







论文:MVTN: Multi-View Transformation Network for 3D Shape Recognition
代码:https://github.com/ajhamdi/MVTN
记录复现MVTN代码过程中,对于测试3D Shape Retrieval任务中的代码逻辑。
记录方式:断点调试+GPT
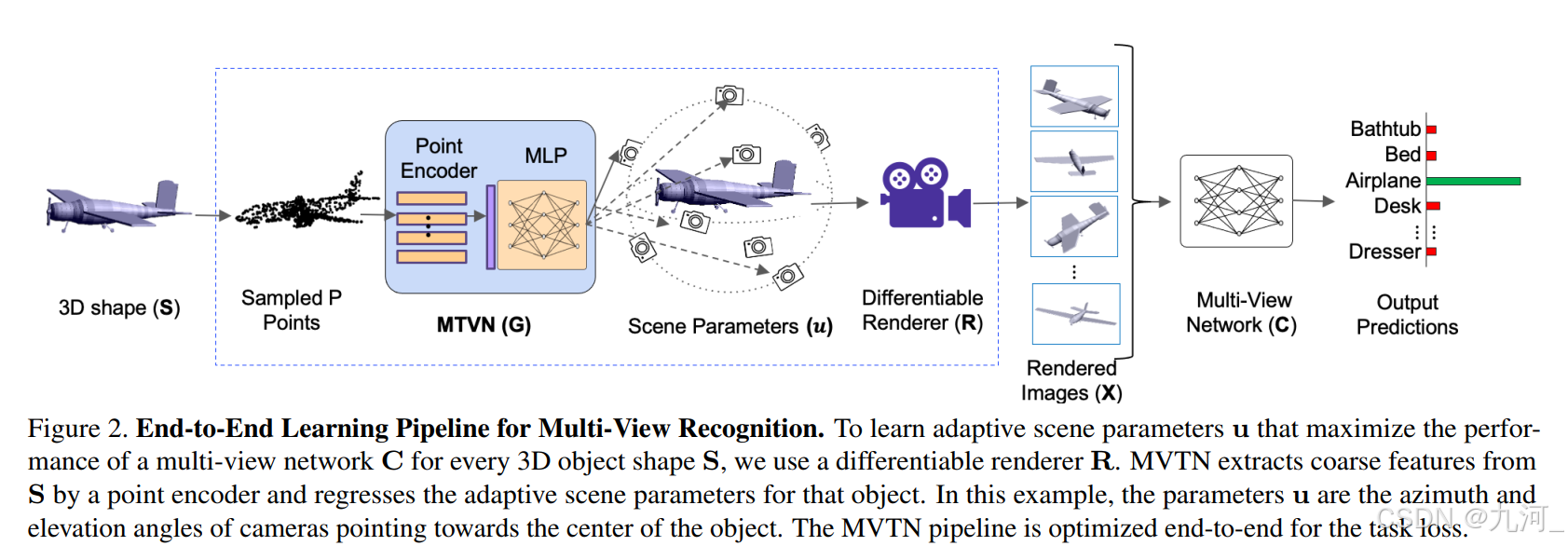
核心函数:
def evluate(data_loader, models_bag, setup, is_test=False, retrieval=False):
if is_test:
load_checkpoint(setup, models_bag, setup["weights_file"])
total = 0.0
correct = 0.0
total_loss = 0.0
n = 0
if retrieval:
features_training = np.load(setup["feature_file"])
targets_training = np.load(setup["targets_file"])
N_retrieved = 1000 if "shapenetcore" in setup["data_dir"].lower() else len(
features_training)
features_training = lfda.transform(features_training)
kdtree = scipy.spatial.KDTree(features_training)
all_APs = []
views_record = ListDict(
["azim", "elev", "dist", "label", "view_nb", "exp_id"])
t = tqdm(enumerate(data_loader), total=len(data_loader))
for i, (targets, meshes, points) in t:
with torch.no_grad():
c_batch_size = targets.shape[0]
azim, elev, dist = models_bag["mvtn"](
points, c_batch_size=c_batch_size)
rendered_images, _ = models_bag["mvrenderer"](
meshes, points, azim=azim, elev=elev, dist=dist)
targets = targets.cuda()
targets = Variable(targets)
outputs, feat = models_bag["mvnetwork"](rendered_images)
if retrieval:
feat = feat.cpu().numpy()
feat = lfda.transform(feat)
d, idx_closest = kdtree.query(feat, k=len(features_training))
for i_query_batch in range(feat.shape[0]):
positives = targets_training[idx_closest[i_query_batch, :]
] == targets[i_query_batch].cpu().numpy()
num = np.cumsum(positives)
num[~positives] = 0
den = np.array(
[i+1 for i in range(len(features_training))])
GTP = np.sum(positives)
AP = np.sum(num/den)/GTP
all_APs.append(AP)
loss = criterion(outputs, targets)
c_views = ListDict({"azim": azim.cpu().numpy().reshape(-1).tolist(), "elev": elev.cpu().numpy().reshape(-1).tolist(),
"dist": dist.cpu().numpy().reshape(-1).tolist(), "label": np.repeat(targets.cpu().numpy(), setup["nb_views"]).tolist(),
"view_nb": int(targets.cpu().numpy().shape[0]) * list(range(setup["nb_views"])),
"exp_id": int(targets.cpu().numpy().shape[0]) * int(setup["nb_views"]) * [setup["exp_id"]]})
views_record.extend(c_views)
total_loss += loss.item()
n += 1
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted.cpu() == targets.cpu()).sum()
avg_loss = total_loss / n
avg_test_acc = 100 * correct / total
if retrieval:
retr_map = 100 * sum(all_APs)/len(all_APs)
print("avg_loss", avg_loss)
print("avg_test_acc", avg_test_acc)
print("retr_map", retr_map)
return avg_test_acc, retr_map, avg_loss, views_record
# return torch.tensor(avg_test_acc), torch.tensor(retr_map), torch.tensor(avg_loss),torch.tensor(views_record)
# return avg_test_acc, avg_loss, views_record
return torch.tensor(avg_test_acc), torch.tensor(avg_loss), views_record
这个 evaluate 函数主要用于评估模型在分类和检索(retrieval)任务上的性能。下面是它的逐步解析:
函数参数
def evluate(data_loader, models_bag, setup, is_test=False, retrieval=False):
data_loader:用于加载测试数据集的DataLoader。models_bag:包含多个模型的字典,包括 MVTN(Multi-View Transformation Network)、渲染器(mvrenderer)和用于分类/检索的 MVNetwork(多视图网络)。setup:包含配置信息的字典,如weights_file(权重文件路径)、feature_file(存储特征的文件路径)等。is_test:布尔值,如果为True,则会加载预训练的权重。retrieval:布尔值,如果为True,则会执行特征检索任务,否则只进行分类评估。
1. 处理测试权重
if is_test:
load_checkpoint(setup, models_bag, setup["weights_file"])
如果 is_test 为 True,则会调用 load_checkpoint 加载模型的预训练权重。
2. 初始化评估变量
total = 0.0
correct = 0.0
total_loss = 0.0
n = 0
total:记录所有样本的总数。correct:记录分类正确的样本数。total_loss:累计损失值。n:计算平均损失时的分母。
3. 处理检索任务(Retrieval)
if retrieval:
features_training = np.load(setup["feature_file"])
targets_training = np.load(setup["targets_file"])
如果 retrieval 为 True,说明需要进行基于特征的检索任务:
- 加载
features_training:这是训练集中所有样本的特征向量,存储在setup["feature_file"]里。 - 加载
targets_training:这些是训练集中样本的类别标签。
N_retrieved = 1000 if "shapenetcore" in setup["data_dir"].lower() else len(features_training)
N_retrieved:如果数据集是 ShapeNetCore,则最多检索 1000 个样本;否则,检索整个训练集。
features_training = lfda.transform(features_training)
lfda.transform:对训练集的特征进行转换(可能是降维或其他特征变换)。
kdtree = scipy.spatial.KDTree(features_training)
kdtree:构建 KD 树(K-Dimensional Tree),用于加速最近邻搜索。KD 树是一种数据结构,适用于高维空间中的最近邻搜索。
all_APs = []
all_APs:用于存储所有查询的平均精度(AP)。
4. 遍历数据集
views_record = ListDict(["azim", "elev", "dist", "label", "view_nb", "exp_id"])
t = tqdm(enumerate(data_loader), total=len(data_loader))
for i, (targets, meshes, points) in t:
views_record:用于记录视角信息(方位角azim、仰角elev、距离dist、标签label等)。tqdm:用于显示进度条。- 遍历
data_loader,其中:targets:样本的真实类别标签。meshes:3D 网格数据。points:3D 点云数据。
5. 计算视角并渲染多视图图像
with torch.no_grad():
c_batch_size = targets.shape[0]
azim, elev, dist = models_bag["mvtn"](points, c_batch_size=c_batch_size)
rendered_images, _ = models_bag["mvrenderer"](meshes, points, azim=azim, elev=elev, dist=dist)
models_bag["mvtn"]:使用 MVTN(Multi-View Transformation Network)预测最佳视角(azim方位角,elev仰角,dist观察距离)。models_bag["mvrenderer"]:使用渲染器在这些视角下渲染 2D 图像。
6. 进行分类
targets = targets.cuda()
targets = Variable(targets)
outputs, feat = models_bag["mvnetwork"](rendered_images)
targets.cuda():将标签数据移动到 GPU。models_bag["mvnetwork"](rendered_images):使用 MVCNN 进行前向传播:outputs:分类的输出(logits)。feat:用于检索任务的特征向量。
7. 处理检索任务
if retrieval:
feat = feat.cpu().numpy()
feat = lfda.transform(feat)
d, idx_closest = kdtree.query(feat, k=len(features_training))
feat.cpu().numpy():将特征转换为 NumPy 数组。lfda.transform(feat):对测试样本的特征进行相同的变换。kdtree.query(feat, k=len(features_training)):- 计算测试样本与训练集中所有样本的欧氏距离,并返回
k个最近的训练样本索引idx_closest。
- 计算测试样本与训练集中所有样本的欧氏距离,并返回
for i_query_batch in range(feat.shape[0]):
positives = targets_training[idx_closest[i_query_batch, :]] == targets[i_query_batch].cpu().numpy()
positives:一个布尔数组,表示最近邻检索结果是否属于相同类别。
num = np.cumsum(positives)
num[~positives] = 0
den = np.array([i+1 for i in range(len(features_training))])
GTP = np.sum(positives)
AP = np.sum(num/den)/GTP
all_APs.append(AP)
- 计算 平均精度(AP):
num:计算positives的累积和,即随着排名的增加,正确检索出的样本数。den:对应排名索引 1, 2, 3,…。GTP:检索出的所有正样本数。AP:平均精度,计算公式为:
A P = 1 G T P ∑ i = 1 N num [ i ] den [ i ] AP = \frac{1}{GTP} \sum_{i=1}^{N} \frac{\text{num}[i]}{\text{den}[i]} AP=GTP1i=1∑Nden[i]num[i]all_APs.append(AP):存储所有查询的 AP 值。
8. 计算损失
loss = criterion(outputs, targets)
total_loss += loss.item()
n += 1
criterion(outputs, targets):计算分类损失,并累加到total_loss。
9. 计算分类准确率
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted.cpu() == targets.cpu()).sum()
torch.max(outputs.data, 1)取出每个样本预测的类别索引。- 统计正确分类的样本数。
10. 计算最终结果
avg_loss = total_loss / n
avg_test_acc = 100 * correct / total
- 计算平均损失和准确率。
if retrieval:
retr_map = 100 * sum(all_APs)/len(all_APs)
return avg_test_acc, retr_map, avg_loss, views_record
- 计算 mAP(均值平均精度) 并返回。
return torch.tensor(avg_test_acc), torch.tensor(avg_loss), views_record
- 否则,返回准确率、损失和视角记录。
总结
- 分类部分:计算准确率和损失。
- 检索部分:
- 构建 KD 树,加速最近邻搜索。
- 计算 AP 和 mAP。
- 返回检索指标。
细节理解
outputs, feat = models_bag"mvnetwork"
if retrieval:
feat = feat.cpu().numpy()
feat = lfda.transform(feat)
d, idx_closest = kdtree.query(feat, k=len(features_training))
在这部分代码中outputs的维度是(20,40),因为一个batchsize=20,feat的维度是(20,512),经过lfda.transform变换后,feat的维度变成(20,128),而features_training的维度是(9840,128)。请解释为什么lfda.transform(feat)能将维度转变为128维,KDtree构建的过程,以及d和idx_closet变量代表什么含义。
我们逐步拆解这部分代码的工作原理,并详细解释涉及的维度变化、KDTree 的构建以及 d 和 idx_closest 的含义。
1. outputs, feat = models_bag["mvnetwork"](rendered_images)
models_bag["mvnetwork"]是一个神经网络,接收rendered_images作为输入。outputs的形状(20, 40):- 这里的
40可能是分类任务的类别数(即网络的输出是一个 40 维的概率分布)。 20是 batch size,即一次处理 20 个样本。
- 这里的
feat的形状(20, 512):feat是模型的特征表示,可能是网络的倒数第二层或某个嵌入层的输出。- 该特征用于检索任务,而
outputs主要用于分类任务。
2. feat = lfda.transform(feat)
lfda.transform(feat)是LFDA(Local Fisher Discriminant Analysis)方法的transform操作,它是一种用于度量学习的方法。- 作用:将特征
feat从512维降至128维,以便提高相似性计算的效果,同时降低计算复杂度。 - 维度变化:
feat原始维度:(20, 512)lfda.transform(feat)后的维度:(20, 128)features_training维度:(9840, 128)
为什么维度变成 128?
LFDA通过学习数据的局部结构,并结合监督信息(类标签),找到一个低维投影空间(这里是128维),使得相同类别的样本尽可能靠近,不同类别的样本尽可能分开。- 训练
LFDA时,我们预设投影空间的维度,即lfda.transform(feat)输出128维嵌入。
3. kdtree = scipy.spatial.KDTree(features_training)
- 这里
features_training形状(9840, 128),表示训练集中 9840 个样本的 128 维特征向量。 KDTree(K-Dimensional Tree)是一种加速最近邻搜索的空间分割数据结构,适用于高维空间的最近邻检索。- 作用:创建一个
KDTree,以features_training作为索引数据,使后续的最近邻搜索高效进行。
4. d, idx_closest = kdtree.query(feat, k=len(features_training))
kdtree.query(feat, k=len(features_training))用于执行最近邻搜索:feat:当前 batch 计算出的 128 维特征(20, 128)。k=len(features_training):设定返回所有训练数据的距离和索引,通常是9840。
返回值
-
d(shape:(20, 9840)):- 计算出的
feat中每个样本到features_training所有 9840 个样本的欧几里得距离。 - 例如
d[i, j]表示feat[i]到features_training[j]的距离。
- 计算出的
-
idx_closest(shape:(20, 9840)):- 训练集中与
feat最相近的样本索引。 - 例如
idx_closest[i, j]表示feat[i]最近的第j个样本在features_training中的索引。
- 训练集中与
示例
假设 feat[0] 的最近 3 个邻居在 features_training 中的索引是 [567, 890, 234],则:
idx_closest[0, :3] = [567, 890, 234]
而 d[0, :3] 可能是:
d[0, :3] = [0.12, 0.23, 0.34] # 表示到这三个最近邻的距离
5. 总结
lfda.transform(feat)通过度量学习将512维特征降维到128维,以便提高检索的效率和效果。KDTree利用features_training构建高效的数据结构,使得最近邻搜索更快。kdtree.query(feat, k=len(features_training))返回:d:batch 内每个样本到所有9840个样本的距离((20, 9840))。idx_closest:batch 内每个样本最近的训练样本索引((20, 9840))。
for i_query_batch in range(feat.shape[0]):
positives = targets_training[idx_closest[i_query_batch, :]]
== targets[i_query_batch].cpu().numpy()
num = np.cumsum(positives)
num[~positives] = 0
den = np.array(
[i+1 for i in range(len(features_training))])
GTP = np.sum(positives)
AP = np.sum(num/den)/GTP
all_APs.append(AP)
请对这个循环代码做出解释。 注意,targets_training的维度是(9840,),targets的维度是(20,)
这个 for 循环的作用是计算 平均精度(AP, Average Precision),用于评估检索任务的性能。我们逐行解析这段代码的含义,并结合 targets_training 和 targets 的维度详细解释。
1. 遍历 Batch 内的每个样本
for i_query_batch in range(feat.shape[0]):
feat.shape[0]是20,表示当前 batch 中有 20 个查询样本。- 这个
for循环遍历 batch 内的每个查询样本i_query_batch。
2. 计算当前查询样本的正例(positives)
positives = targets_training[idx_closest[i_query_batch, :]] == targets[i_query_batch].cpu().numpy()
idx_closest[i_query_batch, :]:- 取出当前
i_query_batch的9840个最近邻索引(idx_closest维度为(20, 9840))。
- 取出当前
targets_training[idx_closest[i_query_batch, :]]:targets_training形状是(9840,),表示训练集中每个样本的类别标签。- 这里索引
idx_closest[i_query_batch, :],获取 查询样本i_query_batch的 9840 个最近邻样本的类别标签。
targets[i_query_batch].cpu().numpy():targets形状是(20,),表示 batch 内 20 个查询样本的类别标签。- 这里取出
i_query_batch的真实类别。
==进行比较:- 生成一个布尔数组
positives(形状(9840,)),表示idx_closest[i_query_batch, :]里的每个样本是否与targets[i_query_batch]具有相同类别。 - 如果
True,表示该最近邻是正确的匹配(正例);否则是错误的匹配(负例)。
- 生成一个布尔数组
示例
假设:
targets_training = np.array([1, 2, 3, 1, 2, 3, 1, ...]) # 训练集的标签
targets[i_query_batch] = 2 # 查询样本的真实类别
idx_closest[i_query_batch, :5] = [3, 1, 7, 5, 2] # 最近邻索引
则:
targets_training[idx_closest[i_query_batch, :5]] = [1, 2, 1, 3, 2]
那么 positives[:5] 结果为:
[False, True, False, False, True]
3. 计算累积 TP 数量
num = np.cumsum(positives)
np.cumsum(positives)计算positives数组的累计和。- 例如:
positives = [False, True, False, False, True, True, False] np.cumsum(positives) # [0, 1, 1, 1, 2, 3, 3] - 这表示:
num[i]是 前i+1个最近邻中,正确匹配的总数(累积 True 的个数)。
4. 处理非正例的位置
num[~positives] = 0
- 这个操作把
positives == False位置的num值 归零:positives = [False, True, False, False, True, True, False] num = [0, 1, 1, 1, 2, 3, 3] num[~positives] = 0 # [0, 1, 0, 0, 2, 3, 0] - 这样做的目的是确保只有真正的正例位置才会被计算进
AP公式。
5. 计算归一化的分母
den = np.array([i+1 for i in range(len(features_training))])
- 这里
den是[1, 2, 3, ..., 9840],表示排名从1到9840的位置编号。 - 目的是作为
Precision的分母,表示当前检索到的i个样本中,有多少是正确的。
6. 计算 AP
GTP = np.sum(positives)
GTP(Ground Truth Positives):表示总共有多少个正例(即positives数组中True的个数)。- 例如:
positives = [False, True, False, False, True, True, False] GTP = np.sum(positives) # 3 - 如果
GTP = 0,说明该查询样本没有任何正例,则AP计算无意义。
AP = np.sum(num/den)/GTP
num/den计算 Precision:num是 累计 TP,den是 排名序号。num/den计算每个正确匹配的精度。- 例如:
num = [0, 1, 0, 0, 2, 3, 0] den = [1, 2, 3, 4, 5, 6, 7] num/den = [0.0, 0.5, 0.0, 0.0, 0.4, 0.5, 0.0]
AP(Average Precision) 计算:AP = np.sum(num/den)/GTP- 只对 正例位置 计算 Precision 的均值,衡量模型的排名效果。
7. 记录 AP
all_APs.append(AP)
AP计算完成后,存入all_APs,用于计算mAP(Mean Average Precision)。- 最后
retr_map = 100 * sum(all_APs)/len(all_APs)计算整个测试集的 mAP。
总结
这段代码实现了 检索任务的 AP 计算:
- 遍历 batch 内的每个查询样本
i_query_batch。 - 获取其最近
9840个邻居的类别标签targets_training[idx_closest[i_query_batch, :]]。 - 计算哪些最近邻是 正确的正例 (
positives)。 - 计算 累积 TP (
num),并在负例位置置零 (num[~positives] = 0)。 - 计算 Precision (
num/den) 并计算 AP。 - 记录所有
AP,最终计算mAP。
mAP 作为检索任务的评估指标,越高表示模型检索的相关性越好。

















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









