






在当今这个信息爆炸的时代,数据就像一座蕴藏着无尽宝藏的矿山,等待着我们去挖掘。而抖音,作为全球最热门的短视频平台之一,每天都产生海量的用户评论。这些评论里,不仅有用户对视频内容最真实的看法,还藏着大众的喜好、情感倾向等宝贵信息,就像一个巨大的信息宝库。
对于商家来说,分析这些评论,能更精准地把握市场需求,从而优化产品和营销策略,吸引更多用户。比如,美妆品牌可以通过分析抖音上美妆视频的评论,了解用户对不同产品的评价和需求,进而推出更符合市场需求的新品。
对于研究者而言,抖音评论是研究社会舆论、文化趋势的绝佳素材。通过对大量评论的分析,可以洞察当下社会的热点话题和人们的思想动态。
今天,我就来给大家分享一下如何用 Python 实现抖音一级评论的采集代码,让我们一起开启这场数据探索之旅!
二、准备工作
(一)Python 环境搭建
在开始编写采集代码之前,首先要确保你的电脑上安装了 Python 环境。Python 有多个版本,目前 Python 2.x 已经停止更新,所以强烈推荐使用 Python 3.x 系列。如果你还没有安装 Python,可以前往 Python 官方网站(https://www.python.org/downloads/ )下载最新版本的安装包。
以 Windows 系统为例,下载完成后,双击安装包,在安装向导中记得勾选 “Add Python to PATH” 选项,这一步很关键,它会将 Python 的安装路径添加到系统环境变量中,这样你就可以在命令行中直接使用 Python 命令了。安装完成后,打开命令提示符,输入 “python --version”,如果显示出 Python 的版本号,那就说明安装成功啦!
(二)安装必要的库
- DrissionPage:这是一个非常强大的库,它集合了 WEB 浏览器自动化的便利性和 requests 的高效率优点。在我们的采集代码中,主要用它来控制浏览器,模拟用户操作,从而获取抖音页面上的数据。安装方法很简单,在命令行中输入 “pip install DrissionPage” 即可完成安装。它的功能十分丰富,比如可以无 webdriver 特征,不会被网站轻易识别;运行速度快,还能跨 iframe 查找元素,操作起来逻辑更加清晰 。
- random:random 库是 Python 的标准库,不需要单独安装。它主要用于生成随机数,在我们的代码中,通过random.randint(5000, 7000)来随机生成一个在 5000 到 7000 之间的整数,用于模拟滚动页面时的滚动距离,让我们的采集行为更接近真实用户操作,避免被网站反采集机制检测到。
- time:同样是 Python 的标准库,无需额外安装。time 库主要用于处理时间相关的操作。在代码中,我们使用time.sleep()函数来设置等待时间。比如time.sleep(5)表示程序暂停 5 秒,这样做是为了等待页面加载数据,确保我们能获取到完整的信息。在数据时,合理设置等待时间是非常重要的,可以避免因为页面还未加载完成就开始采集数据,导致数据不完整或采集失败。
- csv:也是 Python 标准库,用于处理 CSV 文件。CSV 是一种常用的文件格式,通常用于存储表格数据。我们的采集代码会将采集到的数据写入 CSV 文件中,方便后续的数据分析和处理。比如csv.DictWriter()函数可以将字典形式的数据写入 CSV 文件,writeheader()方法用于写入表头,writerow()方法用于写入一行数据 。
三、代码详解
(一)初始化与准备
import random
import time
import csv
from DrissionPage import ChromiumPage
# 创建文件对象
f = open('dataaa.csv', mode='w', encoding='utf-8', newline='')
# 字典写入的方法
csv_writer = csv.DictWriter(f, fieldnames=['videoLink', 'numberOfLikes', 'videoTitle', 'videoAuthor'])
# 写入表头
csv_writer.writeheader()
# 初始化浏览器
driver = ChromiumPage()
# 监控两个包
driver.listen.start('/aweme/v1/web/aweme/post/?')在这段代码中,首先导入了random、time、csv和ChromiumPage等必要的库。接着,创建了一个名为dataaa.csv的 CSV 文件,用于存储后续采集到的数据。使用csv.DictWriter创建了一个写入器对象csv_writer,并通过fieldnames参数指定了 CSV 文件的表头字段,包括videoLink(视频链接)、numberOfLikes(点赞数)、videoTitle(视频标题)和videoAuthor(视频作者),然后写入表头 。
然后,使用ChromiumPage初始化了一个浏览器对象driver,它将用于模拟浏览器操作,访问抖音页面。最后,通过driver.listen.start('/aweme/v1/web/aweme/post/?')开始监听指定的网络请求,这里监听的是/aweme/v1/web/aweme/post/?,以便捕获包含视频数据的数据包。
(二)访问抖音主页
# 访问目标用户的抖音主页
driver.get("https://www.douyin.com/user/MS4wLjABAAAALfl-SN83GkS_3yXCQvxMWq3BEKz0NnYRy0CzV4W--II?from_tab_name=main&vid=7464397602826554634")这行代码非常关键,它使用driver.get()方法访问指定的抖音用户主页。在实际应用中,你可以根据自己的需求修改链接,比如将其替换为你感兴趣的其他抖音用户主页链接,这样就能采集不同用户的视频数据了。通过访问用户主页,我们可以获取到该用户发布的视频列表等信息,为后续的数据采集做好准备。
(三)模拟滚动与数据采集
# 检查是否捕获到有效数据包
if not resp or not resp.response or not resp.response.body:
print('未捕获到数据包,或数据包内容为空,继续下一次尝试。')
continue
# 获取响应数据(已是字典类型)
json_data = resp.response.body
# 检查是否包含视频数据
if 'aweme_list' not in json_data:
print('视频数据未找到,跳过当前页。')
continue
# 提取视频数据
comments = json_data['aweme_list']
for index in comments:
# 提取所需内容
share_url = index.get('share_url', '') # 视频链接
digg_count = index['statistics'].get('digg_count', 0) # 点赞数
desc = index.get('desc', '') # 视频标题
nickname = index['author'].get('nickname', '') # 视频作者
# 将数据写入字典
data_dict = {
'videoLink': share_url,
'numberOfLikes': digg_count,
'videoTitle': desc,
'videoAuthor': nickname
}
# 写入CSV文件
csv_writer.writerow(data_dict)
print(data_dict)这里使用了一个外层循环for i in range(100)来控制模拟滚动的次数,理论上可以采集 100 页的数据。在每次循环中,首先打印当前正在采集的页码,然后使用time.sleep(5)暂停 5 秒,给页面足够的时间加载数据。
接着,通过内层循环for _ in range(3)来模拟多次滚动操作,每次滚动时,使用random.randint(5000, 7000)生成一个 5000 到 7000 之间的随机整数作为滚动距离,通过driver.actions.move_to('css=.pCVdP6Bb').scroll(scroll_amount, 0)实现对指定元素(这里通过 CSS 选择器.pCVdP6Bb定位)的滚动操作,每次滚动后暂停 1 秒 。
最后,使用driver.listen.wait(timeout=10)等待捕获数据包,设置超时时间为 10 秒,如果在 10 秒内捕获到数据包,就继续后续的数据处理操作;如果超时未捕获到数据包,则会进行相应的错误处理 。
(四)数据处理与存储
这段代码主要负责对捕获到的数据包进行处理和存储。首先,检查捕获到的数据包是否有效,如果resp、resp.response或resp.response.body为空,则打印提示信息并继续下一次尝试。
然后,获取响应数据并将其存储在json_data变量中。接着,检查json_data中是否包含aweme_list字段,该字段包含了视频数据,如果不存在,则打印提示信息并跳过当前页。
如果存在aweme_list,则遍历其中的每个视频数据,提取出视频链接、点赞数、视频标题和视频作者等信息,将这些信息存储在一个字典data_dict中,最后使用csv_writer.writerow(data_dict)将字典数据写入 CSV 文件,并打印出该字典数据 。
(五)完整代码展示
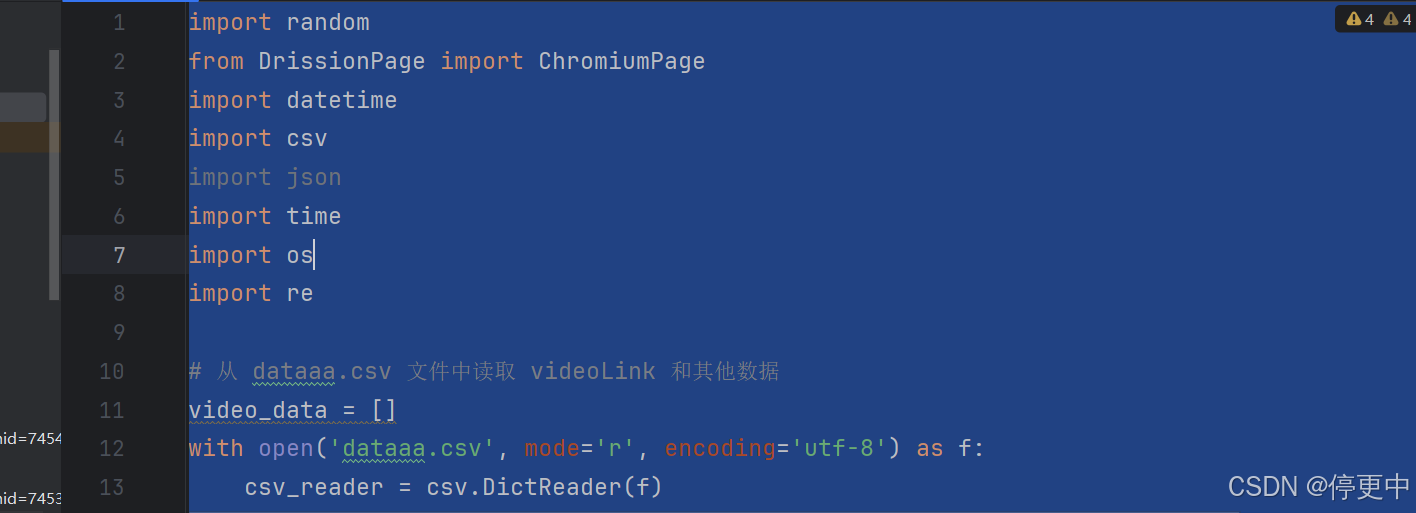
以上就是完整的抖音一级评论的代码,它涵盖了从初始化、访问页面、模拟滚动采集数据到数据处理和存储的整个过程。在实际运行代码时,你可以根据抖音页面的结构变化、反采集机制的调整等因素,对代码进行适当的优化和改进,以确保采集能够稳定、高效地运行 。
四、常见问题及解决方法
(一)数据包捕获失败
在运行采集代码时,有时会遇到未捕获到数据包,或数据包内容为空的情况。这可能是由以下原因导致的:
- 网络问题:不稳定的网络连接可能会导致无法捕获到数据包。比如,网络信号弱、网络中断等情况都可能影响数据的传输。你可以检查网络连接是否正常,尝试重新连接网络,或者更换网络环境。例如,从无线网络切换到有线网络,或者更换不同的 WiFi 热点。
- 超时设置不合理:如果设置的超时时间过短,在页面还未加载完成,数据包还未返回时,就可能导致捕获失败。你可以适当延长driver.listen.wait(timeout=10)中的超时时间,比如将其设置为 15 秒或 20 秒,给数据包的返回留出足够的时间 。
- 网站反采集机制:抖音为了保护用户数据和网站的正常运行,采取了一系列反采集措施。如果采集行为过于频繁或特征明显,就可能被抖音识别并限制访问,导致无法捕获到数据包。在代码中模拟滚动操作时,使用random.randint(5000, 7000)生成随机的滚动距离,让采集行为更接近真实用户操作,降低被反采集机制检测到的风险。同时,合理设置每次请求之间的时间间隔,避免短时间内发送大量请求。
(二)数据提取错误
在提取数据时,也可能会出现各种错误,比如提取的数据为空、数据格式不正确等。常见原因如下:
- 页面结构变化:抖音的页面结构可能会不定期更新,如果采集代码中使用的元素定位方式或数据提取规则没有及时更新,就可能导致数据提取失败。比如,原本通过'css=.pCVdP6Bb'来定位元素进行滚动操作,但抖音更新页面后,该元素的类名或位置发生了变化,就需要重新查找定位元素的方法。
- 数据格式不一致:抖音返回的数据格式可能并不总是一致的,某些视频数据可能缺少某些字段,或者字段的名称发生了变化。在提取点赞数时使用digg_count = index['statistics'].get('digg_count', 0),如果某个视频的statistics字段不存在,或者digg_count字段的名称变为其他,就可能导致提取失败。在提取数据时,使用get()方法并设置默认值,这样即使字段不存在,也能获取到一个默认值,避免程序出错 。
- 数据解析错误:如果在解析 JSON 数据时出现错误,也会导致数据提取失败。这可能是因为返回的数据不是标准的 JSON 格式,或者在解析过程中使用了错误的方法。在解析 JSON 数据时,使用try - except语句捕获异常,当解析出错时,能够及时处理,避免程序崩溃 。
五、注意事项
(一)遵守网站规则
在使用采集抖音数据时,一定要严格遵守抖音的使用条款和反采集机制。抖音作为一个拥有庞大用户群体和丰富数据的平台,为了保护用户隐私和数据安全,制定了一系列严格的规则。未经授权的大规模数据可能会侵犯用户隐私,甚至违反法律法规。在数据前,仔细阅读抖音的相关规则,确保自己的采集行为合法合规。
(二)避免频繁请求
控制请求频率是采集开发中非常重要的一点。如果在短时间内对抖音服务器发送大量请求,可能会导致服务器负载过高,影响正常用户的使用体验,同时也容易触发抖音的反采集机制,导致 IP 被封。为了避免这种情况,可以采取以下措施:
- 设置合理的请求间隔时间:在代码中使用time.sleep()函数,设置每次请求之间的时间间隔。比如,将time.sleep(5)设置为每次请求后暂停 5 秒,这样可以有效降低请求频率,减少被封 IP 的风险 。
- 随机化请求间隔:除了固定的时间间隔,还可以引入随机化的延迟,使采集的请求模式更接近真实用户的行为。比如使用random.uniform(3, 7)生成一个 3 到 7 秒之间的随机浮点数作为延迟时间,这样每次请求的间隔时间都不同,更难被反采集机制检测到 。
- 限制并发请求数量:如果使用多线程或多进程进行采集操作,要合理控制并发请求的数量。避免同时发起过多的请求,给服务器造成过大的压力。可以使用 Python 的threading.Semaphore(信号量)或multiprocessing.Semaphore来限制并发请求的数量 。
六、总结
通过今天的分享,我们一步步实现了用 Python 抖音一级评论的采集代码。从前期的环境搭建、库的安装,到代码的编写、调试,再到解决常见问题和注意事项,每一个环节都充满了挑战,但也正是这些挑战让我们不断成长和进步。
在这个过程中,我们深入了解了如何使用DrissionPage库来控制浏览器,模拟用户操作,以及如何通过监听网络请求获取所需的数据。同时,也学会了如何处理可能出现的各种问题,如数据包捕获失败、数据提取错误等,以及如何遵守网站规则,避免触发反采集机制 。

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









