






实验目的
- 掌握逻辑回归的数学原理及推导过程;
- 编程实现逻辑回归函数,并应用与给定手写字体数据集data_digits;
- 调用sklearn中逻辑回归函数,对给定手写字体数据集data_digits分类;
实验内容
1.
- 使用sklearn中逻辑回归函数,对给定手写字体数据集data_digits进行多分类,data_digits中数据格式为5000 x 400矩阵,其中每一行为一幅20x20手写字体图片。
求解:使用sklearn中逻辑回归函数对这5000样本分类,预测其分类准确率?给出代码与运行结果图。
自己动手编写逻辑回归函数对手写字体数据集data_digits进行多分类。
交叉熵损失函数公式如下:
其对应梯度公式如下:
求解:使用自编逻辑回归函数对这5000样本分类,预测其分类准确率?给出代码与运行结果图。
实验步骤及实验结果
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化逻辑回归模型
logreg = LogisticRegression(max_iter=1000)
# 训练逻辑回归模型
logreg.fit(X_train, y_train)
# 对测试集进行预测
y_pred = logreg.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率(sklearn逻辑回归模型):{accuracy * 100:.2f}%")
# 绘制一些数字及其预测标签
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for ax, image, prediction in zip(axes.flat, X_test[:10], y_pred[:10]):
ax.imshow(image.reshape(8, 8), cmap='gray')
ax.set_title(f'预测值: {prediction}')
ax.axis('off')
plt.show()
![]()
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 添加偏置项到特征中
X = np.hstack((np.ones((X.shape[0], 1)), X))
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义softmax函数
def softmax(z):
exp_z = np.exp(z)
return exp_z / np.sum(exp_z, axis=1, keepdims=True)
# 定义交叉熵损失函数
def loss_function(theta, X, y):
m = len(y)
h = softmax(X @ theta)
loss = -np.mean(np.log(h[np.arange(m), y]))
return loss
# 定义损失函数的梯度
def gradient(theta, X, y):
m = len(y)
h = softmax(X @ theta)
grad = X.T @ (h - np.eye(10)[y]) / m
return grad
# 使用梯度下降法训练逻辑回归模型
def logistic_regression(X, y, num_iters, learning_rate):
theta = np.zeros((X.shape[1], 10))
for _ in range(num_iters):
grad = gradient(theta, X, y)
theta -= learning_rate * grad
return theta
# 训练逻辑回归模型
num_iters = 1000
learning_rate = 0.1
theta = logistic_regression(X_train, y_train, num_iters, learning_rate)
# 对测试集进行预测
y_pred = np.argmax(softmax(X_test @ theta), axis=1)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率(自己编写的逻辑回归模型):{accuracy * 100:.2f}%")
# 绘制一些数字及其预测标签
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for ax, image, prediction in zip(axes.flat, X_test[:10, 1:], y_pred[:10]):
ax.imshow(image.reshape(8, 8), cmap='gray')
ax.set_title(f'预测值: {prediction}')
ax.axis('off')
plt.show()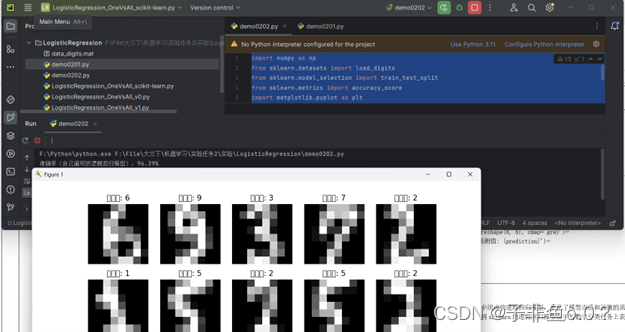

















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









