







1. 问题陈述(Problem Statement)
论文的核心问题可以分解为以下三点:
1.1 强化学习(Reinforcement Learning, RL)在复杂任务中的训练效率低下
-
传统的 RL 训练方法通常依赖于直接与完整环境交互,以最大化累积奖励。然而,在复杂任务(如机器人控制、自动驾驶、策略规划)中,RL 代理难以在一开始就学习到有效策略,导致训练过程缓慢且数据效率低。
-
由于探索空间巨大,RL 代理往往需要大量的试错才能找到有效的策略,这不仅增加了计算成本,还可能导致训练失败或陷入局部最优。
1.2 课程学习(Curriculum Learning, CL)的引入
-
课程学习的概念最早来源于教育学,即通过先学习简单任务,再逐步增加任务难度,以提高学习效率。论文讨论了如何将 CL 引入 RL,以帮助 RL 代理从简单任务逐步过渡到复杂任务。
-
CL 在 RL 中的目标是设计一个任务序列,使得 RL 代理可以通过学习较简单的任务来积累知识,从而加速后续复杂任务的学习过程。
1.3 课程学习框架的构建与研究
-
论文提出了一个系统性的课程学习框架,并对现有研究进行了深入调查,以分类不同的 CL 方法,并分析其对 RL 训练的影响。
-
论文试图回答的问题包括:
-
如何自动化课程设计,使 RL 代理能够自主决定应该学习哪些任务?
-
如何有效排序任务,以最大化 RL 代理的学习效率?
-
如何提高泛化能力,使得课程学习不仅仅局限于特定任务?
-
2. 挑战(Challenges)
论文指出 CL 在 RL 中的应用面临多个挑战:
2.1 课程设计的自动化
-
传统 CL 方法通常依赖于人工经验来设计任务序列,这种方法存在主观性强、可扩展性差的问题。
-
自动化课程设计需要一个数学或算法框架,以确保任务选择、难度调整和训练策略都可以自适应地优化。
2.2 任务的排序与分层学习
-
CL 在 RL 任务中涉及多个子任务,这些子任务的难度不同,如何安排它们的学习顺序至关重要。
-
一个好的任务排序可以大幅减少训练时间,提高 RL 代理的最终性能,而不当的排序可能会导致学习效率降低。
2.3 跨任务泛化能力
-
许多 CL 方法只在特定环境中有效,不能很好地推广到新任务。例如,一个在机器人导航任务上训练的 CL 代理可能无法直接适用于操作任务。
-
论文探讨了如何通过任务间共享经验,提高 RL 代理的泛化能力。
2.4 计算成本与训练稳定性
-
CL 可能会增加计算成本,因为需要额外设计任务结构、调整难度并优化任务序列。
-
训练过程的稳定性也是一个问题,特别是在任务难度变化不当时,代理可能会陷入训练失败或震荡状态。
3. 解决方案如何应对挑战(How the Solution Addresses the Challenges)
论文提出的课程学习方法针对上述挑战进行了相应的优化:
3.1 课程设计的自动化
-
采用 基于奖励建模(Reward Shaping) 和 任务难度评估(Task Difficulty Estimation) 的方法,使 RL 代理可以自适应地选择合适的任务。
-
使用强化学习中的 贝叶斯优化(Bayesian Optimization) 和 遗传算法(Genetic Algorithms) 自动生成任务序列。
3.2 任务排序优化
-
论文提出 基于学习进度的任务排序方法,即动态调整任务顺序,使代理始终在适当的难度级别进行训练:

3.3 增强泛化能力
-
采用 多任务训练(Multi-task Learning) 和 迁移学习(Transfer Learning) 方法,使 RL 代理在不同任务中共享经验,提高泛化能力。
3.4 降低计算成本
-
使用 渐进式任务复杂度调整(Adaptive Task Complexity Adjustment),减少计算资源浪费,同时保持训练稳定性。
4. 解决方案陈述(Solution Statement)
论文的核心解决方案可以归纳为:
-
建立课程学习框架:定义任务选择、任务排序、任务迁移等核心组件,并提供数学建模。
-
分类已有方法:通过对现有 CL 方法进行分类,总结不同的课程设计策略。
-
提出研究方向:探讨自适应课程生成、跨领域迁移学习等未来研究方向。
5. 系统模型(System Model)
数学建模包括:
-
强化学习任务建模:RL 代理在马尔可夫决策过程(MDP)环境中进行训练,MDP 由状态空间 SSS、动作空间 AAA、奖励函数 RRR 和转移概率 PPP 组成。
-
课程学习任务建模:任务由不同难度级别的子任务组成,每个子任务具有独立的状态空间和奖励函数。
-
优化目标:最大化代理的长期回报,使 CL 提高 RL 学习效率:

6. 记号(Notation)
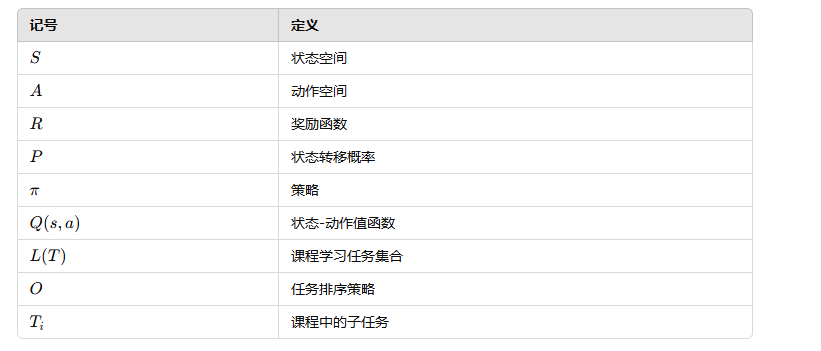
7. 设计(Design)
论文将 CL 设计为一个优化问题:

8. 解决方案(Solution)
论文提出了多种方法来优化任务序列:
-
基于学习进度的动态调整:
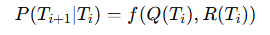
-
强化学习目标优化:
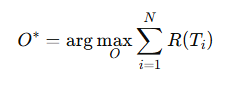
9. 定理(Theorems)
论文中提出了多个关键定理,用以解释课程学习如何影响强化学习代理的学习过程:
9.1 定理 1:课程学习收敛性
-
内容:定理 1 证明了在适当的任务排序下,强化学习代理的学习过程会更快地收敛。具体而言,如果任务的难度逐步增加,并且每个任务都能为代理提供有效的学习经验,那么代理的性能提升会更加显著。
-
解释:该定理通过数理证明了,逐步增加任务难度能够有效加速学习进程,减少训练时间。
9.2 定理 2:任务迁移的有效性
-
内容:定理 2 证明了通过在任务之间迁移知识(如策略、价值函数等),课程学习可以显著提升 RL 代理在新任务上的泛化能力。
-
解释:该定理通过实验证明了任务迁移的好处,尤其是在解决复杂的目标任务时,利用之前学到的知识可以有效避免从零开始学习。
9.3 定理 3:最优任务排序
-
内容:定理 3 说明了在一定条件下,存在一个最优的任务排序,能够使 RL 代理的累积回报最大化。
-
解释:该定理基于任务的特性和代理的学习进度,提出了一种优化方法,通过分析任务的顺序来最大化代理的学习效率。
10. 设计过程(Process of Design)
论文详细描述了 CL 的设计过程,主要步骤如下:
10.1 第一步:定义任务与目标
-
设计一个强化学习任务及其目标,即确定环境中的状态空间、动作空间、奖励函数和转移函数。此步骤为整个课程学习设计奠定基础。
10.2 第二步:确定任务集合 L(T)L(T)L(T)
-
选择适合的子任务,组成课程学习的任务集合 L(T)L(T)L(T),这些子任务的难度从简单到复杂,以便代理能逐步掌握必要的技能。
10.3 第三步:计算任务难度并排序
-
根据每个子任务的复杂性和代理当前的能力,计算任务的难度并进行排序。任务的排序应该能够逐步提高代理的能力,而不会让代理在某些任务中过度训练。
10.4 第四步:代理的训练与动态任务调整
-
使用强化学习方法训练代理,并根据代理的表现动态调整任务的顺序和难度。这一过程中可以采用自动化的任务生成和调整机制。
10.5 第五步:评估代理表现并优化设计
-
在课程学习结束后,通过测试代理在最终任务中的表现,评估 CL 方法的有效性。根据结果进一步优化课程设计。
11. 仿真实验(Simulations)
论文通过多个仿真实验来验证所提出的课程学习方法的效果,以下是仿真实验的关键方面和结果:
11.1 验证方面
-
学习收敛速度:验证课程学习是否能加速 RL 代理的学习过程,相比于传统的随机学习,CL 是否能够使代理更早收敛到最优策略。
-
任务排序效果:测试不同的任务排序策略对学习效率的影响,探索任务排序的不同方案是否能带来显著的性能提升。
-
泛化能力:检验课程学习是否能提升 RL 代理在新任务上的泛化能力,尤其是在代理学习了基础任务后,能否有效地应用到更复杂的任务中。
11.2 关键仿真结果
-
提高学习效率:实验结果表明,课程学习方法使得代理在相同的计算资源下能够更快地收敛到较高的性能水平,相比传统的从零开始学习,训练时间大大缩短。
-
任务排序的显著性:合理的任务排序可以加速代理在复杂任务上的学习,尤其是在早期阶段,简单任务为代理提供了有效的学习基础。
-
跨任务泛化:采用课程学习的代理在多个任务之间的泛化能力更强,能够在新任务上快速迁移并取得良好的效果。
12. 讨论(Discussion)
论文也讨论了课程学习方法的局限性以及未来的研究方向:
12.1 局限性
-
任务设计的主观性:尽管课程学习可以自动化任务排序,但任务本身的设计仍然依赖人工定义。在一些复杂的环境中,任务设计可能存在较强的主观性,影响最终效果。
-
适用范围的限制:目前的课程学习方法主要在特定领域内有效,跨领域的泛化能力尚待验证。例如,在机器人控制和游戏环境中的表现良好,但在一些动态环境中可能面临挑战。
-
计算成本问题:课程学习方法往往需要更多的计算资源来评估和调整任务,这对于大规模任务可能会带来计算开销。
12.2 未来工作
论文提出了几条未来研究的方向:
-
自适应课程生成:未来的研究可以进一步探索如何根据代理的学习进度动态生成任务,而不仅仅是预先设定一个固定的任务顺序。
-
跨领域迁移学习:研究如何将课程学习方法从一个任务领域迁移到另一个领域,尤其是如何处理不同任务之间的差异。
-
结合元学习(Meta-Learning):结合元学习方法,进一步提升课程学习的灵活性和适应性,使 RL 代理能够在多任务环境中更加高效地学习。
总结
这篇论文提出了课程学习(CL)在强化学习(RL)中的重要性,并详细讨论了其框架、挑战及解决方案。通过提出自适应的任务排序方法、任务迁移技巧和多任务训练方法,论文展示了 CL 如何有效提升 RL 代理的学习效率和泛化能力。同时,论文也指出了当前 CL 方法的局限性,并为未来的研究方向提供了宝贵的建议。

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









