






摘要
本周对机器学习的可解释性进行了学习,机器学习的可解释性目标就是给出让人舒服的解释,是指对于机器学习模型的决策过程和结果能够被理解和解释的程度。通过提供可解释性,我们可以增强对模型的信任,并确保模型的决策是公平、可靠和可接受的。
ABSTRACT
This week, I studied the interpretability of machine learning. The goal of interpretability in machine learning is to provide explanations that are understandable and satisfactory to humans. It refers to the degree to which the decision-making process and outcomes of machine learning models can be understood and explained. By providing interpretability, we can enhance trust in the models and ensure that their decisions are fair, reliable, and acceptable.
一、Why we need Explainable ML?
一、正确的答案不等于聪明
下面举个例子,从前有一匹神马,“会计算数学题”,比方说,你问他根号9等于多少,它就会跺3下马蹄。但是人们后来发现,神马只有在很多人围观的时候才能算出数学题,当没有很多人围观的时候,它就会乱跺马蹄。所以,其实神马也许并不是真的会解数学题,它只是学会了在很多人围观的时候察言观色,根据人们的反应推断出什么时候该停下跺马蹄,这样它才就会有胡萝卜吃。

一、当机器学习用于决定银行是否要给一个人贷款的时候,根据法律,它必须给出一个理由
二、当机器学习用在医疗诊断上时,人命关天,AI必须给出一个诊断的理由,而不能仅仅是一个黑箱
三、当一个AI驱动的无人驾驶车进行急刹车后导致了后面的车追尾,那么这个无人驾驶车是否要负责任也要取决于它紧急刹车的理由。如果是因为前面有老太太在过马路,那么它急刹车就算对的;如果是无缘无故地急刹车,那这个AI就有问题了
四、更重要地是,如果机器学习是具有可解释性的,那我们就可以根据这个解释的结果去修正改进AI模型
二、Interpretable v.s. Powerful
一、一些模型是具有较强的可解释性的,例如线性模型,但是它不是 Powerful 的
二、Deep 的 Model 很难被解释,但是它比线性模型更加 Powerful
但是决策树模型不仅具有较强的 Powerful ,而且还具有较强的可解释性

但是,决策树模型也可能会很复杂(如下图左所示),此时也不太好解释
另外,我们通常不会使用一颗决策树去进行预测,而是使用一个森林(多个决策树),此时,森林又变成不好解释的了

三、Goal of Explainable ML
一、如下图所示,哈佛大学的一项研究表明,当人们在排队打印东西时:
如果一个人说“打扰一下,我有5张纸,可以让我先印吗”,此时接受率是60%
如果一个人说“打扰一下,我有5张纸,可以让我先印吗,因为我有急事”,此时接受率暴涨到了94%
如果一个人说“打扰一下,我有5张纸,可以让我先印吗,因为我需要先印”,此时接受率也高达93%

从上面的例子可以发现,有时候,不一定需要一个准确的理由才可以让人们接受,往往理由只需要能让人们感到舒服就可以了,所以,可解释性机器学习的目标就是可以给出让人们舒服的解释。
四、Explainable ML
可解释性的机器学习可分为两个解释方向,一个是局部的解释,另一个是全局的解释。
如下图所示:
一、局部的解释(对决策的原因进行解释):告诉我们为什么它认为图片上的是一只猫
二、全局的解释(总结决策的规律):告诉我们猫应该是什么样子的

一、Local Explanation: Explain the Decision
一、Which component is critical?
当你想知道模型决策的原因时,可以尝试找出输入特征中对模型决策影响最大的特征,然后进行分析
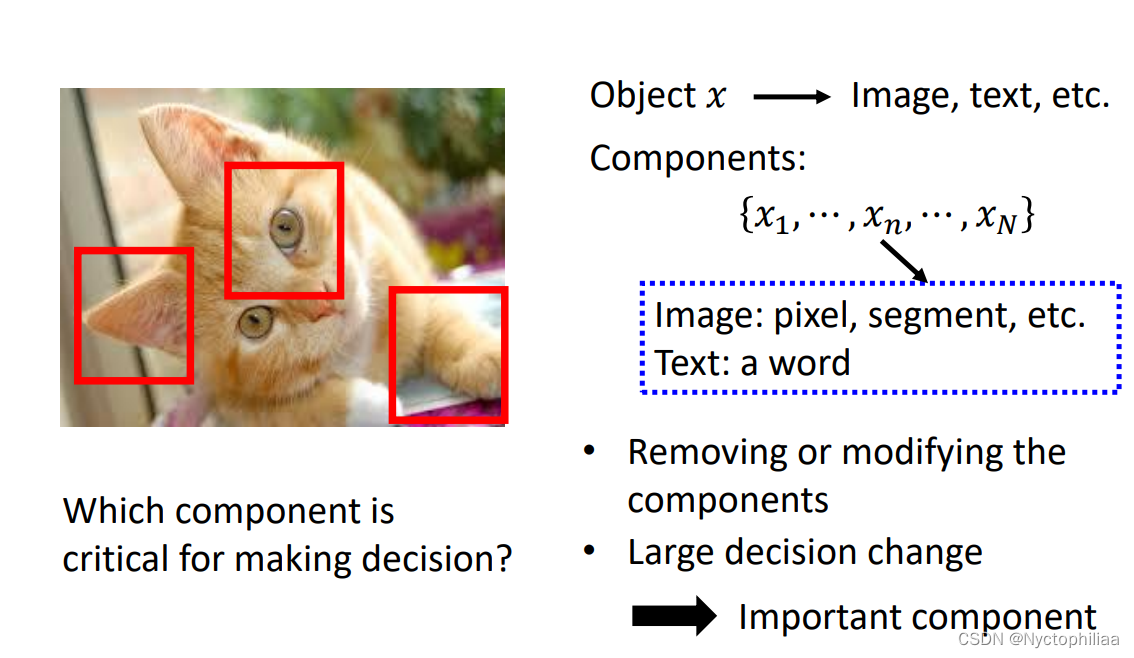
如下图所示,我们可以用一个灰色的方框作为干扰,在图片中进行滑动遍历,看看当灰色方框移动到什么位置的时候,模型识别出正确答案的概率比较低,哪里就是模型做出决策的主要依据。
比如下面的第一张图,灰色方框位于狗狗的脸处时,模型识别出狗狗的概率最低,位于其他位置时,模型仍然可以大概率识别出狗狗,所以模型是根据狗狗的脸去判断的,而不是看到了地板或、墙壁或者玩具球才觉得图片中的是狗,这就成为了一个解释!
还有一个办法,以图像为例,我们可以对某一个像素点做微小调整,设模型的输出变化为e+
,那么这个像素的重要程度可以用
表示,如下图所示,表明模型是真的看到了狗、猴、牛才做出的判断。

二、数码宝贝和宝可梦的分类应用
根据下图的6个训练资料,能不能认出Testing Image是属于宝可梦还是数码宝贝(答案是很难识别出来!)

人类都很难识别,那么机器的识别结果如何呢,有人做了实验,实验结果是非常不可思议的,模型在测试集上的识别率居然高达98%!

那么机器到底是如何分辨两者的?根据前面介绍的,我们可以绘制出每个测试图像的 Saliency Map ,看看机器是根据什么特征识别出宝可梦和数码宝贝的,结果很奇怪,机器认为重要的特征都完美地避开了宝可梦和数码宝贝的本体,也就是说,机器靠看背景就能很高正确率地识别出来。
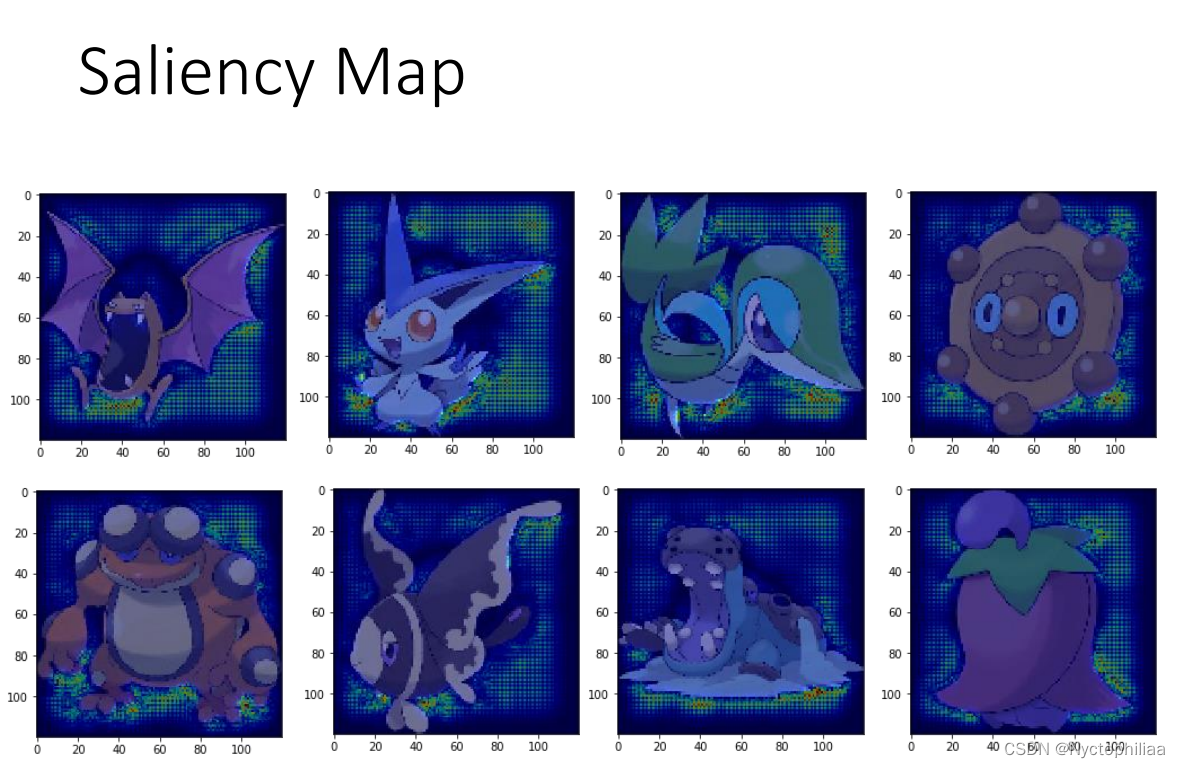
原因是什么?原来是因为宝可梦数据集(PNG)和数码宝贝数据集(JPEG)的图片格式不一样,PNG图像的背景是黑色的。和JPEG有很大差别,所以机器靠着识别背景,就能得到很高的正确率
三、How a network processes the input data?
一、Visualization
如下图所示,在语音辨识的例子里,在神经网络的每一层可能有100维的向量,维度太高不好可视化,我们可以将其降维(PCA或者其他方法),降到2维就好可视化了

二、Probing 探针
可视化观察模型学到了什么的方法很有局限性,因为我们在降维的过程中就已经损失掉了一些精度,并且肉眼观察也很难看出什么猫腻。
所以,就有了Probing 探针技术
我们可以创建一个独立的分类器,把网络某一层的输出作为它的训练资料,如果用该层的输出训练出来的分类器正确率很高,则说明该层具有很多有用的资讯
当然,有时候也要注意分类器的强度,正确率不高也可能是分类器太弱或者学习率没有调好等等原因导致的
当然,探针不一定要是分类器,如下图所示,探针是一个语音合成模型,它尝试吃被探测网络某一层的输出,目标是尽可能还原被探测网络最原始的输出。
显然,如果还原率越高,说明该层保留的咨询就越多。
有时候可能合成出来的语音准确的复现了源语音的内容,但是音色已经听不出来是谁了,说明被探测网络主要是通过提出语音内容的手段进行预测,这就为模型提供了一种解释

二、GLOBAL EXPLANATION: EXPLAIN THE WHOLE MODEL
如下图所示,假设已经有一个训练好的网络模型CNN
如果我们想知道这个CNN模型是怎么判断一张未知图片是否为猫的,那么可以找到它的任意一个卷积层(你想解释哪一层就找哪一层)
然后对于该卷积层的每一个 filter,都尝试找到一张图片 X,使得 X 经过 filter 之后得到的矩阵综合最大(可以用梯度上升法找这个X)
假设已经有了一个手写数字识别模型,用上面介绍的方法,我们可以得到下图所示的 X 集合,从中我们可以推测,如果将手写数字看为一些笔画的组合,那么模型卷积层的一些 filter 负责识别垂直的笔画,一些 filter 负责识别斜的笔画

但是,有些时候,按照这种方法提取出来的 X 很可能是人类看不出规律的,如下图所示
这不是令人惊讶的,因为我们学过恶意攻击就知道,给图片加上一点人类看不到的杂讯,就足以使得模型输出完全不同的结果,所以深层模型看到的东西往往是抽象、人类难以理解的

但是我想看到比较像数字的结果应该怎么办呢?一个简单粗暴的办法就是,对 X 施加一些限制,如下图所示,我们在最大化 sum(y) 的同时,也要最小化 X 中的像素总和,也就是用尽可能少的白点描述图像,这样有利于提高 X 的可解释性

我们也可以借助生成式网络来生成 X
如下图所示,假设有一个生成式网络G,我们可以给一组可训练的参数z,传入G得到X,然后再将X传入图像分类器CNN模型,目标是图像分类器给出的置信分数越高越好,此时最优的z称为z*,对应的X可以通过G(z)得到。
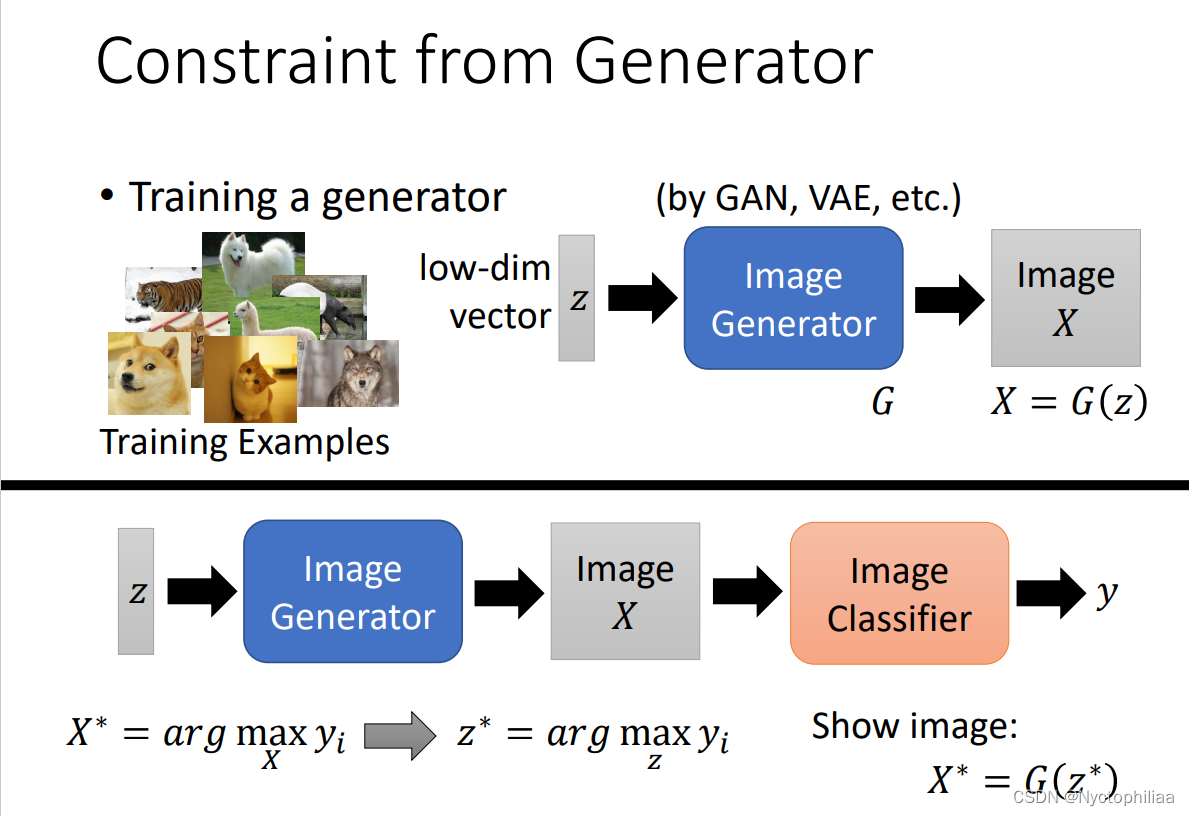
还有另外的方法如下图所示,我们可以用一个简单的容易解释的线性模型去模仿难以解释的深度模型,例如,我们给定同样的输入,目标是线性模型的输出和深度模型的输出越接近越好,以此训练出来的线性模型就会模仿深度模型,进而我们可以通过分析线性模型达到解释深度模型的效果
但是直接用线性模型模仿整个深度模型肯定是很难的,所以一般我们只用线性模型模仿深度模型的一部分,比如只对CNN的前两层进行模仿,这样就比较容易模仿,也容易解释
五、代码
一、线性模型
import numpy as np
import matplotlib.pyplot as plt
#给出三个简单的数据,虽然我们一眼能看出结果,但是我们看一下机器是怎么算的
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
#定义一个最简单的线性模型,一条直线
def forward(x):
return x*w
#定义损失函数,这样用的是MSE,即(预测值减去真实值)的平方
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
#存储w和损失的变化值
w_list = []
mse_list = []
#w在0和4之间,每次变化0.1
for w in np.arange(0.0,4.1,0.1) :
print('w=',w)
l_sum=0
for x_val,y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val,y_val)
l_sum+=loss_val
print('\t',x_val,y_val,y_pred_val,loss_val)
print('MSE=',l_sum / 3)
w_list.append(w)
mse_list.append(l_sum/ 3)这段代码是用最简单的线性模型,来预测当input是4时,output可能会是多少,训练结果如下:

使用Python的matplotlib库来绘制一个简单的折线图。具体来说,它使用plt.plot()函数来绘制折线图,其中w_list是横坐标数据,mse_list是纵坐标数据。
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()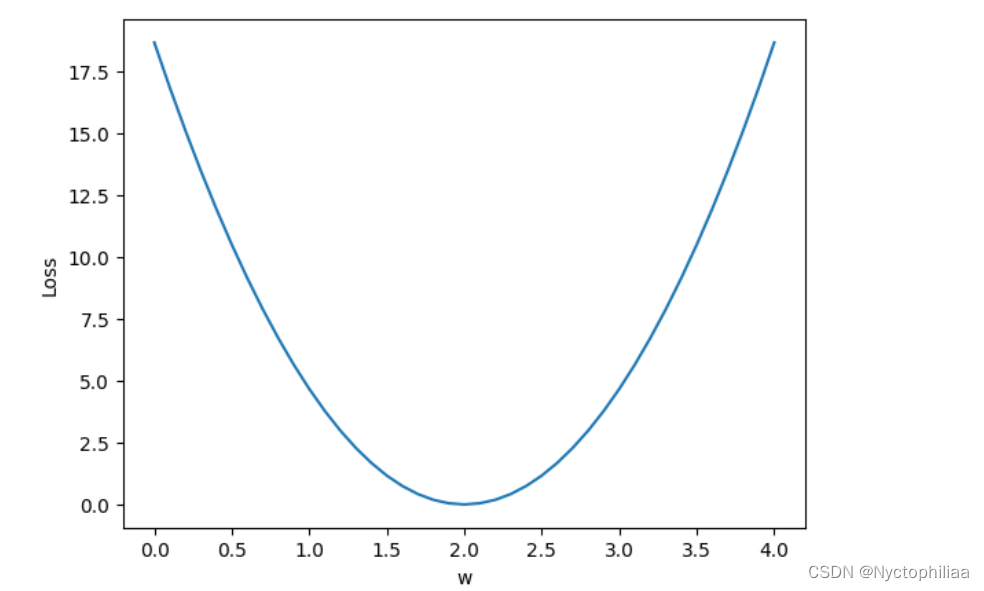
二、梯度下降
import numpy as np
import matplotlib.pyplot as plt
#训练数据集,假设初始w位1.0
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = 1.0
#定义最简单的线性模型
def forward(x):
return x*w
#定义损失函数,这里用的仍是MSE
def cost(xs,ys):
cost = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
cost +=(y_pred - y) ** 2
return cost/len(xs)
#定义梯度下降算法
def gradient(xs,ys):
grad = 0
for x,y in zip(xs,ys):
grad += 2 * x * (x*w-y)
return grad / len(xs)
#存放训练次数以及损失值
epoch_list=[]
loss_list=[]
#开始训练
print('Pedict (before training)',4,'%.2f'%forward(4))
for epoch in range(100):
cost_val=cost(x_data,y_data)
grad_val=gradient(x_data,y_data)
#0.01是自己定义的超参数
w -=0.01 * grad_val
print('Epoch:',epoch,'w=','%.2f'% w ,'loss=','%.2f' % cost_val)
epoch_list.append(epoch)
loss_list.append(cost_val)
print('Pedict (after training)',4,'%.2f'%forward(4))训练结果如下:

可以发现,当训练35次之后,loss的值已经为0,那么w的值我们就很好确定了,用matplotlib库来绘制一个简单的折线图:
plt.plot(epoch_list,loss_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()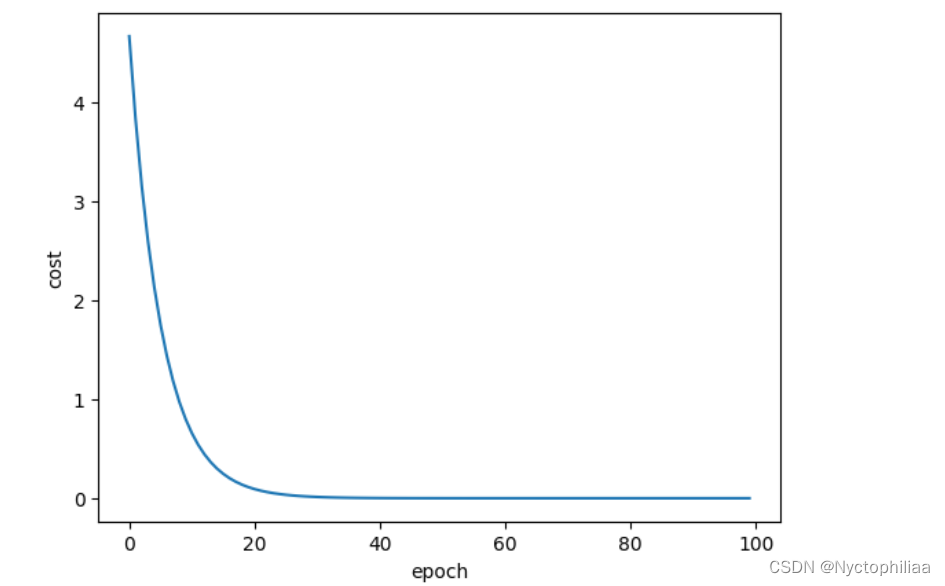
三、反向传播
import torch
#w是一个PyTorch张量(Tensor),
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w = torch.Tensor([1.0])
#这意味着PyTorch会自动计算关于w的梯度,以便在训练过程中进行参数更新。
w.requires_grad=True
#定义线性模型以及损失函数
def forward(x):
return x*w
def loss(x,y):
y_pred=forward(x)
return (y_pred - y) **2
#通过训练循环来更新权重参数w,并在最后进行结果预测
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print('\tgrad:', x, y, w.grad.item())
w.data = w.data -0.01 * w.grad.data
w.grad.data.zero_()
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item())运行结果如下:

总结
本周学习了关于机器学习可解释性的内容,并自己手动跑了一些简单模型的代码,通过这些代码,以及首推梯度,损失等对梯度下降以及反向传播有了更深刻的认识。















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









