







1.pandas概述
Pandas是进行科学数据分析中另一个比较常用的数据库,基于NumPy,但加入了更多的高级数据结构以及操作工具,进一步简化了NumPy等运算与应用。
1.1安装
pip install pandas
可以通过import库检查Pandas是否安装成功
from pandas import Seeries,DataFrame
import pandas as pd
1.2Series数据结构
与一维数组相似,由一组数据以及对应的数据标签组成,索引在左边,值在右边。
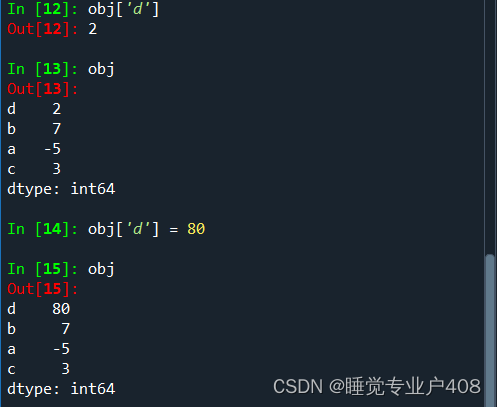
如果没有为数据规定对应的索引,则会自动创建一个范围为0到n-1的整数索引;通过values和index属性获取数组表示形式和索引对象。

指定索引
obj = Series([2,7,-5,3],index = ['d','b','a','c'])
1.3DataFrame
是表格类型,它可以有很多有序的列,每一列都可以设置不同的内容与类型,包括字符串、数值、布尔等。
可以采用行或者列的形式进行索引,
data = {'name':['Tom','Marry','Herry'],'year':[1996,1997,1998],'grade':[86,79,93]}
frame = DataFrame(data)
frame
Out[20]:
name year grade
0 Tom 1996 86
1 Marry 1997 79
2 Herry 1998 93
#指定列顺序,则会按照指定顺序进行排列
DataFrame(data,columns = ['year','grade','name'])
Out[21]:
year grade name
0 1996 86 Tom
1 1997 79 Marry
2 1998 93 Herry
#可以获取DataFrame的某一列作为一个Series,返回的Series拥有与原来相同的索引
frame['name']
Out[22]:
0 Tom
1 Marry
2 Herry
Name: name, dtype: object
frame.year
Out[23]:
0 1996
1 1997
2 1998
Name: year, dtype: int64
1.4基本操作
1.4.1. 重新索引
可以创建与旧索引不同的索引,能够适应新索引对象。
reindex:根据新索引进行重排,同时如果某个索引值当前不存在,就引起缺失值。

1.4.2. 丢弃
drop:返回一个丢弃了指定行或列中的新对象。
(就是删除后的对象)
例一:
import numpy as np
obj=Series(np.arange(5.),index=['a','b','c','d','e'])
obj
Out[34]:
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: float64
new_obj = obj.drop('c')
new_obj
Out[36]:
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
例二:
import numpy as np
from pandas import DataFrame
data = DataFrame(np.arange(16).reshape((4,4)),index=['math','English','Chinese','Sports'],columns = ['one','two','three','four'])
data
Out[16]:
one two three four
math 0 1 2 3
English 4 5 6 7
Chinese 8 9 10 11
Sports 12 13 14 15
data.drop('Chinese')
Out[17]:
one two three four
math 0 1 2 3
English 4 5 6 7
Sports 12 13 14 15
data.drop('two',axis = 1)
Out[18]:
one three four
math 0 2 3
English 4 6 7
Chinese 8 10 11
Sports 12 14 15
1.4.3. 索引
Series索引的方式类似与NumPy数组的索引,但它的索引和切片不仅可以用整数,还可以用对应的标记。
import numpy as np
from pandas import Series,DataFrame
obj = Series(np.arange(4.),index = ['a','b','c','d'])
obj
Out[20]:
a 0.0
b 1.0
c 2.0
d 3.0
dtype: float64
obj['b']
Out[21]: 1.0
obj[1]
Out[22]: 1.0
obj[['b','c']]
Out[23]:
b 1.0
c 2.0
dtype: float64
obj[1:3]
Out[24]:
b 1.0
c 2.0
dtype: float64
切片运算与普通的python切片运算是不同的,你会发现其末端是包含在内的。
1.4.4. 算术运算
最常用的功能之一,它是首先保证索引对应相同,再对相应的内容进行加减等操作。如果存在不相同的索引对,则结果是该索引对的并集
import numpy as np
from pandas import Series,DataFrame
df1 = DataFrame(np.arange(9.).reshape((3,3)),columns=list('bcd'),index=['Tom','Mary','Alice'])
df2 = DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['Mary','Alice','Mike','Tom'])
df1
Out[32]:
b c d
Tom 0.0 1.0 2.0
Mary 3.0 4.0 5.0
Alice 6.0 7.0 8.0
df2
Out[33]:
b d e
Mary 0.0 1.0 2.0
Alice 3.0 4.0 5.0
Mike 6.0 7.0 8.0
Tom 9.0 10.0 11.0
df1+df2
Out[34]:
b c d e
Alice 9.0 NaN 12.0 NaN
Mary 3.0 NaN 6.0 NaN
Mike NaN NaN NaN NaN
Tom 9.0 NaN 12.0 NaN
2.数据清洗
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理
2.1清洗数据
- 使用 dropna() 方法,要删除包含空字段的行;
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- 如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数;
- 通过 isnull() 判断各个单元格是否为空;
- Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数);
- 使用 mode() 方法计算列的众数并替换空单元格
2.2清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
3.一点小技巧
- shift+enter:将关闭多行编辑并执行任何输入的代码;
- ctrl+enter:将开启多行编辑;
- 使用索引字段ix,可以从DataFrame中选取行和列的子集;
| obj.ix[val] | 选取DataFrame的单个行或一组行 |
|---|---|
| obj.ix[:,val] | 选取单个列或列子集 |
| obj.ix[val1,val2 | 同时选取行和列 |
- 可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件;
- to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替;
- head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行;
- tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。;
- info() 方法返回表格的一些基本信息
最后,看到这里的朋友们也可以看看菜鸟教程,适合像我一样的新手!
















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











