






模型测试与部署
前情提要:TensorBoard可视化
TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
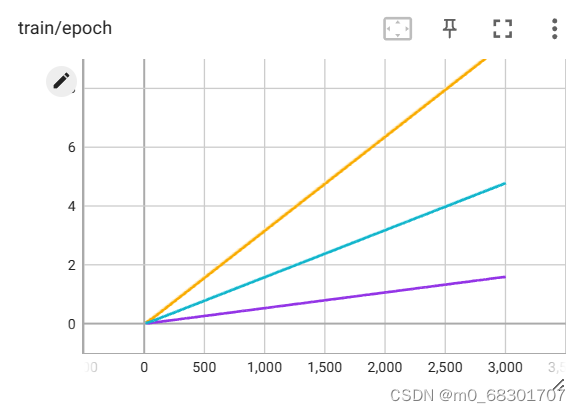
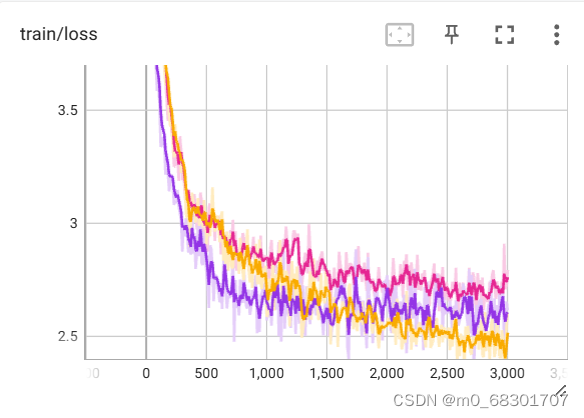
一. 单独调用测试
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModel, AutoConfig
import uvicorn, json, datetime
import torch
import os
def main():
pre_seq_len = 300
# 训练权重地址
checkpoint_path = "ptuning/output/adgen-chatglm2-6b-pt-300-15e-3/checkpoint-3000"
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=pre_seq_len)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, device_map="auto", trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(checkpoint_path, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
# 量化
model = model.quantize(4)
model.eval()
# 问题
question = "X光片显示,心脏大小正常、肺血管清晰。肺部无浸润或气胸的证据。骨质结构投有异常发现。给人的印象是,X射线检查没有发现急性心肺疾病的迹象。"
response, history = model.chat(tokenizer,
question,
history=[],
max_length=2048,
top_p=0.7,
temperature=0.95)
print("回答:", response)
if torch.backends.mps.is_available():
torch.mps.empty_cache()
if __name__ == '__main__':
main()
运行结果如下:

二. 封装成api测试
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModel, AutoConfig
import uvicorn, json, datetime
import torch
import os
app = FastAPI()
# 允许所有域的请求
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
if torch.backends.mps.is_available():
torch.mps.empty_cache()
return answer
if __name__ == '__main__':
pre_seq_len = 300
checkpoint_path = "ptuning/output/adgen-chatglm2-6b-pt-300-15e-3/checkpoint-3000"
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=pre_seq_len)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, device_map="auto", trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(checkpoint_path, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
## 量化
model = model.quantize(4)
model = model.cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8080, workers=1)运行结果如下:

首先需要建立SSH隧道连接:
ssh -L 8080:localhost:8080 xxxxxxxxxxxxxxxx -p xxx
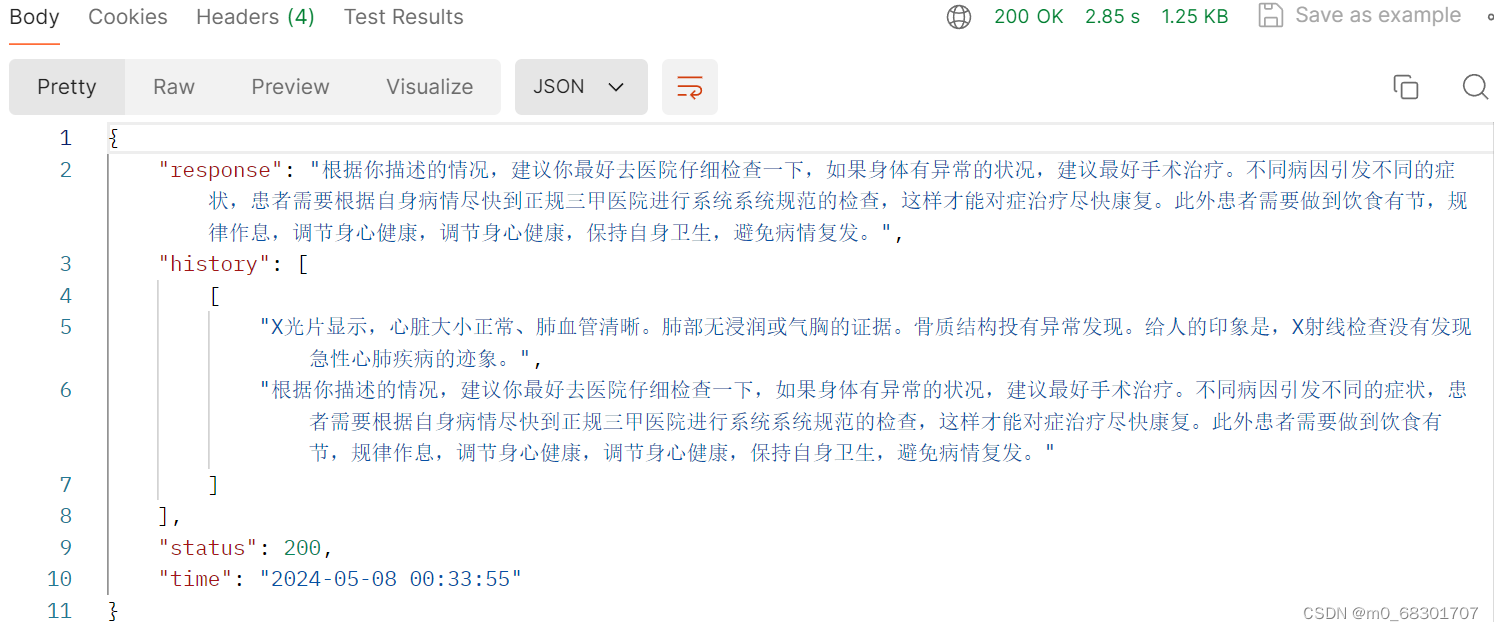
通过postman进行接口测试:
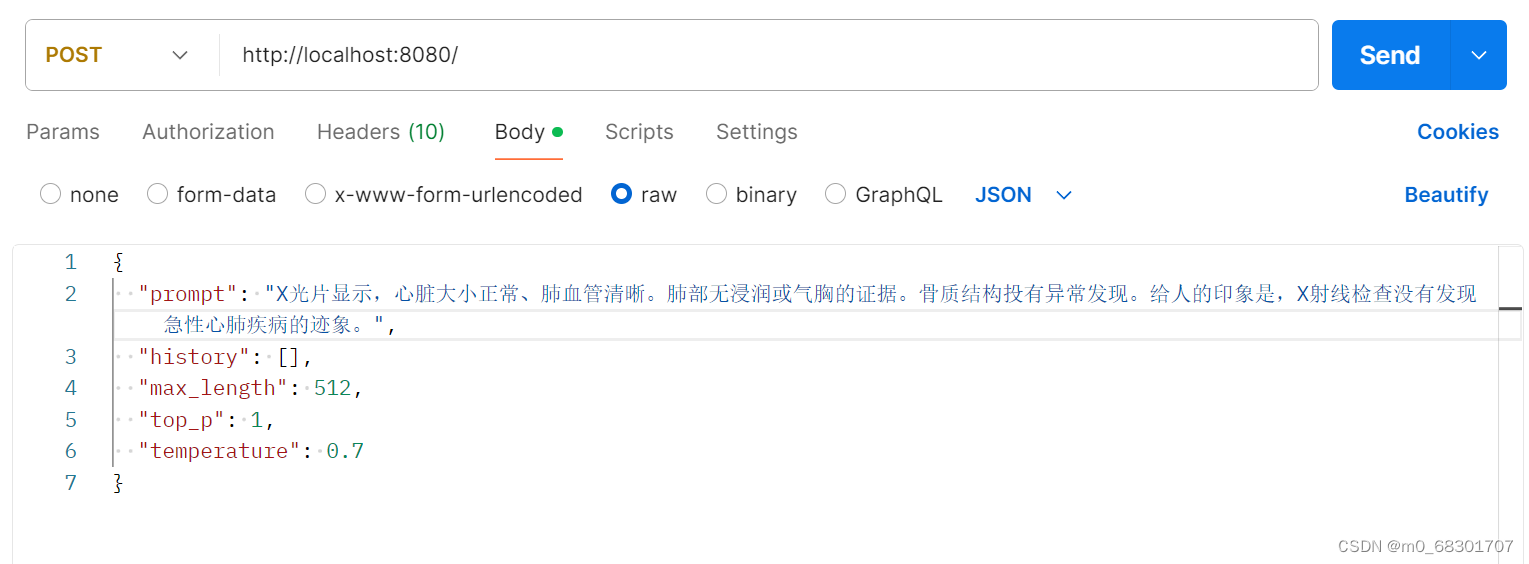















 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









