((-1, 3, 32, 32))
train_labels[(i - 1) * 10000:i * 10000] = data_dict[b'labels']
# 测试数据
test_file = 'cifar-10-python/cifar-10-batches-py/test_batch'
test_dict = unpickle(test_file)
test_data = test_dict[b'data'].reshape((-1, 3, 32, 32))
test_labels = test_dict[b'labels']
# 调整数据的形状为 (图片数, 32, 32, 3)
train_data = np.transpose(train_data, (0, 2, 3, 1))
test_data = np.transpose(test_data, (0, 2, 3, 1))
print(train_data.shape)
# 保存为.npy文件
np.save('train_data.npy', train_data)
np.save('train_label.npy', train_labels)
np.save('test_data.npy', test_data)
np.save('test_label.npy', test_labels)
if __name__ == "__main__":
convert_to_npy()
print("Conversion completed.")
convert_to_npy
# 定义Dateset类
class CIFAR10Dataset(torch.utils.data.Dataset):
def __init__(self, transform, data, label):
# 调用父类的构造函数
super(CIFAR10Dataset, self).__init__()
self.transform = transform # 设置属性的transform
self.images = data # 假设data的shape为(图片数,32,32,3),数据类型为np.uint8,值域为[0,255]
self.labels = label # 假设label的shape为(图片数,),pytorch会在计算交叉熵后自动转换为onehot编码
def __getitem__(self, idx):
img = self.images[idx]
img = self.transform(img)
label = self.labels[idx]
return img, label
def __len__(self):
return len(self.images)
# 定义transform:包括两个顺序步骤
# 1.将numpy数组转换为pytorch张量
# 2.归一化到[-0.5,0.5],有利于ReLU函数处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
train_data = np.load('train_data.npy')
train_label = np.load('train_label.npy')
test_data = np.load('test_data.npy')
test_label = np.load('test_label.npy')
# trainset是一个CIFAR10Dataset实例,可以用下标索引
# 下标索引会返回一个实例的data和label
trainset = CIFAR10Dataset(
transform=transform,
data=train_data,
label=train_label
)
# Pytorch提供的DataLoader可以方便控制batch_size和shuffle
# 并提供异步接口
# 出现异步问题,设置num_workers = 0
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=BACTHSIZE,
shuffle=True, num_workers=0
)
testset = CIFAR10Dataset(transform=transform, data=test_data, label=test_label)
testloader = torch.utils.data.DataLoader(testset, batch_size=BACTHSIZE, shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'borse', 'ship', 'truck')
通过创建自定义的`Dataset`类实例,将`.npy`文件中存储的数据加载并转换成(data, label)的格式,其中data代表特征数据,label代表对应的类别标签。随后,利用`DataLoader`类对构造好的训练集和测试集进行批次处理(batching),并可在此过程中实施数据 shuffle 操作以增强模型的泛化能力,同时设置合适的批量大小(batch size)以优化GPU的使用和模型训练速度,从而完成了数据预处理流程,为后续的模型训练准备好成批次的数据。
3.2 构建CNN模型
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from tqdm import tqdm
# 继承一个nn.Module,实现构造函数和forward方法
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 二维卷积,输入通道3,输出通道6,卷积核大小5*5
self.conv1 = nn.Conv2d(3, 6, 5, padding=2)
self.pool1 = nn.AvgPool2d(2, 2)
self.pool2 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5, padding=2)
self.conv3 = nn.Conv2d(16, 32, 5, padding=2)
self.conv4 = nn.Conv2d(32, 64, 5, padding=2)
self.fc1 = nn.Linear(64 * 4 * 4, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 96)
self.fc4 = nn.Linear(96, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool1(F.relu(self.conv2(x)))
x = self.pool2(F.relu(self.conv3(x)))
x = F.relu(self.conv4(x))
# view函数进行reshape操作
x = x.view(-1, 64 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
# 实例化一个神经网络
net = Net()
print(net) # 打印模型结构
cifar_net = torch.load("cifar_net.pth")
# print(cifar_net) # 打印出模型结构及参数经过一系列细致的模型调整与优化尝试,建立了一个卷积神经网络模型,它有4个卷积层和3个池化层。池化层包括最大池化和平均池化,有助于减少特征图尺寸并保留重要信息,提高了模型泛化性能。所有卷积层使用ReLU激活函数增加网络非线性。之后,模型连接了4个全连接层,用于从提取的特征中进行分类。这种结构平衡了模型的深度与宽度,有效提升了训练效果和预测准确性。
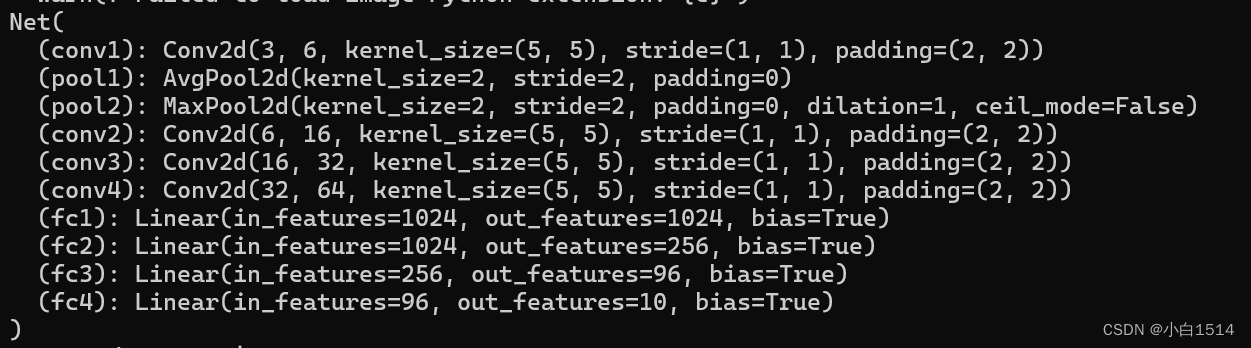
模型结构
3.3 训练模型
BACTHSIZE = 8
EPOCH = 30
net = Net().cuda() # 神经网络模型放至GPU上
criterion = nn.CrossEntropyLoss()
# Stochastic Gradient Descent
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 添加变量用于累积损失和正确预测数
running_loss = 0.0
running_corrects = 0.0
# 初始化空列表来保存每个epoch的损失和精度
epoch_losses = []
epoch_accs = []
for epoch in range(EPOCH):
for i, data in enumerate(tqdm(trainloader, desc=f"Epoch {epoch + 1}/30", unit="batch")):
inputs, labels = data
# 如果使用GPU
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 累积损失和正确预测数
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 计算平均损失和准确率
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = running_corrects.double() / len(trainloader.dataset)
print(f'Train Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
epoch_losses.append(epoch_loss) # 保存每一轮的loss
epoch_accs.append(epoch_acc) # 保存每一轮的loss
# 重置累积变量
running_loss = 0.0
running_corrects = 0
# 在每个epoch后保存模型(这部分可以根据需要调整保存频率)
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
# 训练完成后,使用matplotlib绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(range(1, EPOCH + 1), epoch_losses, label='Training Loss')
plt.plot(range(1, EPOCH + 1), [acc*100 for acc in epoch_accs], label='Training Accuracy', color='green')
plt.title('Training Loss and Accuracy per Epoch')
plt.xlabel('Epoch')
plt.ylabel('Loss / Accuracy (%)')
plt.legend()
plt.savefig('Training Loss and Accuracy per Epoch')
plt.show()EPOCH = 30


EPOCH = 60
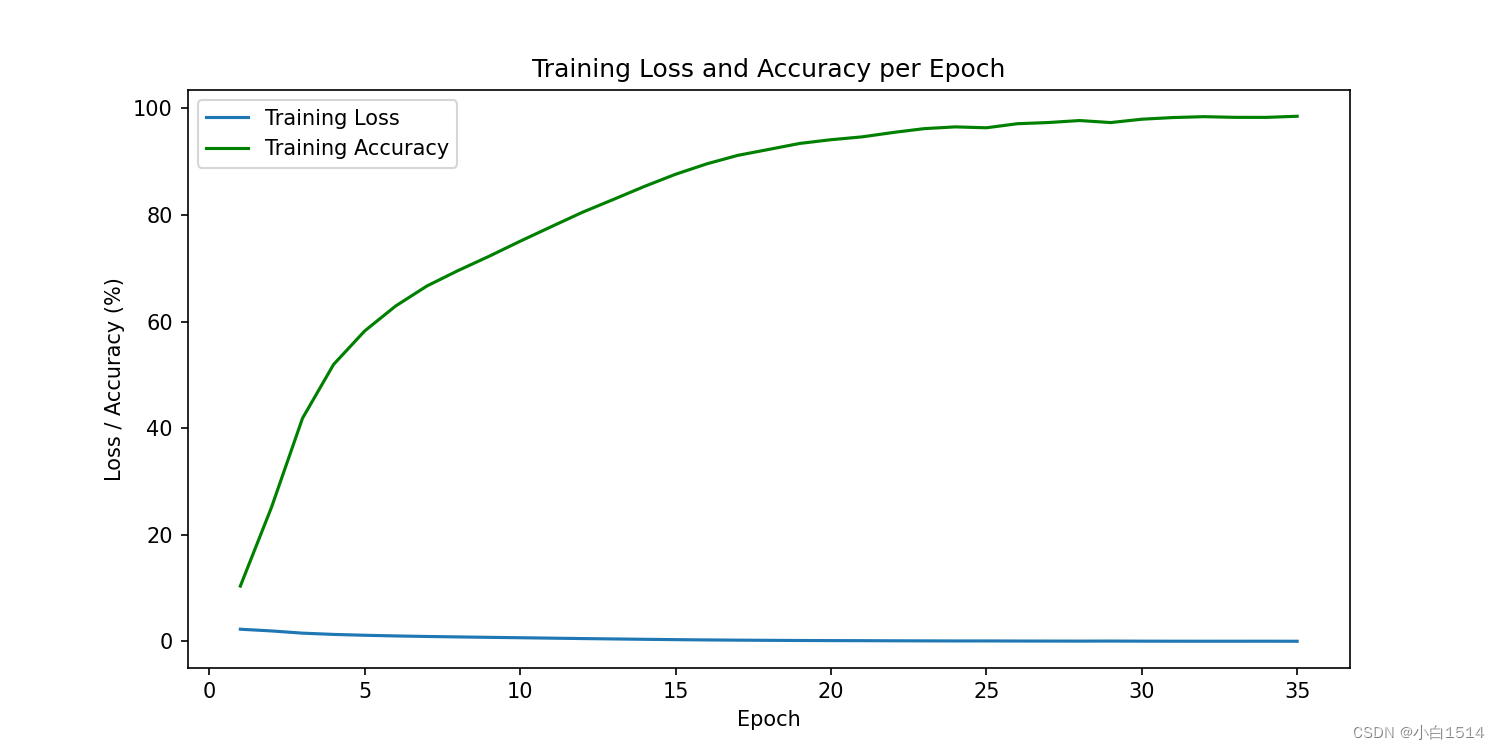
Training Loss and Accuracy per Epoch

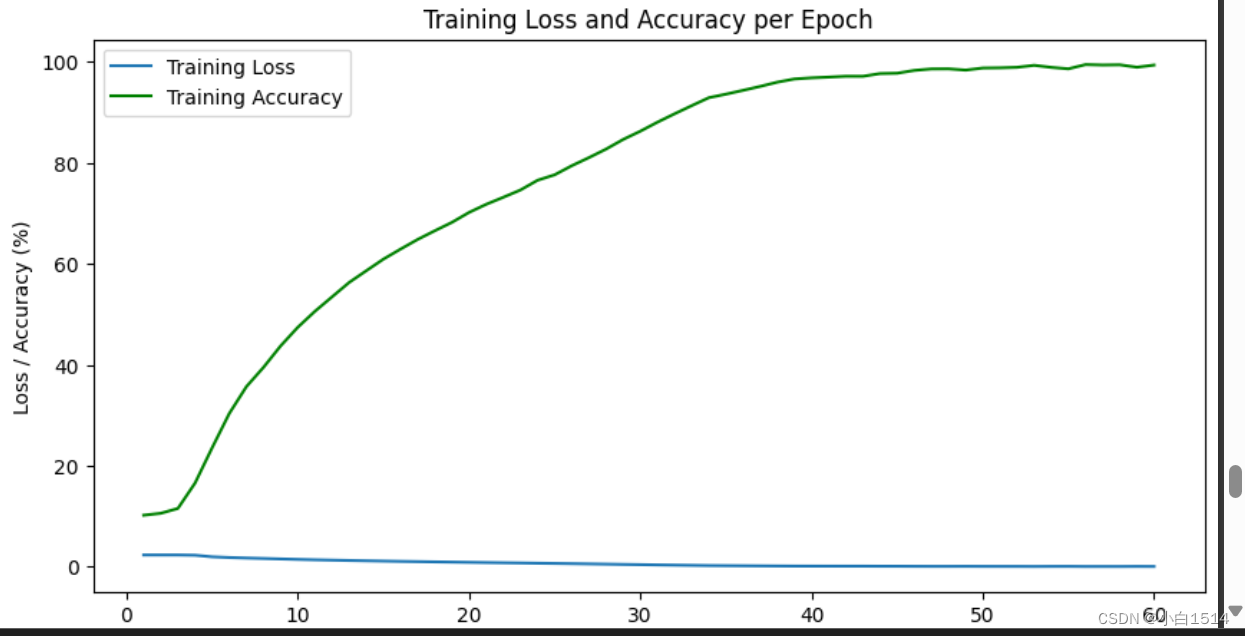
Training Loss and Accuracy per Epoch
经过多次训练,可以发现模型在30轮左右已经可以达到较为不错的效果,模型的批次可以根据GPU的大小来确定(此处设为8)。每一轮训练中,损失值(Loss)呈现出平缓而持续的下降态势,表明模型可以学习到更准确地解析和预测数据;同时,准确率持续上升,证明了模型泛化能力强,能有效抓取关键特征并作出正确分类,如上图所示。
在上述模型的基础上加上批归一化、dropout层(模型精确率比上个模型提升许多)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1) # 增加初始卷积层的输出通道数
self.bn1 = nn.BatchNorm2d(16) # 添加批量归一化
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.pool2 = nn.MaxPool2d(2, 2) # 统一使用最大池化
self.conv3 = nn.Conv2d(32, 64, 3, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.pool3 = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout2d(0.5) # 添加Dropout
self.conv4 = nn.Conv2d(64, 128, 3, padding=1)
self.bn4 = nn.BatchNorm2d(128)
self.fc1 = nn.Linear(128 * 4 * 4, 1024) # 调整全连接层的大小
self.bn_fc1 = nn.BatchNorm1d(1024)
self.dropout2 = nn.Dropout(0.5)
self.fc2 = nn.Linear(1024, 256)
self.bn_fc2 = nn.BatchNorm1d(256)
self.dropout3 = nn.Dropout(0.2)
self.fc3 = nn.Linear(256, 96)
self.bn_fc3 = nn.BatchNorm1d(96)
self.fc4 = nn.Linear(96, 10)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.pool1(x)
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool2(x)
x = F.relu(self.bn3(self.conv3(x)))
x = self.pool3(x)
x = self.dropout1(x)
x = F.relu(self.bn4(self.conv4(x)))
x = x.view(-1, 128 * 4 * 4)
x = F.relu(self.bn_fc1(self.fc1(x)))
x = self.dropout2(x)
x = F.relu(self.bn_fc2(self.fc2(x)))
x = self.dropout3(x)
x = F.relu(self.bn_fc3(self.fc3(x)))
x = self.fc4(x)
return x
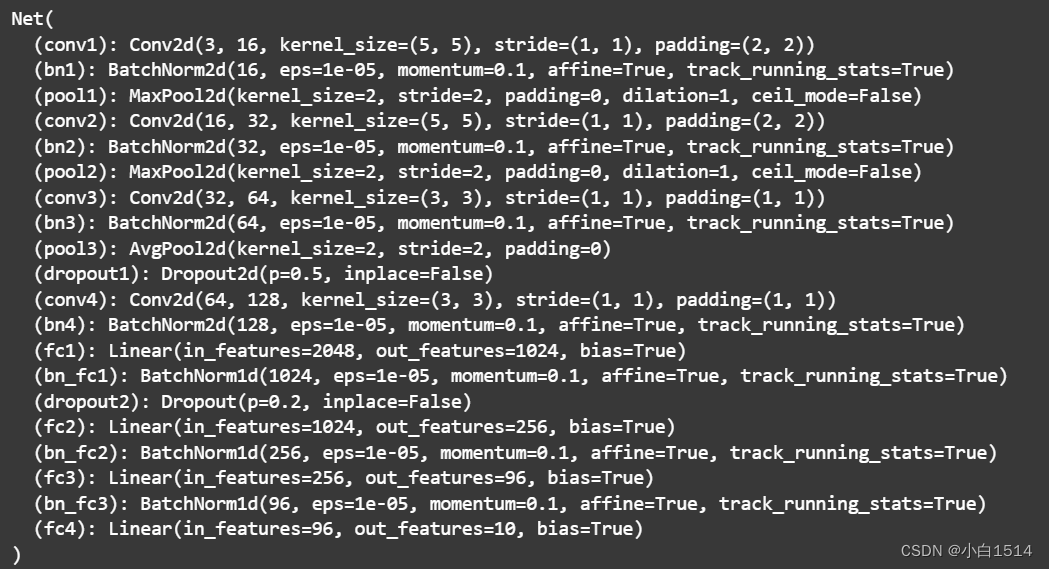
模型结构


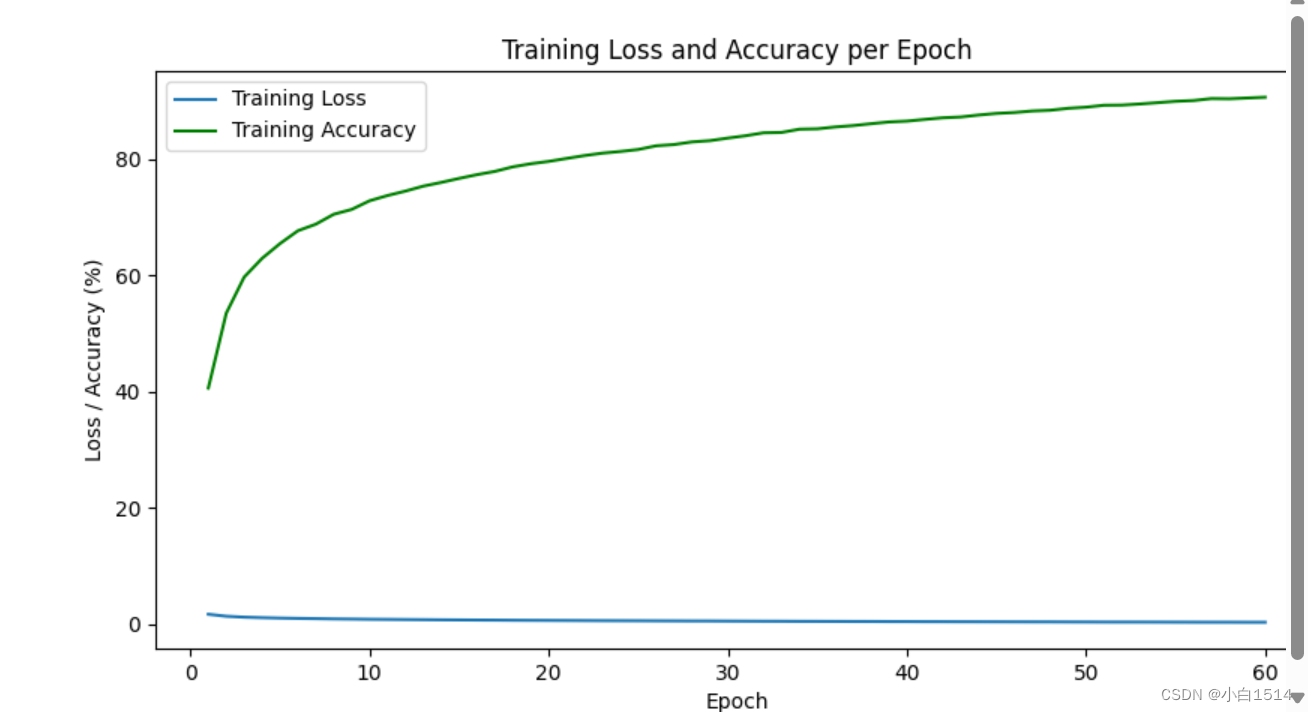
Training Loss and Accuracy per Epoch
3.4 模型测试及精度
net = Net()
batchsize = 8
# 加载之前训好的模型参数
net.load_state_dict(torch.load(PATH))
# 建立列表统计正确个数和总数
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
net.eval() # 设置为评估模式,关闭dropout等
# 使用tqdm遍历测试集并计算准确率
with torch.no_grad():
for data in tqdm(testloader, desc="Testing", unit="batch"):
images, labels = data
# 如果使用GPU
# images, labels = images.cuda(), labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
# 更新统计信息
for i in range(batchsize):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
# 打印每个类别的准确率
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))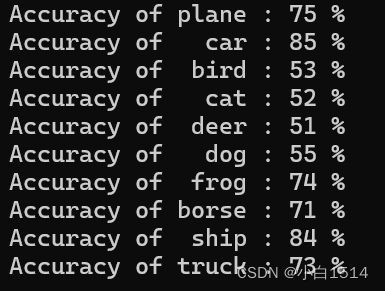
第一个模型的分类准确率
通过观察测试集的结果,我发现模型的整体准确率稳定在大约70%左右,这一指标明确表示模型具备较好的泛化能力,能够在未见过的数据上展现出良好的预测性能。但是,我还是可以观察到训练集上的准确率略高于测试集,两者之间存在一定的差距,这说明模型依旧可能存在轻微的过拟合现象。
之后我采用了新的模型结构进行训练,得到了精确率提高了很多的模型,大致准确率稳定在80%左右,进步提高了模型的泛化能力。

第二个模型的分类准确率
四、实验总结
本实验围绕CIFAR-10数据集的图像分类任务展开,重点采用了一种结合卷积层与全连接层的经典卷积神经网络(CNN)模型。实验全过程覆盖了数据预处理、模型构建、训练、验证及测试等多个关键环节,以下是主要总结:
-
数据预处理:实验起始于对CIFAR-10数据集的基本处理,包括数据的加载、归一化处理,以及将图像和标签组织为PyTorch的
Dataset实例。为了加速训练并提高模型泛化能力,我对数据进行了打乱和分区,划分为训练集和测试集。通过DataLoader对数据进行批次处理,便于模型训练期间的高效迭代。 -
模型架构:设计的卷积神经网络模型结合了多层卷积层以捕捉局部特征,伴随有最大池化(MaxPooling)层和平均池化(AvgPooling)层用于降维和保持重要信息。卷积层之后紧跟着几个全连接层,用于将学到的特征映射到最终的类别预测。ReLU激活函数被广泛应用于各层以引入非线性,增强模型表达能力。
-
训练与验证:模型训练阶段,我采用了梯度下降优化器(Adam)配合交叉熵损失函数进行参数优化。通过多个训练周期(epoch=30),模型在训练集上逐步学习并调整权重,以最小化损失值。同时,在独立的测试集上进行验证,确认模型的泛化性能,判断模型是否过拟合。
-
性能评估:实验结果显示,模型在训练集上达到了较高的准确率,约70%左右,同时在测试集上也能维持相近的表现,虽略有下降,但证明了模型具备一定泛化能力。
本次实验成功地利用卷积+全连接模型在CIFAR-10数据集上实现了图像分类,验证了CNN模型在处理复杂图像识别任务方面的强大效能。在实验进行过后,通过总结问题所在,我发现之后应考虑模型复杂度,如更深的网络结构、更先进的优化策略,以及针对过拟合问题应该实施的措施,如实施数据增强策略和正则化技术,以确保模型在未见过的数据上仍能保持高精度预测。
















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











