







目录
前言
即使在大模型时代,核心还是Transformer,想要完全理解Transformer,总感觉还差点东西,当手撸了一遍实现代码后,再结合理论讲解豁然开朗,所以本问以代码实践为主,关于理论部分就尽量少赘述了。
最经典的图还得是论文中的原图:
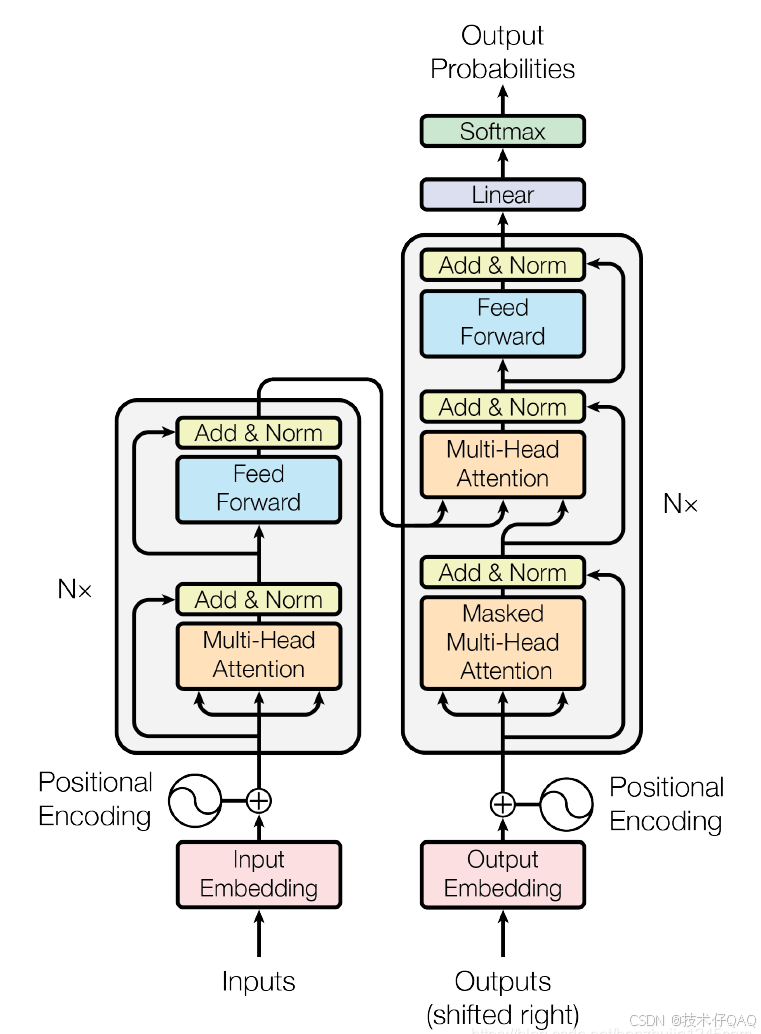
关于这张图的介绍有很多,简单总结下,左边是编码器(Encoder),右边是解码器(Decoder),N× 表示进行了 N 次堆叠。主要可分成以下几个模块(更容易代码实现为导向):
嵌入表示层(图中粉红Input Embedding和白色小圈Positional Encoding部分);
注意力层(图中淡黄Attention部分);
前馈层(图中淡蓝Feed Forward部分);
残差连接和层归一化(图中黄色Add&Norm部分)。
接下来分别对每个模块进行简述以及代码实现。
一、嵌入表示层
该部分主要由两部分组成,即 Embedding 层和位置编码层。
先看下 Embedding 层的实现,Embedding 层的主要作用就是将文本序列通过分词器(tokenizer)分出的token,转换为其相对应的向量表示。假设:"我喜欢",分为"我|喜欢",对应的 token 索引是[13,156] 然后通过 Embedding 层转换成对应的向量。
下面是Embedding层的代码实现(后续代码建议在jupyter上实践[2])::
# 后续代码所需的依赖
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
class TokenEmbedding(nn.Embedding):
"""
使用torch.nn的Embedding模块
"""
def __init__(self, vocab_size, d_model):
"""
TokenEmbedding类
:param vocab_size: 词汇表的大小
:param d_model: 模型的维度
:padding的索引为1,即token索引为1时,Embedding补0
"""
super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)看一下参数,假设词汇表大小为1000,模型维度是512,则Embedding层的参数如下:
tok_emb = TokenEmbedding(1000, 512)
num_params = sum(p.numel() for p in tok_emb.parameters())
print("模块中的参数数量为:", num_params)测试一下能否够正常使用:
# x是batch_size为2, seq_len为3,索引为1的会被padding为0
x = torch.LongTensor([[6, 5, 4], [3, 2, 1]])
res = tok_emb(x)
print("res:", res)
print("res.shape:", res.shape)接下来看位置编码层,如果只有Embedding层是不能让模型知道token之间的相对位置关系的,所以在进入编码器建模其上下文语义之前,编码其相对位置信息是一个很重要的操作,Transformer使用的是正余弦函数来编码其位置信息:

上图中 pos 表示单词所在的位置,2i 和 2i + 1 表示位置编码向量中的对应维度,d 则对应位置编码的总维度。这种位置编码有两个优点:1. 第 pos + n 个位置的编码是第 pos 个位置的编码的线性组合,包含了相对位置信息;2. 正余弦函数的范围是在 [-1,+1],相加后的总嵌入改变不会太大。下面是位置编码层代码实现:
class PositionalEncoding(nn.Module):
"""
计算正余弦位置编码。
"""
def __init__(self, d_model, max_len):
"""
正余弦位置编码类
:param d_model: 模型的维度
:param max_len: 最大序列长度
"""
super(PositionalEncoding, self).__init__()
# 初始化位置编码矩阵
self.encoding = torch.zeros(max_len, d_model)
self.encoding.requires_grad = False # 不需要计算梯度
pos = torch.arange(0, max_len)
pos = pos.float().unsqueeze(dim=1)
# 'i'表示d_model的索引(例如,嵌入大小=50,'i' = [0,50])
# “step=2”表示将'i'乘以二(与2 * i相同)
_2i = torch.arange(0, d_model, step=2).float()
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 8, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# 将与 tok_emb 相加:[8, 30, 512]看一下参数,假设最大序列长度为512,模型维度也是512,则位置编码层的参数如下:
pe = PositionalEncoding(512,512)
num_params = sum(p.numel() for p in pe.parameters())
print("模块中的参数数量为:", num_params)会发现结果结果打印出来是0,因为这个参数矩阵不需要训练,直接生成的,大小是max_len*d_model = 512*512的一个矩阵。看一下使用,如果对这个位置编码有疑惑可以将函数中每一步的中间结果打印出来更容易理解:
# x是batch_size为2, seq_len为3
x = torch.LongTensor([[6, 5, 4], [3, 2, 1]])
res = pe.forward(x)
print("res:", res)
# 返回的形状是[seq_len = 3, d_model = 512]
print("res.shape:", res.shape)把Embedding层和位置编码层集成在一起即嵌入表示层:
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding
"""
def __init__(self, vocab_size, d_model, max_len, drop_prob):
"""
包含Embedding和位置编码的类
:param vocab_size: 词汇表大小
:param d_model: 模型的维度
:param max_len: 最大序列长度
:param drop_prob: dropout 正则化概率,防止过拟合
"""
super(TransformerEmbedding, self).__init__()
self.tok_emb = TokenEmbedding(vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model, max_len)
self.drop_out = nn.Dropout(p=drop_prob)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(x)
return self.drop_out(tok_emb + pos_emb)这个类的参数量还是Embedding层的参数量,看一下使用:
te = TransformerEmbedding(1000,512,512,0.1)
# x是batch_size为2, seq_len为3
x = torch.LongTensor([[6, 5, 4], [3, 2, 1]])
res = te.forward(x)
print("res:", res)
# 返回的形状是[batch_size = 2, seq_len = 3, d_model = 512]
print("res.shape:", res.shape)二、注意力层
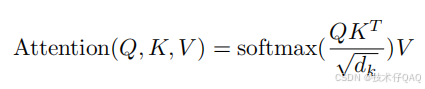
关于Transformer的多头自注意力机制最重要就是要理解 Q,K,V 这三个向量的含义,这里就从代码的角度来简述一下,假设文本:"我喜欢",分为"我|喜欢",经过Embedding层和位置编码后变成嵌入向量形状是:[batch_size = 1, seq_len = 2, d_model = 512],这时候 Q 矩阵就是这个嵌入向量 * W_q 参数矩阵,同理 K 矩阵是嵌入向量 * W_k 参数矩阵,V矩阵是嵌入向量 * W_v 参数矩阵。
这三个参数矩阵 W_q、W_k、W_v 都是可以训练的,经过计算后 Q,K,V 的形状还是[batch_size = 1, seq_len = 2, d_model = 512],然后带入到下面的公式中进行计算。这个注意力公式我觉得核心的理解就是“一个矩阵乘以它自己的转置再乘以它自身”,这样一通算下来还不够关注自己吗哈哈,我觉得这就是注意力机制的精髓。
但注意上面是单头的情况,那什么是多头(Multi-Head)呢,就是把模型的维度 d_model=512 进行拆分成多分,假设头数为 2,那么会把原来的 Q,K,V 都会拆成两份,但是只拆维度,两个 Q的形状都是[batch_size = 1, seq_len = 2, d_model = 256],但第一个 Q 取模型维度的前256的值,K和V同理。然后分别带入下面公式计算注意力。为什么使用多头呢?一个简单解释:在不同的子空间中分别计算并得到不同的上下文相关的表示,通俗来讲在多个角度来关注自己。
class ScaleDotProductAttention(nn.Module):
"""
计算单个点积注意力
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e-12):
# 输入是一个4维的张量
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1.用Key的转置与Query计算点积
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2.进行掩码,encoder不需要进行掩码,decoder需要进行掩码
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
# 3.通过softmax使分数范围在[0, 1]之间
score = self.softmax(score)
# 4.再与Value相乘
v = score @ v
return v, score上面是单独实现论文中计算注意力机制的代码,下面是整个多头注意力实现的代码:

class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1.点积相应的矩阵
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2.根据头数进行维度拆分
q, k, v = self.split(q), self.split(k), self.split(v)
# 3.进行计算
out, attention = self.attention(q, k, v, mask=mask)
# 4.把拆分的多头再拼起来
out = self.concat(out)
out = self.w_concat(out)
return out
def split(self, tensor):
"""
根据头数进行维度拆分
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
return tensor
def concat(self, tensor):
"""
把拆分的多头再拼起来
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor三、前馈层
![]()
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x四、残差连接和层归一化
残差连接就是把未经过某层的原矩阵加上经过该层的矩阵,等于最终矩阵,最早是在ResNet论文中提出的,简单公式描述就是:x_i+1 = F(x_i) + x_i,x_i为原矩阵,x_i+1为最终所需矩阵。
层归一化简单来说就是计算数据的均值和方差,然后使其平移缩放到标准分布中,主要的效果是避免训练时数值不稳定,收敛速度慢。实现的代码也比较简单:
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.alpha = nn.Parameter(torch.ones(d_model))
self.bias = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.alpha * out + self.bias
return out五、Encoder
上面是各个模块实现的代码,接下来把各个模块拼起来,先拼单独的Encoder层,就是架构图左侧的部分,建议翻到前面对着图看会更清晰:
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, src_mask):
# 1.计算注意力
_x = x
x = self.attention(q=x, k=x, v=x, mask=src_mask)
# 2.残差连接和层归一化
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3.前馈层
_x = x
x = self.ffn(x)
# 4.最后一次残差连接和层归一化
x = self.dropout2(x)
x = self.norm2(x + _x)
return x接下来是整个Encoder部分:
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, src_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, src_mask)
return x六、Decoder
以上就是Encoder部分,现在开始拼Decoder层,看架构图右侧的部分,这里需要注意几点,
第一点是:Decoder部分是两个注意力块,而且这两个还不一样,第一个注意力块是需要mask进行掩码的,而上面Encoder是不需要的,简单的解释就是:Transformer最初设计适用于机器翻译的,Encoder主要用于编码源语言序列的信息,而这个序列是属于已知的,只需要考虑如何融合上下文语义信息;而Decoder是负责生成目标语言序列的,这一生成过程是自回归的,即对于每一个token的生成过程,仅有当前token之前的目标语言序列是可以被看到的, 因此这一额外增加的掩码是用来掩盖后续的文本信息,以防模型在训练阶段直接看到后续的文本序列进而无法得到有效地训练[3]。GPT系列主要用的这个思想,所以才有了现在的大模型时代。
第二点是:Decoder部分的第二个注意力块,输入的Q是上一步的输出,K和V是Encoder部分的输出,也就是这里把Encoder和Decoder连接了起来也可以叫做交叉注意力,看代码会更清晰明了。
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, trg_mask, src_mask):
# 1.对应上面说的第一点
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=trg_mask)
# 2.残差连接和层归一化
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3.对应上面说的第二点
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=src_mask)
# 4.残差连接和层归一化
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5.前馈层
_x = x
x = self.ffn(x)
# 6.残差连接和层归一化
x = self.dropout3(x)
x = self.norm3(x + _x)
return x接下来是整个Decoder部分:
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# 最后经过一个全连接层
output = self.linear(trg)
return output七、Transformer
接下来构建整个Transformer的结构,对着结构图实现起来就比较简单了:
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size, d_model, n_head, max_len,
ffn_hidden, n_layers, drop_prob):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.encoder = Encoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
enc_voc_size=enc_voc_size,
drop_prob=drop_prob,
n_layers=n_layers)
self.decoder = Decoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
dec_voc_size=dec_voc_size,
drop_prob=drop_prob,
n_layers=n_layers)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
output = self.decoder(trg, enc_src, trg_mask, src_mask)
return output
def make_src_mask(self, src):
"""
创建源序列(src)的掩码, 将pad补零的位置设为False
"""
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask
def make_trg_mask(self, trg):
"""
创建目标序列(trg)的掩码, 1.pad补零的位置设为False;
2.创建一个下三角矩阵,这个矩阵的对角线及以下的为为True,其余位置为False
表示在训练时模型只能依赖于当前和过去的信息,不能依赖未来的信息
"""
trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(3)
trg_len = trg.shape[1]
trg_sub_mask = torch.tril(torch.ones(trg_len, trg_len)).type(torch.ByteTensor).to(self.device)
trg_mask = trg_pad_mask & trg_sub_mask
return trg_mask以上就是整个Transformer的结构,初始化一下看看模型的结构和参数,模型参数就参照原文了:
# 原文base模型参数
max_len = 256
d_model = 512
n_layers = 6
n_heads = 8
ffn_hidden = 2048
drop_prob = 0.1
# 分词,词表的一些参数,和通过数据集训练的tokenizer是相关的,这里就简单给一下
# 原文使用的数据集是WMT14 EN-DE,enc_voc_size为32000,dec_voc_size为25000,
# 这个训练出的词表数值不一样,最终模型的参数也不一样,因为这两个参数会影响Embedding层的参数
src_pad_idx = 1
trg_pad_idx = 1
trg_sos_idx = 2
enc_voc_size = 32000
dec_voc_size = 25000
model = Transformer(src_pad_idx=src_pad_idx,
trg_pad_idx=trg_pad_idx,
trg_sos_idx=trg_sos_idx,
d_model=d_model,
enc_voc_size=enc_voc_size,
dec_voc_size=dec_voc_size,
max_len=max_len,
ffn_hidden=ffn_hidden,
n_head=n_heads,
n_layers=n_layers,
drop_prob=drop_prob)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# 模型的参数
print(f'The model has {count_parameters(model):,} trainable parameters')
# 模型的结构
print(model)
# 结果如下
The model has 86,147,496 trainable parameters
Transformer(
(encoder): Encoder(
(emb): TransformerEmbedding(
(tok_emb): TokenEmbedding(32000, 512, padding_idx=1)
(pos_emb): PositionalEncoding()
(drop_out): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-5): 6 x EncoderLayer(
(attention): MultiHeadAttention(
(attention): ScaleDotProductAttention(
(softmax): Softmax(dim=-1)
)
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(w_concat): Linear(in_features=512, out_features=512, bias=True)
)
(norm1): LayerNorm()
(dropout1): Dropout(p=0.1, inplace=False)
(ffn): PositionwiseFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(relu): ReLU()
(dropout): Dropout(p=0.1, inplace=False)
)
(norm2): LayerNorm()
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(decoder): Decoder(
(emb): TransformerEmbedding(
(tok_emb): TokenEmbedding(25000, 512, padding_idx=1)
(pos_emb): PositionalEncoding()
(drop_out): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-5): 6 x DecoderLayer(
(self_attention): MultiHeadAttention(
(attention): ScaleDotProductAttention(
(softmax): Softmax(dim=-1)
)
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(w_concat): Linear(in_features=512, out_features=512, bias=True)
)
(norm1): LayerNorm()
(dropout1): Dropout(p=0.1, inplace=False)
(enc_dec_attention): MultiHeadAttention(
(attention): ScaleDotProductAttention(
(softmax): Softmax(dim=-1)
)
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(w_concat): Linear(in_features=512, out_features=512, bias=True)
)
(norm2): LayerNorm()
(dropout2): Dropout(p=0.1, inplace=False)
(ffn): PositionwiseFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(relu): ReLU()
(dropout): Dropout(p=0.1, inplace=False)
)
(norm3): LayerNorm()
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(linear): Linear(in_features=512, out_features=25000, bias=True)
)
)上面就是整个Transformer的实践,想要开始训练还缺一个数据集去训练tokenizer和词表,原文是使用BPE分词算法训练的。

















 2874
2874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









