







python实现MongoDB数据同步到Elasticsearch
1. 背景
- 引用elasticSearch的百科:https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin
- ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
- 我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题以及可能出现的更多其它问题。
- 关于Elasticsearch的基础教程,可以参考:http://blog.csdn.net/cnweike/article/details/33736429
- **总结:**也就是说,如果想要将mongodb中的数据更好的展示在前端,那么Elasticsearch将是一个非常好的选择。
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- Elasticsearch5.4.2
- Java JDK
- mongodb v3.2
- mongodb可视化工具:mongobooster
3. 同步说明
- 第一步,打开mongoDB的服务:cmd下启动数据库mongod –dbpath=f:/data,通过mongobooster查看确保启动成功。
- 第二步,打开Es服务:双击 E:Elasticsearch5.4.2inelasticsearch.bat,通过浏览器地址:localhost:9200 查看确保启动成功。
- 第三步,要确保执行code能访问到这两个数据库地址: es_url 和 mongo_url,他们在同一个网络,能够互通。
4. 启动相关服务
4.1. 启动mongoDB
- mongod的安装:https://jingyan.baidu.com/article/f3e34a12ac10cef5eb653583.html
- cmd下输入mongod –dbpath=f:/data启动服务。(f:/data是数据的存放地址,而且已设置好环境变量)
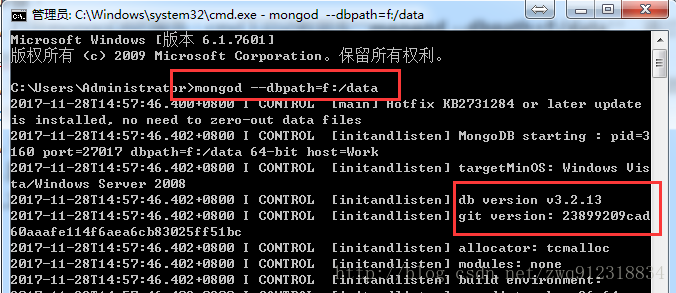
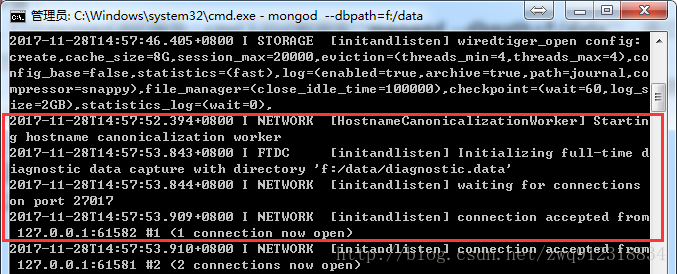
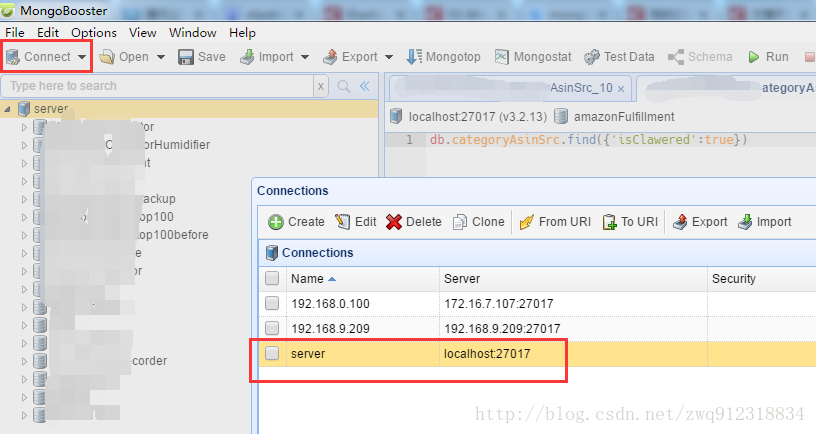
- 进入mongobooster查看数据:
4.2. 启动elasticsearch
- elasticsearch 需要Java 的支持。
- elasticsearch的安装1:https://jingyan.baidu.com/article/a24b33cd15f6fa19ff002b7c.html
- elasticsearch的安装2:https://www.cnblogs.com/ginb/p/elasticsearch.html
- 双击 E:Elasticsearch5.4.2inelasticsearch.bat启动Es服务
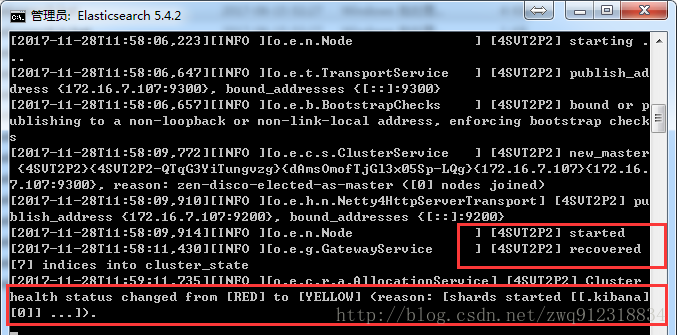
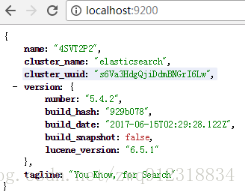
- 通过浏览器地址:localhost:9200 查看确保启动成功。
5. 同步代码
-
首先安装好python相关库
- pip install pymongo
- pip install elasticsearch
-
批量模式:快
将mongodb中的数据同步到Es中
from pymongo import MongoClient
from elasticsearch import Elasticsearch, helpers
import datetime一次同步的数据量,批量同步
syncCountPer = 100000
Es 数据库地址
es_url = ‘http://172.16.7.107:9200/’
mongodb 数据库地址
mongo_url=‘172.16.1.99:27017’
mongod 需要同步的数据库名
DB = ‘beauty’
mongod 需要同步的表名
COLLECTION = ‘20171120’
count = 0
if name == ‘main’:
es = Elasticsearch(es_url)
client = MongoClient(mongo_url)
db_mongo = client[DB]
syncDataLst = []
mongoRecordRes = db_mongo.find()
for record in mongoRecordRes:
count += 1
# 因为mongodb和Es中,对于数据类型的支持是有些差异的,所以在数据同步时,需要对某些数据类型和数据做一些加工
# 删掉 url 这个字段
record.pop(‘url’, ‘’)
# Es中不支持 float(‘inf’) 这个数据, 也就是浮点数的最大值
if record[‘rank’] == float(‘inf’):
record[‘rank’] = 999999999999syncDataLst.append({ "_index": DB, # mongod数据库 == Es的index "_type": COLLECTION, # mongod表名 == Es的type "_id": record.pop('_id'), "_source": record, }) if len(syncDataLst) == syncCountPer: # 批量同步到Es中,就是发送http请求一样,数据量越大request_timeout越要拉长 helpers.bulk(es, syncDataLst, request_timeout = 180) # 清空数据列表 syncDataLst[:]=[] print(f"Had sync {count} records at {datetime.datetime.now()}") # 同步剩余部分 if syncDataLst: helpers.bulk(es, syncDataLst, request_timeout = 180) print(f"Had sync {count} records rest at {datetime.datetime.now()}") -
单个模式:慢
将mongodb中的数据同步到Es中 ———— 多线程单个模式(速度慢)
from pymongo import MongoClient
import requests
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor示例
删除:requests.delete(f’{es_url}{db}')
插入:requests.put(f’{es_url}{db}')
插入:requests.post(f’{es_url}{db}/{table}')
es_url = ‘http://192.168.0.101:9200/’
mongo_url = ‘192.168.0.100:27017’
DB = ‘beauty’
COLLECTION = ‘20171120’def insert(data):
_id = data.pop(‘_id’)
data.pop(‘url’, ‘’)
if data[‘rank’] == float(‘inf’):
data[‘rank’] = 999999999999
return requests.put(url = f’{es_url}{DB}/{COLLECTION}/{_id}',
json = data,)if name == ‘main’:
client = MongoClient(mongo_url)
db_mongo = client[DB]
mongoRecordRes = db_mongo[COLLECTION].find()# 起30个线程同时进行数据同步 with ThreadPoolExecutor(30) as executor: # 返回一个迭代器:Returns an iterator equivalent to map(fn, iter). for result in executor.map(insert, mongoRecordRes): print(result.status_code, result.text) -
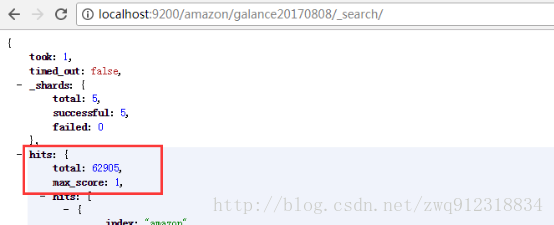
可以通过在浏览器地址 localhost:9200/database/table/_search/ 查看数据的同步情况:
6. 拓展:如何从Es中删除数据
前提:Es在2.0 以上版本就不支持批量删除数据(无法直接删除一张表,也就是type)了,但是可以直接删除整个数据库和一条记录。如果想要删除一张表,必须要安装插件才能高效的批量删除。这个插件就是 delete-by-query,安装方法就是cmd到Es的bin目录下运行这个代码: plugin install delete-by-query。
详情可以参考文章:http://blog.csdn.net/Merlyj/article/details/60764275
还可以参考文章:http://blog.csdn.net/Leafage_M/article/details/74011357
-
从Es中删除整个数据库
从Es中删除整个数据库
import requests
es_url = ‘http://192.168.0.100:9200/’
DB = ‘beauty’if name == ‘main’:
# Es已经不支持单独删除一个type, 也就是表 # Es支持删除一个index, 也就是数据库 # Es支持删除一个record res = requests.delete(url = f'{es_url}{DB}') print(res) -
从Es中删除一条记录
从Es中删除一条记录
from pymongo import MongoClient
import requests
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutores_url = ‘http://192.168.0.101:9200/’
mongo_url = ‘192.168.0.100:27017’
DB = ‘beauty’从原来Mongodb中拿到要从Es中删除数据的_id
COLLECTIONS = [
‘20171120’,
‘20171121’,
]def delete(data, collection):
_id = data.pop(‘_id’)
return requests.delete(url = f’{es_url}{DB}/{collection}/{_id}')if name == ‘main’:
client = MongoClient(mongo_url)
db_mongo = client[DB]
for collection in COLLECTIONS:
# 起30个线程
with ThreadPoolExecutor(30) as executor:
with ThreadPoolExecutor(30) as executor:
mongoRecordRes = db_mongo[collection].find()
for result in executor.map(delete, mongoRecordRes, [collection] * 200000):
print(result.status_code, result.text)


















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









