






目录
一、实验目的
使用 CIFAR100 数据集作为训练和测试数据,使用 pytorch 作为深度学习框架, 实现基于 ResNet18 的图像分类。(P.125)
二、实验原理
2.1 cifar100数据集
内容:
CIFAR-100数据集是计算机视觉领域中一个广泛使用的图像分类数据集,它是CIFAR-10数据集的一个扩展版本,主要面向更细致的图像分类任务。
CIFAR-100包含60,000张彩色图像,分为100个类别,每个类别有600张图片,其中500张用于训练,100张用于测试。每张图像的尺寸是32x32像素,RGB三通道。它的图像内容多样,涵盖了自然界的物体、人造物品、抽象概念等,相比CIFAR-10(主要包含动物和交通工具等10大类),CIFAR-100的分类任务更具挑战性,因为类别更多且更加细分。
用处:
CIFAR-100经常被用于评估图像分类算法,它的复杂性和多样性使其成为测试新模型架构、优化算法的理想数据集,尤其是对于深度学习模型的性能。另外,模型在CIFAR-100上预训练后,可以迁移到其他相关的图像识别任务上,利用学到的特征提高新任务的学习效率。
由于其规模适中且具有挑战性,CIFAR-100可以作为计算机视觉学习课程中的教学案例或作为学术竞赛的基础数据集,帮助学生和研究人员实践和理解深度学习的原理与应用。

cifar100 数据集类别结构
2.2 ResNet18
ResNet,由何凯明等人在2015年提出,解决了深度神经网络训练中的梯度消失和梯度爆炸问题,使得神经网络深度能够进一步加深,达到成百上千层。
传统的神经网络是通过堆叠多个层来学习从输入到输出的复杂映射关系,而随着网络深度的增加,训练难度会急剧上升,因为梯度在反向传播过程中容易变得非常小或消失。ResNet的核心思想是通过引入残差学习框架,使得网络能够延缓(不是避免)梯度消失问题的到来,使得网络能够优化极深的网络结构。
残差学习的基础模块是残差块,每个残差块由两部分组成:一个或多个卷积层,以及一个残差连接(skip connection)。残差连接直接将输入传递到块的末尾,与经过若干卷积层变换后的信号相加。这样,网络学习的是输入和经过几层变换后的信号之间的残差(即差异),而不是直接学习整个变换。数学公式表示为:
𝑥 是输入,经卷积层变换后的输出是 𝐹(𝑥),残差块输出 𝑦。
ResNet18模型结构:(ResNet18在ResNet家族中是较为轻量的模型)
-
输入层:网络以一个7x7的卷积层开始,后面跟着一个最大池化层,用于初步降低输入图像的空间尺寸。
-
残差模块:接下来,网络由4个残差模块组成,每个模块包含多个残差块。每个模块的开始会先通过一个下采样(strided convolution)或池化层减半特征图的尺寸,然后跟随多个残差块(在ResNet18中,前两个残差模块各有2个残差块,后两个残差模块各有2个带下采样残差块和1个残差块)。
-
残差块:基本残差块包含两个3x3的卷积层,每层之后都有批量归一化(Batch Normalization)和ReLU激活函数。第一个卷积层后面有时会跟一个下采样操作,以改变特征图的尺寸。
-
输出层:最后,通过全局平均池化层将特征图转换为一个向量,然后通过一个全连接层进行分类。
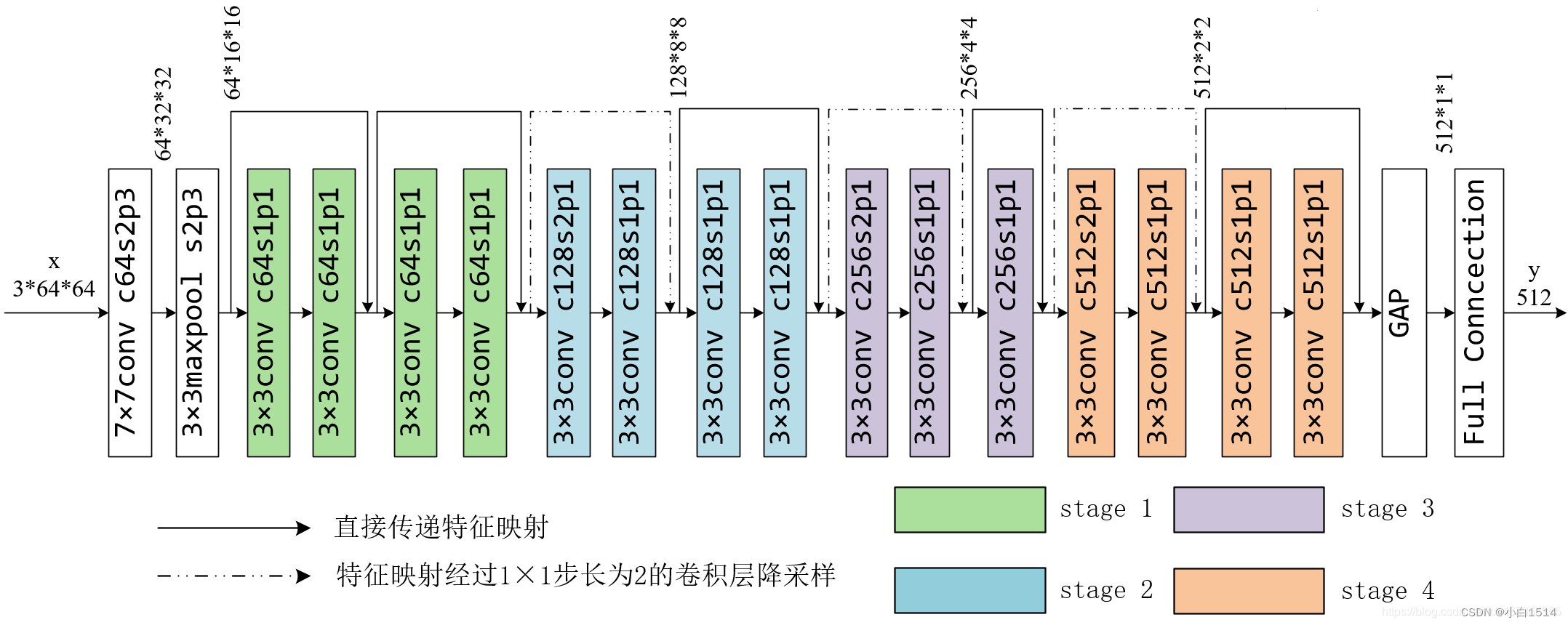
ResNet18网络结构
三、实验内容
3.1 环境配置
环境采用阿里云的人工智能平台,可以调用较大的GPU显卡进行加速训练。

3.2 数据预处理
def get_training_dataloader(mean, std, batch_size=16, num_workers=2, shuffle=True):
""" return training dataloader
Args:
mean: mean of cifar100 training dataset
std: std of cifar100 training dataset
path: path to cifar100 training python dataset
batch_size: dataloader batchsize
num_workers: dataloader num_works
shuffle: whether to shuffle
Returns: train_data_loader:torch dataloader object
"""
transform_train = transforms.Compose([
#transforms.ToPILImage(),
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
#cifar100_training = CIFAR100Train(path, transform=transform_train)
cifar100_training = torchvision.datasets.CIFAR100(root= os.path.join('cifar100','train'),train=True, download=True, transform=transform_train)
cifar100_training_loader = DataLoader(
cifar100_training, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)
return cifar100_training_loader
def get_test_dataloader(mean, std, batch_size=16, num_workers=2, shuffle=True):
""" return training dataloader
Args:
mean: mean of cifar100 test dataset
std: std of cifar100 test dataset
path: path to cifar100 test python dataset
batch_size: dataloader batchsize
num_workers: dataloader num_works
shuffle: whether to shuffle
Returns: cifar100_test_loader:torch dataloader object
"""
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
#cifar100_test = CIFAR100Test(path, transform=transform_test)
cifar100_test = torchvision.datasets.CIFAR100(root= os.path.join('cifar100','val'), train=False, download=True, transform=transform_test)
cifar100_test_loader = DataLoader(
cifar100_test, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)
return cifar100_test_loader
一组图片样本
3.3 模型搭建
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
#BasicBlock and BottleNeck block
#have different output size
#we use class attribute expansion
#to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
"""Residual block for resnet over 50 layers
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=100):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
#we use a different inputsize than the original paper
#so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make resnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a resnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.avg_pool(output)
output = output.view(output.size(0), -1)
output = self.fc(output)
return output
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])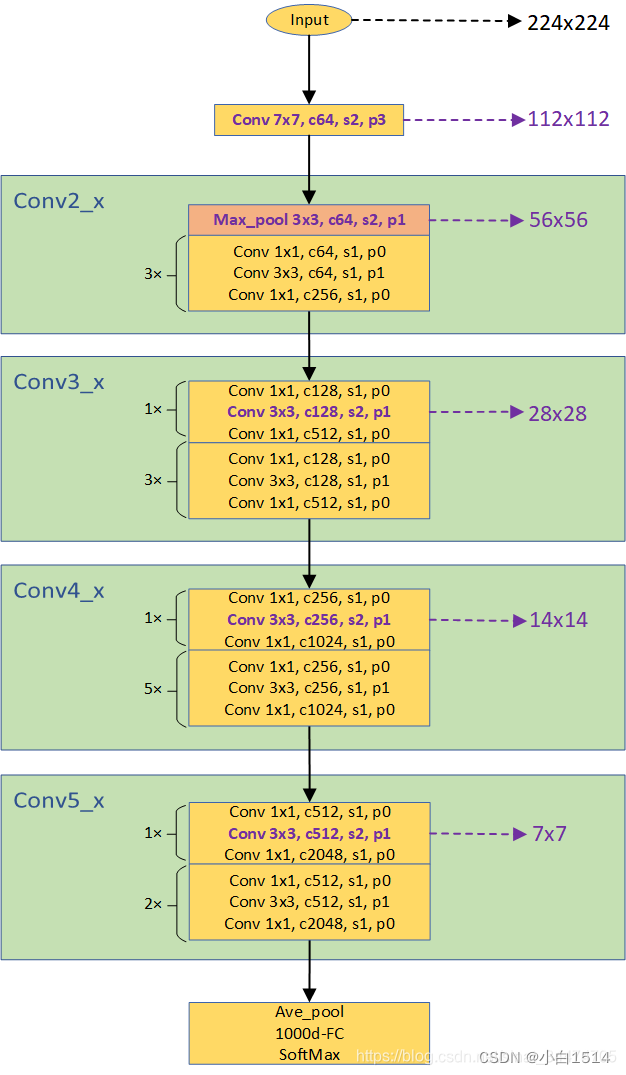
ResNet18 结构图
3.4 模型训练
模型训练代码
# train.py
#!/usr/bin/env python3
""" train network using pytorch
author baiyu
"""
import os
import sys
import argparse
import time
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from conf import settings
from utils import get_network, get_training_dataloader, get_test_dataloader, WarmUpLR, \
most_recent_folder, most_recent_weights, last_epoch, best_acc_weights
def train(epoch):
start = time.time()
net.train()
losses = []
for batch_index, (images, labels) in enumerate(cifar100_training_loader):
if args.gpu:
labels = labels.cuda()
images = images.cuda()
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
n_iter = (epoch - 1) * len(cifar100_training_loader) + batch_index + 1
last_layer = list(net.children())[-1]
for name, para in last_layer.named_parameters():
if 'weight' in name:
writer.add_scalar('LastLayerGradients/grad_norm2_weights', para.grad.norm(), n_iter)
if 'bias' in name:
writer.add_scalar('LastLayerGradients/grad_norm2_bias', para.grad.norm(), n_iter)
print('Training Epoch: {epoch} [{trained_samples}/{total_samples}]\tLoss: {:0.4f}\tLR: {:0.6f}'.format(
loss.item(),
optimizer.param_groups[0]['lr'],
epoch=epoch,
trained_samples=batch_index * args.b + len(images),
total_samples=len(cifar100_training_loader.dataset)
))
#update training loss for each iteration
writer.add_scalar('Train/loss', loss.item(), n_iter)
if epoch <= args.warm:
warmup_scheduler.step()
for name, param in net.named_parameters():
layer, attr = os.path.splitext(name)
attr = attr[1:]
writer.add_histogram("{}/{}".format(layer, attr), param, epoch)
finish = time.time()
print('epoch {} training time consumed: {:.2f}s'.format(epoch, finish - start))
@torch.no_grad()
def eval_training(epoch=0, tb=True):
start = time.time()
net.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for (images, labels) in cifar100_test_loader:
if args.gpu:
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
loss = loss_function(outputs, labels)
test_loss += loss.item()
_, preds = outputs.max(1)
correct += preds.eq(labels).sum()
finish = time.time()
if args.gpu:
print('GPU INFO.....')
print(torch.cuda.memory_summary(), end='')
print('Evaluating Network.....')
print('Test set: Epoch: {}, Average loss: {:.4f}, Accuracy: {:.4f}, Time consumed:{:.2f}s'.format(
epoch,
test_loss / len(cifar100_test_loader.dataset),
correct.float() / len(cifar100_test_loader.dataset),
finish - start
))
print()
#add informations to tensorboard
if tb:
writer.add_scalar('Test/Average loss', test_loss / len(cifar100_test_loader.dataset), epoch)
writer.add_scalar('Test/Accuracy', correct.float() / len(cifar100_test_loader.dataset), epoch)
return correct.float() / len(cifar100_test_loader.dataset), test_loss / len(cifar100_test_loader.dataset)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-net', type=str, required=True, help='net type')
parser.add_argument('-gpu', action='store_true', default=False, help='use gpu or not')
parser.add_argument('-b', type=int, default=128, help='batch size for dataloader')
parser.add_argument('-warm', type=int, default=1, help='warm up training phase')
parser.add_argument('-lr', type=float, default=0.1, help='initial learning rate')
parser.add_argument('-resume', action='store_true', default=False, help='resume training')
args = parser.parse_args()
net = get_network(args)
#data preprocessing:
cifar100_training_loader = get_training_dataloader(
settings.CIFAR100_TRAIN_MEAN,
settings.CIFAR100_TRAIN_STD,
num_workers=4,
batch_size=args.b,
shuffle=True
)
cifar100_test_loader = get_test_dataloader(
settings.CIFAR100_TRAIN_MEAN,
settings.CIFAR100_TRAIN_STD,
num_workers=4,
batch_size=args.b,
shuffle=True
)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=settings.MILESTONES, gamma=0.2) #learning rate decay
iter_per_epoch = len(cifar100_training_loader)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * args.warm)
if args.resume:
recent_folder = most_recent_folder(os.path.join(settings.CHECKPOINT_PATH, args.net), fmt=settings.DATE_FORMAT)
if not recent_folder:
raise Exception('no recent folder were found')
checkpoint_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder)
else:
checkpoint_path = os.path.join(settings.CHECKPOINT_PATH, args.net, settings.TIME_NOW)
#use tensorboard
if not os.path.exists(settings.LOG_DIR):
os.mkdir(settings.LOG_DIR)
#since tensorboard can't overwrite old values
#so the only way is to create a new tensorboard log
writer = SummaryWriter(log_dir=os.path.join(
settings.LOG_DIR, args.net, settings.TIME_NOW))
input_tensor = torch.Tensor(1, 3, 32, 32)
if args.gpu:
input_tensor = input_tensor.cuda()
writer.add_graph(net, input_tensor)
#create checkpoint folder to save model
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
checkpoint_path = os.path.join(checkpoint_path, '{net}-{epoch}-{type}.pth')
best_acc = 0.0
if args.resume:
best_weights = best_acc_weights(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
if best_weights:
weights_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder, best_weights)
print('found best acc weights file:{}'.format(weights_path))
print('load best training file to test acc...')
net.load_state_dict(torch.load(weights_path))
best_acc = eval_training(tb=False)
print('best acc is {:0.2f}'.format(best_acc))
recent_weights_file = most_recent_weights(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
if not recent_weights_file:
raise Exception('no recent weights file were found')
weights_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder, recent_weights_file)
print('loading weights file {} to resume training.....'.format(weights_path))
net.load_state_dict(torch.load(weights_path))
resume_epoch = last_epoch(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
epoch_loss = []
epoch_acc = []
for epoch in range(1, settings.EPOCH + 1):
if epoch > args.warm:
train_scheduler.step(epoch)
if args.resume:
if epoch <= resume_epoch:
continue
train(epoch)
acc,loss = eval_training(epoch)
epoch_loss.append(loss)
epoch_acc.append(acc)
#start to save best performance model after learning rate decay to 0.01
if epoch > settings.MILESTONES[1] and best_acc < acc:
weights_path = checkpoint_path.format(net=args.net, epoch=epoch, type='best')
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
best_acc = acc
continue
if not epoch % settings.SAVE_EPOCH:
weights_path = checkpoint_path.format(net=args.net, epoch=epoch, type='regular')
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
writer.close()
plt.figure(figsize=(10, 5))
# 损失曲线
plt.plot(range(1, settings.EPOCH + 1), epoch_loss, label='Test Loss')
plt.plot(range(1, settings.EPOCH + 1), epoch_acc, label='Test Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Test Loss and Accuracy per Epoch')
plt.savefig('Test Loss and Accuracy per Epoch')
plt.legend()
采用本地resnet18模型训练
parser = argparse.ArgumentParser()
parser.add_argument('-net', type=str, required=True, help='net type')
parser.add_argument('-gpu', action='store_true', default=False, help='use gpu or not')
parser.add_argument('-b', type=int, default=128, help='batch size for dataloader')
parser.add_argument('-warm', type=int, default=1, help='warm up training phase')
parser.add_argument('-lr', type=float, default=0.1, help='initial learning rate')
parser.add_argument('-resume', action='store_true', default=False, help='resume training')
args = parser.parse_args()
net = get_network(args)
#data preprocessing:
cifar100_training_loader = get_training_dataloader(
settings.CIFAR100_TRAIN_MEAN,
settings.CIFAR100_TRAIN_STD,
num_workers=4,
batch_size=args.b,
shuffle=True
)
cifar100_test_loader = get_test_dataloader(
settings.CIFAR100_TRAIN_MEAN,
settings.CIFAR100_TRAIN_STD,
num_workers=4,
batch_size=args.b,
shuffle=True
)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=settings.MILESTONES, gamma=0.2) #learning rate decay
iter_per_epoch = len(cifar100_training_loader)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * args.warm)
if args.resume:
recent_folder = most_recent_folder(os.path.join(settings.CHECKPOINT_PATH, args.net), fmt=settings.DATE_FORMAT)
if not recent_folder:
raise Exception('no recent folder were found')
checkpoint_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder)
else:
checkpoint_path = os.path.join(settings.CHECKPOINT_PATH, args.net, settings.TIME_NOW)
#use tensorboard
if not os.path.exists(settings.LOG_DIR):
os.mkdir(settings.LOG_DIR)
#since tensorboard can't overwrite old values
#so the only way is to create a new tensorboard log
writer = SummaryWriter(log_dir=os.path.join(
settings.LOG_DIR, args.net, settings.TIME_NOW))
input_tensor = torch.Tensor(1, 3, 32, 32)
if args.gpu:
input_tensor = input_tensor.cuda()
writer.add_graph(net, input_tensor)
#create checkpoint folder to save model
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
checkpoint_path = os.path.join(checkpoint_path, '{net}-{epoch}-{type}.pth')
best_acc = 0.0
if args.resume:
best_weights = best_acc_weights(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
if best_weights:
weights_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder, best_weights)
print('found best acc weights file:{}'.format(weights_path))
print('load best training file to test acc...')
net.load_state_dict(torch.load(weights_path))
best_acc = eval_training(tb=False)
print('best acc is {:0.2f}'.format(best_acc))
recent_weights_file = most_recent_weights(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
if not recent_weights_file:
raise Exception('no recent weights file were found')
weights_path = os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder, recent_weights_file)
print('loading weights file {} to resume training.....'.format(weights_path))
net.load_state_dict(torch.load(weights_path))
resume_epoch = last_epoch(os.path.join(settings.CHECKPOINT_PATH, args.net, recent_folder))
epoch_loss = []
epoch_acc = []
for epoch in range(1, settings.EPOCH + 1):
if epoch > args.warm:
train_scheduler.step(epoch)
if args.resume:
if epoch <= resume_epoch:
continue
train(epoch)
acc,loss = eval_training(epoch)
epoch_loss.append(loss)
epoch_acc.append(acc.item())
#start to save best performance model after learning rate decay to 0.01
if epoch > settings.MILESTONES[1] and best_acc < acc:
weights_path = checkpoint_path.format(net=args.net, epoch=epoch, type='best')
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
best_acc = acc
continue
if not epoch % settings.SAVE_EPOCH:
weights_path = checkpoint_path.format(net=args.net, epoch=epoch, type='regular')
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
writer.close()
plt.figure(figsize=(10, 5))
# 损失曲线
plt.plot(range(1, settings.EPOCH + 1), epoch_loss, label='Test Loss')
plt.plot(range(1, settings.EPOCH + 1), epoch_acc, label='Test Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Test Loss and Accuracy per Epoch')
plt.savefig('Test Loss and Accuracy per Epoch')
plt.legend()




训练过程
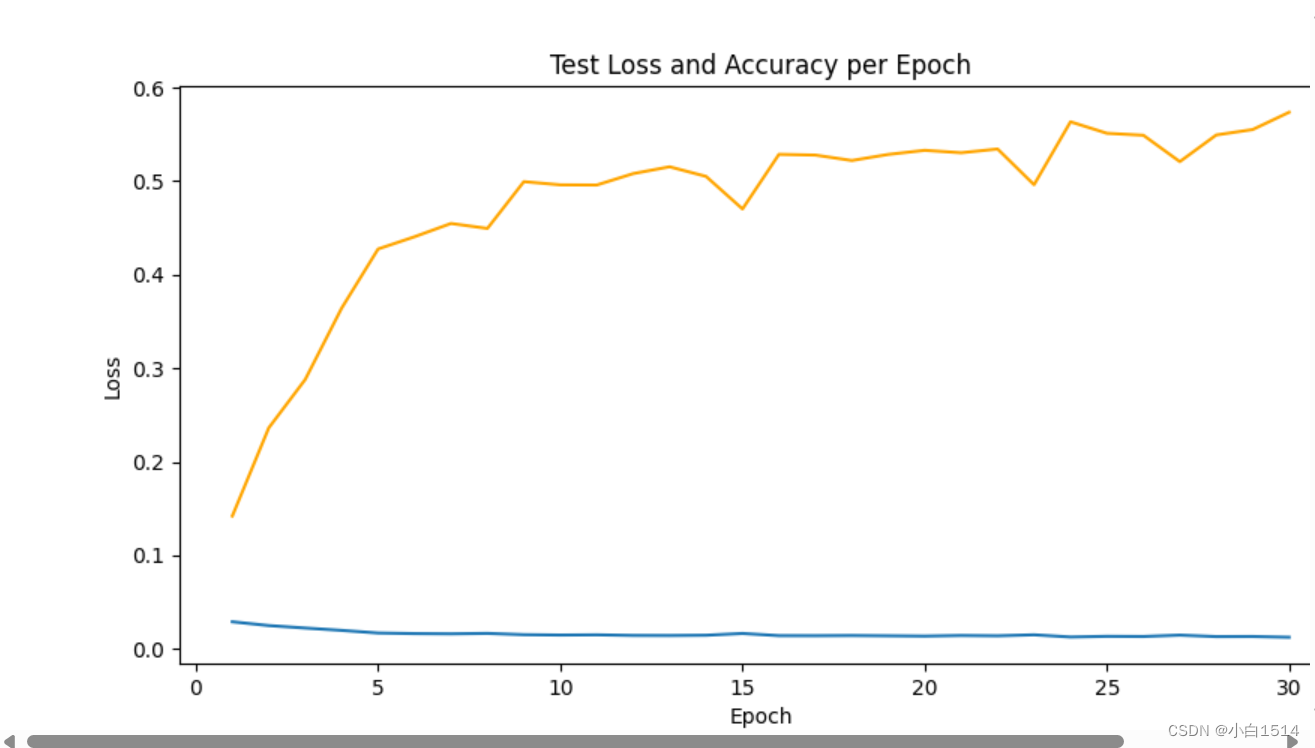
cifar100 - Training loss and Accuracy
epoch=40,batchsize = 16

训练过程
保存模型权重
3.5 模型测试
加载训练好的模型对测试集进行预测,输出类别的分类错误率和参数量。
import argparse
from matplotlib import pyplot as plt
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from conf import settings
from utils import get_network, get_test_dataloader
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-net', type=str, required=True, help='net type')
parser.add_argument('-weights', type=str, required=True, help='the weights file you want to test')
parser.add_argument('-gpu', action='store_true', default=False, help='use gpu or not')
parser.add_argument('-b', type=int, default=16, help='batch size for dataloader')
args = parser.parse_args()
net = get_network(args)
cifar100_test_loader = get_test_dataloader(
settings.CIFAR100_TRAIN_MEAN,
settings.CIFAR100_TRAIN_STD,
#settings.CIFAR100_PATH,
num_workers=4,
batch_size=args.b,
)
net.load_state_dict(torch.load(args.weights))
print(net)
net.eval()
correct_1 = 0.0
correct_5 = 0.0
total = 0
with torch.no_grad():
for n_iter, (image, label) in enumerate(cifar100_test_loader):
print("iteration: {}\ttotal {} iterations".format(n_iter + 1, len(cifar100_test_loader)))
if args.gpu:
image = image.cuda()
label = label.cuda()
print('GPU INFO.....')
print(torch.cuda.memory_summary(), end='')
output = net(image)
_, pred = output.topk(5, 1, largest=True, sorted=True)
label = label.view(label.size(0), -1).expand_as(pred)
correct = pred.eq(label).float()
#compute top 5
correct_5 += correct[:, :5].sum()
#compute top1
correct_1 += correct[:, :1].sum()
if args.gpu:
print('GPU INFO.....')
print(torch.cuda.memory_summary(), end='')
print()
print("Top 1 err: ", 1 - correct_1 / len(cifar100_test_loader.dataset))
print("Top 5 err: ", 1 - correct_5 / len(cifar100_test_loader.dataset))
print("Parameter numbers: {}".format(sum(p.numel() for p in net.parameters())))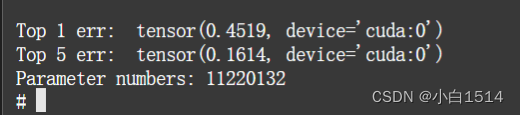
测试结果和参数量(epoch=40,batchsize=40)

测试结果和参数量(epoch=25,batchsize=8)
四、实验总结
4.1 方法总结
-
数据预处理:对CIFAR-100数据集进行了标准化处理,将图像的像素值归一化到[0,1]区间,并进行了数据增强(如随机翻转、裁剪等),以增加模型的泛化能力。
-
模型构建:使用PyTorch框架实现ResNet18模型,该模型包含多个残差块,每个块内部有两层卷积操作,通过残差连接(skip connection)将输入直接与经过若干层变换后的输出相加,简化了学习任务,帮助梯度顺利传播。
-
优化器选择与学习率调整:选用Adam或SGD作为优化器,根据实验情况调整学习率策略,如使用WarmUp学习率调整策略,以在训练过程中动态调整学习率,促进模型收敛。
-
早停与模型保存:设定一个早停的patience值,若验证集准确率在连续几个epoch内没有提升,则提前终止训练,以节省计算资源。同时,在训练过程中保存表现最优的模型权重。
4.2 个人总结
-
残差结构的理解:在处理小尺寸、高维度的图像分类任务时,ResNet能显著提高模型的训练效率和性能。这种结构简化了优化路径,使得模型能够更容易地学习到更深层次的特征表示。
-
数据增强:在处理有限的数据集时,数据增强是提高模型泛化能力的关键。通过简单的操作如旋转、翻转和缩放,能够有效增加模型看到的数据多样性,减少过拟合的风险。
-
调节超参数:从学习率的选择、优化器的决定到早停策略的应用,每一个参数的调整都对最终模型的表现有着直接影响。通过实验,我加深了对学习率策略、优化器作用以及其他超参数的理解。
-
实践中的问题解决:在实际操作过程中遇到了下载速度慢、内存溢出、训练速度慢等问题,通过调整路径、调节批量大小、利用GPU资源以及优化代码结构等方法,我学会了如何高效地解决这些问题。
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











