






SFM(Structure From Motion)的思想被越来越多的借鉴,用于无监督(自监督)的深度估计、姿态估计中。自SFM的开篇之作之后,各种motion相关的改进和新作不断出现。这篇文章,就是在motion框架的基础上,对各种结构模块做了一些改进,结果取得了非常大的进步。
文章并没有做网络上或者方法上突破性的创新,甚至可以说都是沿用了一些现有的模块和思想,但是一样获得了不错的结果。本文的目标是单目照片的深度估计,其实有了深度,一些3D detection也会比较顺利。文章针对前作的一些共性的缺点,共提出了3条(如果算入loss,算是4条)优化策略,下面分别介绍一下:
1、Per-Pixel Minimum Reprojection Loss
字面上并不难理解,也就是对每一个像素,投影的时候每个像素位置取最小的灰度差计算loss。
在解释之前,先要说一下这个idea是从什么问题中产生的。在单目motion的方法中,常把一张t时刻的照片
I
t
I_{t}
It(称为源图 source image),投影到另一张t+1时刻照片
I
t
+
1
I_{t+1}
It+1(称为目标图 target image)中,生成一张合成的图片
I
t
+
1
′
{I_{t+1}}'
It+1′,来计算目标图
I
t
+
1
I_{t+1}
It+1和合成图
I
t
+
1
′
{I_{t+1}}'
It+1′之间的差异,这样每一个像素都会产生一个loss值。在训练过程中,常常把t时刻的源图,投影到多个不同的时刻中去(t+1,t-1,……),然后计算一个总的loss(多张照片投影到一个时刻也是一样的),在这个过程中,就会发生一个遮挡的问题,如下图所示。
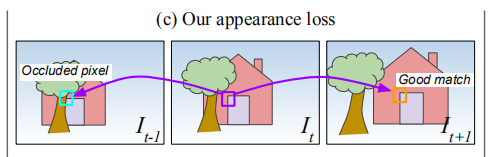
把中间的源图投影到相邻两个时刻的目标图中,假设紫色框框出来的位置像素值是100,投影到下一时刻,(橙色框)像素值还是100,loss是0,说明投影对了。但是投影到上一时刻的时候,(青色框)像素值是200(被树遮挡了,所以是树的像素值),这样计算出来loss是100,但是我们投影的位置可能是完全正确的,只不过发生了遮挡,我们无法获取目标图中被遮挡的像素值。之前的方法,在这一步都是使用的average loss,也就是当发生这种情况时,总的loss为50。文章察觉到了这个问题,明明很多时候投影没有问题,是遮挡使得loss变大,造成了系统的不稳定,所以提出了这个改进方法。
具体怎么做呢,很简单,取每个照片对,对应位置的最小loss值,对于上例,总的loss就是min(0,100)=0。用公式表示:
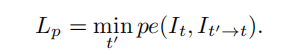

2、Auto-Masking Stationary Pixels
一般来说,self-supervised的SFM方法,都是假设场景是静态的,是相机在发生移动。但是在应用的时候,包括实际场景和数据集中的数据,都会存在不同的情况,比如场景中的物体在发生移动(公路上的汽车),或者相机本身是不移动的(道路监控),这些应用self-supervised方法,就会产生很大的问题(亲测的确如此)。如果道路中的物体在移动,那么除了预测相机的pose,还需要预测每一个移动的物体的3D 信息,才能完整准确的进行投影和照片合成;如果相机不移动,那么绝大多数像素是不会发生改变的,也就对loss的计算造成了一些影响。这些都会造成文章称为“holes”的问题,于是文章提出来了一种处理方法,叫做Auto-Masking Stationary Pixels,翻译过来是“自动掩模静止像素”,其实就是做了一个把静止的像素找出来的事情。一方面是找到两帧之间静止不动的像素(一般是静止的相机,大部分像素都是静止的),另一方面找出和相机移动速度相同的物体(以防被认为是背景,而变成无限远,也就是holes)。于是文章设置了一个mask,计算出变化比较明显的像素,忽略基本不变的像素(这样的像素有静止的背景,同速度的物体,以及纹理比较少的区域),通过公式
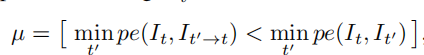
获得这个整张图片的mask,这个公式的意思就是,先计算一个目标图和源图对应位置的像素差
m
1
m_1
m1,然后再计算一个合成图和目标图的像素差
m
2
m_2
m2,只有当
m
2
<
m
1
m_2<m_1
m2<m1,才认为是一个有效像素,否则mask为0。这样做的以意就是,如果两帧之间像素出现了本文上述斜体字的情况,那么
m
1
m_1
m1无限接近于0,这样合成图片时做投影,要么是像素依然不变
m
2
=
m
1
m_2=m_1
m2=m1,要么是投影到了别的区域
m
2
>
m
1
m_2>m_1
m2>m1,两种情况都筛掉。(个人感觉这个公式也还是会筛掉一些有效的像素点,再加一个
m
1
m_1
m1小于一定阈值的约束会不会更好?)
下图是这个idea的应用效果,可以看出,除了本文(右下角),对于移动中的物体都会有holes的问题,即把物体预测为无限远处。

3、Multi-scale Estimation
文章使用了Unet的结构,是一个多尺度的方法,对上采样过程中的每一层特征图都计算一个loss。但是不同于其他文章和方法的直接计算,本文是先把每一层特征图先经过一个额外的上采样,恢复到原图大小,然后再用原图大小的特征图和原图直接计算loss。举个例子,Unet某一层的特征图如果是28×28×C的,传统的方法是直接用这个28×28×C的特征图计算loss,而本文的做法是先将28×28×C经过上采样到原图大小,比如是448×448,然后和原图做loss。
文章解释这样解决了原本小分辨率特征图对于大范围的无纹理区域,预测产生的holes现象,以及因为小特征图损失信息而造成的texture-copy artifacts现象(不知道该怎么翻译,纹理复制假象?)
*4、计算两个图相似性的loss
以上就是文章的三个创新点,另外文章在计算两个图相似性的时候,使用了SSIM的loss。这个loss早就已经提出来了,详细计算可以网上搜一下,很简单的一个公式,前作应该也已经使用过了。文章计算的公式如下:
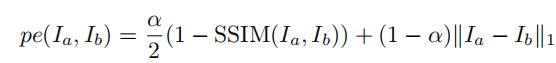
是一个SSIM与L1结合的loss。
这就是文章全部的创新点,其实并没有提出什么突破性的结构或发明,只是分析了一下现有的问题,把一些小的tips应用了一下,就获得了不错的结果。具体的实验、对比、结果等可以看论文的4章以后的内容,这里就不详细写了。
PS:
有小伙伴提问,在这里补充一下,我把源码完整读了一遍,发现深度都是用的归一化的值来表示的,并不存在绝对的深度值。毕竟论文是无监督的,在没有先验的情况下,是得不到一个准确的深度值的。可以人为给一个深度上限,比如100米,然后把归一化的值转换为真实深度。
















 2757
2757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









