






本学期在学习人工智能与机器学习,恰逢学到逻辑回归并演示书中的示例代码并独立解决一些入门级基础知识 。以下为本文的叙述逻辑关系。
(1)对相关问题背景、数据集等进行描述。
(2)简要介绍逻辑回归算法的基本原理。
(3)采用Python进行编程,对数据集完成数据分割,根据训练数据进行机器学习(对主要编程语句需进行注释)。
(4)根据测试样本数据集,进行模型评价;对相关数据进行图、表可视化。
一。数据集的来源与描述
- 数据集来源。
泰坦尼克号乘客的生还预测的训练数据集又Kaggle竞赛的网站获得(http://www.kaggle.com/c/titanic/data)以下,我将使用Panda库输入工具read_csv来引用。
- 问题背景。
泰坦尼克号乘客的生还预测问题是Kaggle数据科学竞赛入门级竞赛之一。通过运用逻辑回归算法,根据乘客的相关特定信息,如:年龄,性别,船舱等级等等预测其是否会生还。
通过建立特定数学模型,检验并预测乘客的生还问题。
二、机器学习算法及原理
本文选择逻辑回归算法。通过逻辑回归算法我们可以特定的解决分类问题,但其中回归与分类又是有所区别的。回归预测的目标变量取值是连续的,可用一条直线拟合;而分类所预测的目标变量是类别型变量,其取值是离散的。
他本身是一个二分类器,其基本思想是“拆解法”,即将多分类任务拆分为若干个二分类任务求解。逻辑回归主要应用于解决分类问题,并特定要求为离散型且并不要求特征与目标变量呈线性关系。
三、机器学习的Python编程
(1)
| import pandas as pd # 从Panda库里面用read_csv读入数据库 data = pd.read_csv('E:/WQY Python/07LogisticRegression/train.csv') # 数据文件存在目录E:/WQY Python/07LogisticRegression/train.csv下 |
(2)
| data.info() #对训练集进行数据分析 |
(3)
| data.describe() #运用这条语句进行数据的描述统计分析 |
(4)
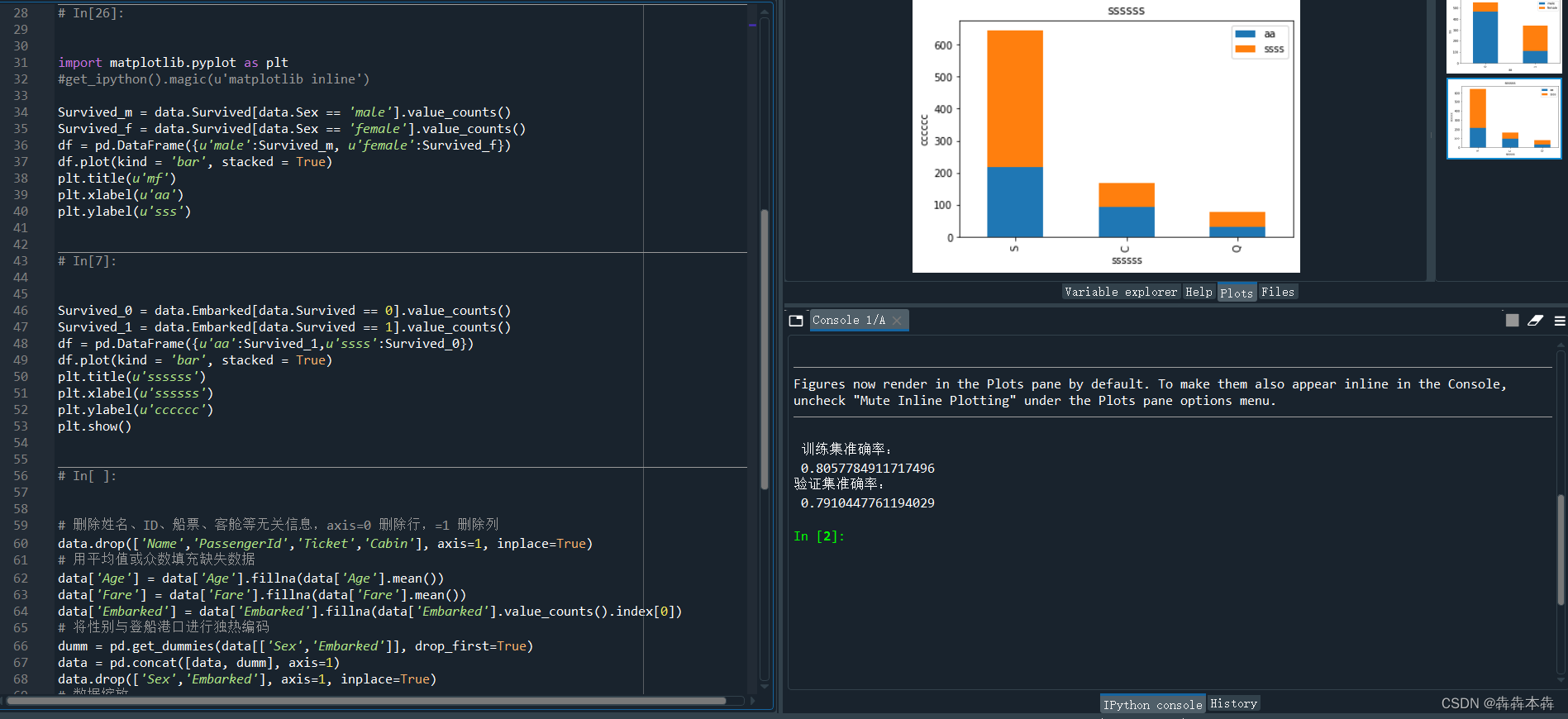
| import matplotlib.pyplot as plt #get_ipython().magic(u'matplotlib inline') #引用matplotlib.pyplot库模型来判断性别生还情况 Survived_m = data.Survived[data.Sex == 'male'].value_counts() #所有获救的人是男性(male)的人数 Survived_f = data.Survived[data.Sex == 'female'].value_counts() #所有获救的人是女性(female)的人数 df = pd.DataFrame({u'male':Survived_m, u'female':Survived_f}) #显示上述读取到的男性女性信息,以行和列形式来表示,行表示男,女;列表示是否生还 df.plot(kind = 'bar', stacked = True) # df.plot画图函数,类型(kind)为bar竖直条形图,stacked为true数据堆叠起来 plt.title(u'mf') #标题为u'mf' plt.xlabel(u'aa') #x轴标为u'aa' plt.ylabel(u'sss') #y轴标为u'sss' |
(5)
| Survived_0 = data.Embarked[data.Survived == 0].value_counts() #登船港口的死亡情况 Survived_1 = data.Embarked[data.Survived == 1].value_counts() #登船港口的存活情况 df = pd.DataFrame({u'aa':Survived_1,u'ssss':Survived_0}) #显示上述读取到的男性女性信息,以行和列形式来表示,aa表示活下来,ssss表示失事 df.plot(kind = 'bar', stacked = True) # df.plot画图函数,类型(kind)为bar竖直条形图,stacked为true数据堆叠起来 plt.title(u'ssssss') #条型图标题ssssss plt.xlabel(u'ssssss') #x轴标写ssssss plt.ylabel(u'cccccc') #y轴标写cccccc plt.show() |
(6)数据预处理,将无关的特征删除,填充缺失项,编码转换数据缩放。
| # 删除姓名、ID、船票、客舱等无关信息,axis=0 删除行,=1 删除列 data.drop(['Name','PassengerId','Ticket','Cabin'], axis=1, inplace=True) # 用平均值或众数填充缺失数据 data['Age'] = data['Age'].fillna(data['Age'].mean()) data['Fare'] = data['Fare'].fillna(data['Fare'].mean()) data['Embarked'] = data['Embarked'].fillna(data['Embarked'].value_counts().index[0]) # 将性别与登船港口进行独热编码 dumm = pd.get_dummies(data[['Sex','Embarked']], drop_first=True) data = pd.concat([data, dumm], axis=1) data.drop(['Sex','Embarked'], axis=1, inplace=True) # 数据缩放 data['Age']=(data['Age']-data['Age'].min())/(data['Age'].max()-data['Age'].min()) data['Fare']=(data['Fare']-data['Fare'].min())/( data['Fare'].max()-data['Fare'].min()) |
(7)划分训练集和测试集
| from sklearn.model_selection import train_test_split X = data.drop('Survived', axis=1) #X为存活下删除列后数据 y = data.Survived #y为存活数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) #预留30%数据用于评价模型 |
(8)模型构建及训练
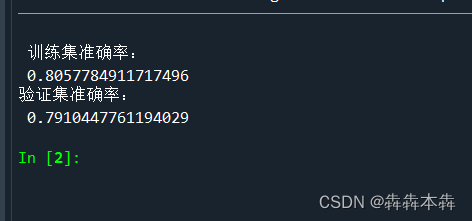
| from sklearn.linear_model import LogisticRegression LR = LogisticRegression() #构建训练模型 LR.fit(X_train, y_train) print('训练集准确率:\n', LR.score(X_train, y_train)) print('验证集准确率:\n', LR.score(X_test, y_test)) #test模型准确率 |
四、模型的评价和相关数据的可视化
1.评价
逻辑回归模型关于泰坦尼克号乘客生还能够达到较好的预测效果
2.图示化测量结果
(1)性别预测存活率
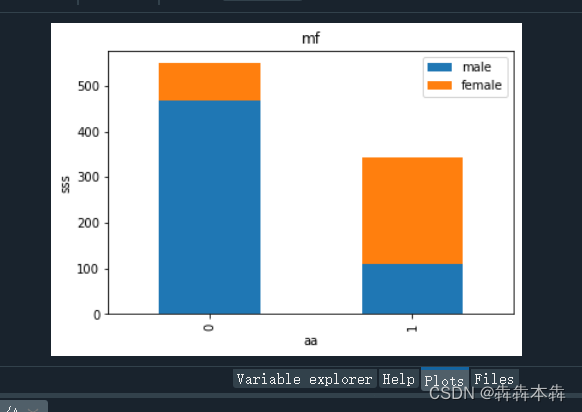
(2)登船港口预测

(3)数据
 (4)测试结果
(4)测试结果
(5)环境:anaconda3安装,Spider(Python3.8)下运行测试结果图
五.编者能力有限,仅供参考,欢迎指正。
















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











