






前几天阅读了一篇论文,于是忍不住写下本次的记录,个人见解哦!
题目:
Deep Digging into the Generalization of Self-Supervised Monocular Depth
Estimation(深入研究自监督单目深度估计的泛化)
研究目标:
使用CNN-Transformer混合模型,实现单目深度估计的泛化能力提升
贡献总结:
- CNN主要学习基于纹理的表示,而Transformers几乎学习基于形状的表示
- 提出了一种具有多级特征聚合的CNN-Transformer混合网络,补充了形状偏差和空间局部偏差,以实现单目深度估计的泛化
- 大量的实验证明了所提方法的有效性,我们的方法在KITTI数据集、各种分布外数据集和纹理偏移数据集上取得了最先进的性能
方法学习:
1)基于CNN的模型严重依赖纹理,而基于Transformer的模型依赖于形状进行单目深度估计任务。
2)基于纹理的表示会导致场景变化、照明变化和风格变化等纹理偏移的泛化性能较差。
3)基于形状的表示比基于纹理的表示更有助于广义单目深度模型。
模型结构:
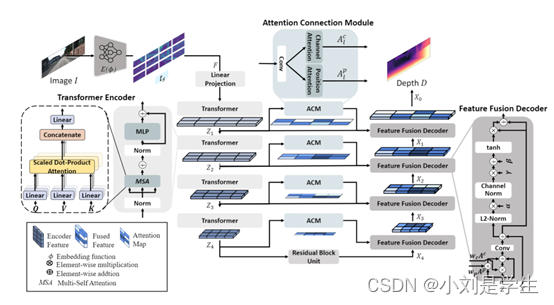
1.CNN-Transformer 编码器:由多头自注意力 (MSA) 层、多层感知器 (MLP) 层和层范数 (LN) 层组成
2. 注意连接模块(ACM):它从空间域和通道域产生注意力权重(Fu 等人,2019 年)。它由位置注意力、通道注意力模块和从两个注意力收集重要信息的融合块组成。
3. 特征融合解码器(FFD):FFD 获取编码器特征 Z、注意力映射 A、A 和通过残差卷积层的最后一个 Transformer 层的输出特征 X。解码器通过单个卷积层 (Conv) 和通道归一化 (CN) 将特征 X。
---------------------------------------------------------------------------------------------------------------------------------个人总结:本篇论文的出发点是由于大多数的研究模型泛化能力比较差,通过作者的观察和探索,结合了cnn和transformer的特点,能够应用于多种数据集。其中比较值得注意的是编码器中使用了多头注意力层,它从空间域和通道域产生注意力权重(Fu 等人,2019 年)。它由位置注意力、通道注意力模块和从两个注意力收集重要信息的融合块组成,这样可以大大提高图像的特征提取性能。















 4252
4252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









