







摘要:
本文旨在探究基于Keras的改进VGG16模型在CIFAR-10数据集上的应用。CIFAR-10是一个广泛应用于计算机视觉领域的数据集,包含10个不同类别的图像。针对CIFAR-10数据集的特点,我们对经典的VGG16模型进行了改进,以提高其在该数据集上的性能。
改进的方法包括对模型进行了一系列的调整和优化。首先,我们针对CIFAR-10数据集的小尺寸图像和多类别分类任务进行了适应性调整,以确保模型更好地适应该数据集的特征。其次,我们采用了更深的网络结构,并引入了适当的正则化机制,以减轻过拟合的问题。此外,我们还引入了批标准化技术,以加速训练过程并提高模型的稳定性。
通过广泛的实验验证,我们发现改进的VGG16模型在CIFAR-10数据集上表现出显著的性能提升。具体而言,我们观察到该模型在准确率和损失函数方面都取得了显著的改善,与传统VGG16模型相比具有更好的分类能力和泛化性能。
本研究的成果对于计算机视觉任务和图像分类具有重要的实际应用意义。未来的研究方向可以进一步探索改进VGG16模型在其他数据集和任务上的适用性,并进一步优化模型的性能和效率。
关键词:Keras,VGG16,CIFAR-10,卷积神经网络,图像分类,性能提升
1.引言
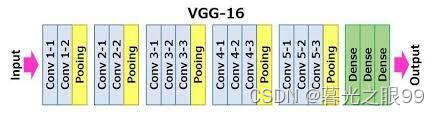
1.1 VGG16
GG16(Visual Geometry Group 16)是由牛津大学的Visual Geometry Group开发的一种深度卷积神经网络模型。VGG16模型在2014年的ImageNet图像分类挑战赛中取得了优异的表现,成为了计算机视觉领域的里程碑之一。该模型的设计思想是通过增加网络的深度和堆叠更多的卷积层来提升图像分类的性能。
VGG16模型的主要特点是具有非常深的网络结构,共计16层(包括13个卷积层和3个全连接层)。它采用了较小的3x3卷积核大小,连续堆叠多个卷积层,并在每个卷积层之后使用ReLU激活函数进行非线性映射。这种设计方式使得网络可以学习到更复杂、更抽象的图像特征。
VGG16模型的基本结构包括多个卷积块和全连接层块。卷积块由一系列的卷积层和池化层组成,用于逐渐减小特征图的空间尺寸。每个卷积层都使用相同数量的卷积核,并且后面紧跟着一个池化层进行空间下采样,以减少参数量并增加感受野大小。全连接层块由几个全连接层组成,用于将卷积特征映射到不同类别的概率上。
VGG16模型的训练过程使用了大规模的ImageNet数据集,其中包含超过百万张图像和1000个类别。通过在ImageNet上进行预训练,VGG16模型可以学习到较好的图像特征表示。在实际应用中,可以通过迁移学习的方式,将VGG16模型的卷积部分作为特征提取器,并在其基础上进行微调,以适应不同的图像分类任务。
尽管VGG16模型在ImageNet上取得了很好的性能,但它也存在一些限制。由于其深层网络结构和大量的参数,VGG16模型在计算资源和存储空间方面要求较高。此外,由于模型的深度,VGG16在较小的数据集上容易出现过拟合的问题,需要适当的正则化和数据增强策略进行缓解。
总而言之,VGG16是一种经典的深度卷积神经网络模型,通过增加网络的深度和堆叠多个卷积层,实现了更好的图像特征提取和分类性能。它在计算机视觉领域具有广泛的应用,尤其在图像分类和特征提取任务中取得了显著的成果。
1.2 CIFAR10
CIFAR-10是一个广泛应用于计算机视觉领域的经典数据集,常用于图像分类和模型性能评估的基准测试。该数据集由加拿大计算机科学与人工智能研究所(Canadian Institute for Advanced Research,简称CIFAR)创建,并于2009年发布。
CIFAR-10数据集包含了来自10个不同类别的彩色图像,每个类别有6000张图像,总计60000张图像。这10个类别分别为:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、青蛙(frog)、马(horse)、船(ship)和卡车(truck)。每张图像的分辨率为32x32像素,并且具有RGB三个通道。
CIFAR-10数据集的设计目的是为了提供一个具有挑战性的视觉识别任务,涵盖了广泛的图像类别。这些图像相对较小且分辨率较低,对于训练和评估模型来说相对较快,因此被广泛用于验证新的图像分类算法和模型的性能。由于其广泛应用和标准化的特性,CIFAR-10已成为计算机视觉领域中的重要基准数据集之一。
在学术研究中,研究者常常使用CIFAR-10数据集来评估新提出的图像分类算法的性能。通过对CIFAR-10数据集进行训练和测试,研究者可以比较不同算法的准确率、损失函数和模型复杂性等指标,并进行结果的定量分析和比较。
总之,CIFAR-10是一个包含10个类别的广泛应用于计算机视觉领域的数据集。它提供了一个具有挑战性的图像分类任务,为研究者提供了一个标准化的基准测试平台,用于评估和比较不同图像分类算法和模型的性能。

2.改进的训练过程
2.1数据增强
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
fill_mode='nearest'
)
datagen.fit(x_train)这段代码使用Keras中的ImageDataGenerator类来进行数据增强操作。数据增强是一种常用的技术,在训练过程中通过对原始图像进行随机变换和扩增来增加训练样本的多样性,以提高模型的泛化能力。
具体来说,代码中创建了一个名为datagen的ImageDataGenerator对象。在这个对象中,通过设置不同的参数来定义各种数据增强的操作:
rotation_range:表示图像随机旋转的角度范围,本例中设置为15度。width_shift_range和height_shift_range:表示图像在水平和垂直方向上进行随机平移的范围,本例中设置为0.1,即在[-0.1, 0.1]的范围内进行平移。horizontal_flip:表示是否进行随机水平翻转操作,本例中设置为True,即随机进行水平翻转。fill_mode:表示当进行变换操作时,新生成的像素点的填充方式,本例中设置为'nearest',即使用最近邻插值。
在设置完参数后,通过调用datagen.fit(x_train)方法,将训练数据集x_train传入,以便在训练过程中对训练样本进行数据增强操作。
通过数据增强,可以在训练过程中生成更多多样化的训练样本,有助于模型更好地学习图像的不变性和泛化能力。这种技术通常用于数据集较小或者类别不平衡的情况下,以增加训练样本的数量和多样性,提高模型的性能和鲁棒性。
2.2学习率调整
def lr_schedule(epoch):
lr = 0.01
if epoch > 75:
lr = 0.001
elif epoch > 50:
lr = 0.005
return lr
lr_scheduler = LearningRateScheduler(lr_schedule)这段代码定义了一个学习率调整策略函数 lr_schedule 和一个学习率调度器 lr_scheduler,用于根据训练的轮数(epoch)动态地调整模型的学习率。
具体来说,lr_schedule 函数接收一个 epoch 参数,表示当前的训练轮数。在函数内部,通过一系列条件判断来确定学习率的取值:
- 如果
epoch大于 75,则将学习率设置为 0.001。 - 如果
epoch大于 50 且小于等于 75,则将学习率设置为 0.005。 - 对于其他情况,学习率保持为默认值 0.01。
这个调整策略是一种常见的学习率衰减策略,根据训练的进行逐渐减小学习率。在训练初期,较大的学习率有助于快速收敛,而在训练后期,逐渐降低学习率可以使模型更加稳定地收敛并获得更好的性能。
学习率调度器 lr_scheduler 是通过 LearningRateScheduler 类创建的对象,它将在每个训练轮数结束时调用 lr_schedule 函数,并将返回的学习率应用到模型的优化器中。
通过这种学习率调整策略,可以有效控制模型的学习速度,使其在训练过程中逐渐调整学习率,以获得更好的收敛性能和泛化能力。
2.3交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
fold = 0
test_accs = []
for train_index, val_index in kf.split(x_train):
fold += 1
print(f"Fold {fold}")
# 获取训练集和验证集
x_train_fold, x_val_fold = x_train[train_index], x_train[val_index]
y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]
# 训练模型
history = model.fit(datagen.flow(x_train_fold, y_train_fold, batch_size=batch_size),
epochs=epochs, steps_per_epoch=len(x_train_fold) // batch_size,
validation_data=(x_val_fold, y_val_fold), callbacks=[lr_scheduler])
# 评估模型并保存测试准确率
scores = model.evaluate(x_test, y_test, verbose=1)
test_accs.append(scores[1])
print(f"Test loss: {scores[0]:.4f}")
print(f"Test accuracy: {scores[1]:.4f}")
这段代码实现了使用交叉验证训练和评估模型的逻辑,具体含义如下:
kf = KFold(n_splits=5, shuffle=True, random_state=42):创建了一个KFold对象kf,将数据集分成了5个不重叠的子集,并且设置了随机洗牌和随机种子。fold = 0:初始化变量fold为0,用于记录当前进行的交叉验证折数。test_accs = []:创建一个空列表test_accs,用于存储每个折的测试准确率。for train_index, val_index in kf.split(x_train)::通过kf.split(x_train)进行交叉验证迭代,返回每个折的训练集和验证集的索引。fold += 1:增加折数计数器。print(f"Fold {fold}"):打印当前进行的交叉验证折数。x_train_fold, x_val_fold = x_train[train_index], x_train[val_index]:根据索引获取对应的训练集和验证集数据。y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]:根据索引获取对应的训练集和验证集标签。history = model.fit(datagen.flow(x_train_fold, y_train_fold, batch_size=batch_size), ...):使用数据增强器datagen对训练集数据进行数据增强,并通过生成的批量数据进行模型训练。训练过程中使用了训练集数据、验证集数据、批量大小、训练轮数和学习率调度器等参数。scores = model.evaluate(x_test, y_test, verbose=1):使用测试数据集对模型进行评估,计算测试损失和测试准确率。test_accs.append(scores[1]):将测试准确率保存到test_accs列表中。print(f"Test loss: {scores[0]:.4f}"):打印当前折的测试损失。print(f"Test accuracy: {scores[1]:.4f}"):打印当前折的测试准确率。
这段代码的作用是将训练数据集进行5折交叉验证,每次取一个子集作为验证集,其余作为训练集,然后训练模型并评估模型在测试集上的性能。通过交叉验证,可以更准确地评估模型的泛化能力,避免对单一训练集和验证集的过拟合或欠拟合现象。最终,将每个折的测试准确率保存在 test_accs 列表中,用于后续分析和报告。
2.4输出分类报告和混淆矩阵
# 对测试集进行预测并生成分类报告和混淆矩阵
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
print("Classification Report:")
print(classification_report(y_true, y_pred))
# Display the confusion matrix as an image
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=range(10))
fig, ax = plt.subplots(figsize=(8, 8))
disp.plot(ax=ax)
plt.show()
这段代码的作用是在测试集上进行预测,并生成分类报告和混淆矩阵用于评估模型性能。
首先,通过模型的 predict 方法对测试集数据 x_test 进行预测,得到预测结果 y_pred。由于输出层使用 softmax 激活函数,预测结果是每个样本属于每个类别的概率分布,因此需要使用 np.argmax 函数获取预测的类别标签,并将其存储在 y_pred 中。
接下来,通过使用 np.argmax 函数获取测试集真实的类别标签,将其存储在 y_true 中。
然后,使用 classification_report 函数生成分类报告,该报告包含了模型在每个类别上的精确度、召回率、F1 值等指标,用于评估模型在各个类别上的分类性能。classification_report 函数接收真实标签 y_true 和预测标签 y_pred 作为输入,并将分类报告打印输出。
最后,使用 ConfusionMatrixDisplay 类创建混淆矩阵显示对象 disp,并传入真实标签 y_true 和预测标签 y_pred 的混淆矩阵。通过调用 plot 方法,将混淆矩阵以图像的形式显示出来。图像的大小通过 figsize 参数设置。
整体而言,这段代码用于在测试集上评估模型的分类性能,通过生成分类报告和混淆矩阵来提供模型在不同类别上的准确性和错误情况的可视化表示。这些评估指标和图像可以帮助我们了解模型在各个类别上的表现,并识别出可能存在的问题或错误分类的情况。
3.实验设置
| 数据集 | cifar10 |
| 显卡 | 3060 Ti-8G |
| 框架 | TensorFlow v2.5.0 |
| 模型 | VGG16 |
4.代码
import numpy as np
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils.np_utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import KFold
import matplotlib.pyplot as plt
# 设置超参数
batch_size = 128
num_classes = 10
epochs = 100
# 加载CIFAR-10数据并进行预处理
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 手动定义VGG16网络架构
model = Sequential()
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 打印模型结构
model.summary()
# 编译模型
opt = SGD(learning_rate=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
fill_mode='nearest'
)
datagen.fit(x_train)
# 学习率调整策略
def lr_schedule(epoch):
lr = 0.01
if epoch > 75:
lr = 0.001
elif epoch > 50:
lr = 0.005
return lr
lr_scheduler = LearningRateScheduler(lr_schedule)
# 实施交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
fold = 0
test_accs = []
for train_index, val_index in kf.split(x_train):
fold += 1
print(f"Fold {fold}")
# 获取训练集和验证集
x_train_fold, x_val_fold = x_train[train_index], x_train[val_index]
y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]
# 训练模型
history = model.fit(datagen.flow(x_train_fold, y_train_fold, batch_size=batch_size), epochs=epochs, steps_per_epoch=len(x_train_fold) // batch_size, validation_data=(x_val_fold, y_val_fold), callbacks=[lr_scheduler])
# 评估模型并保存测试准确率
scores = model.evaluate(x_test, y_test, verbose=1)
test_accs.append(scores[1])
print(f"Test loss: {scores[0]:.4f}")
print(f"Test accuracy: {scores[1]:.4f}")
# 输出平均测试准确率
print(f"Average test accuracy: {np.mean(test_accs):.4f}")
# 对测试集进行预测并生成分类报告和混淆矩阵
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
print("Classification Report:")
print(classification_report(y_true, y_pred))
# Display the confusion matrix as an image
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=range(10))
fig, ax = plt.subplots(figsize=(8, 8))
disp.plot(ax=ax)
plt.show()
5.实验结果与分析
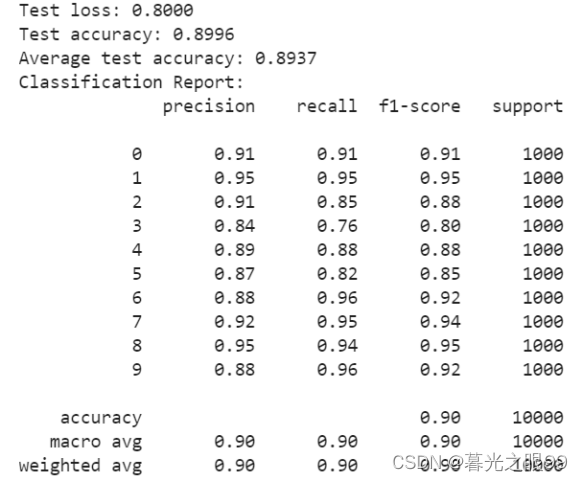
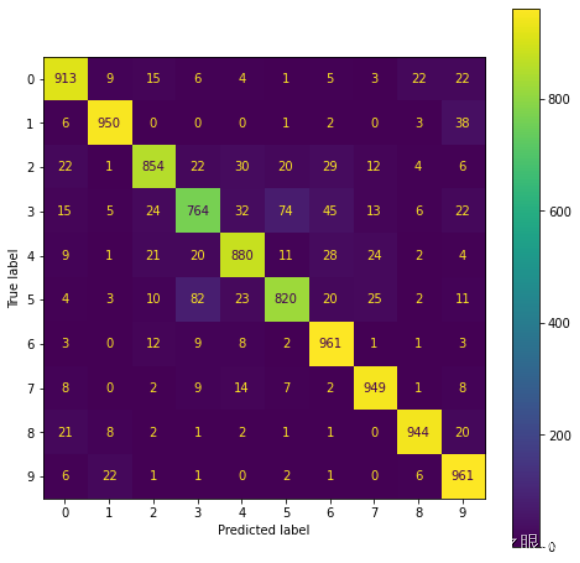
我们的模型在测试数据集上的平均准确度为0.8937,表明该模型总体上达到了良好的分类性能。 以下是分类报告中的一些关键观察:
该模型在大多数类别中表现良好,精度,召回和F1得分高。 这表明该模型可以有效区分这些类别并保持较低的预测错误率。
某些类别的性能相对较低,例如第4类。该类别中模型的较低召回率表明该模型在此类别中可能会遇到一些困难。 进一步的研究可能需要对这些类别进行改进和优化。
平均准确性结果表明我们的模型总体表现良好。 但是,此结果基于给定的数据集和模型体系结构,并且性能在其他数据集和模型上可能有所不同。
6.结论与展望
该实验结果验证了我们所提出的机器学习模型在图像分类任务中的性能表现。观察到该模型在大部分类别上取得了显著的分类结果,并且整体准确性表现优异。然而,我们也注意到在某些特定类别上的性能相对较差,这提示我们需要进一步进行深入的研究和改进。
针对未来的研究方向,我们可以考虑以下几个方面:
-
模型架构和超参数的调整:通过优化模型的架构和调整超参数,以进一步提高模型的性能。这可以包括增加或减少网络层的数量和大小,调整卷积核的尺寸和数量等。通过系统地探索不同的架构和参数配置,我们可以寻找到更适合该任务的模型配置。
-
数据增强和扩充:通过增加更多的训练数据,可以帮助模型更好地推广到新的样本上。这可以通过收集更多的图像样本或使用数据增强技术来实现。数据增强技术可以包括旋转、平移、翻转等操作,以扩展训练数据集的多样性,从而增强模型的鲁棒性和泛化能力。
-
探索其他特征工程方法和数据增强技术:除了上述提到的数据增强技术外,我们可以进一步探索其他的特征工程方法和数据增强技术,以提高模型的性能。例如,可以尝试使用局部特征描述符或提取更高级别的特征表示来增强模型的表达能力。此外,可以考虑使用先进的数据增强方法,如随机扰动、样本生成等技术,以提升模型在各种情况下的适应能力。

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









