1. 交互式
即时得到程序的运行结果
2. 脚本方式
把程序写到文件里( 约定俗称文件名后缀为. py) , 然后用python解释器解释执行其中的内容
python3. 8 C: \a\b\c. py
1. 先启动python3. 8 解释器, 此时相当于启动了一个文本编辑器
2. 解释器会发送系统调用,把c. py的内容从硬盘读入内存,此时c. py中的内容全部为普通字符, 没有任何语法意义
3. 解释器开始解释执行刚刚读入内存的c. py的代码,开始识别python语法
变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
答:为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的
详细地说:
程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,
所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
1. 变量基本使用
name = 'egon'
print ( name)
2. 内存管理: 垃圾回收机制
垃圾: 当一个变量值被绑定的变量名的个数为0 时,该变量值无法被访问到- - - 垃圾
3. 变量名的命名规则
原则: 变量名的命名应该见名知意
1. 变量名只能是 字母、数字或下划线的任意组合
2. 变量名的第一个字符不能是数字
3. 关键字不能声明为变量名,常用关键字如下
[ 'and' , 'as' , 'assert' , 'break' , 'class' ,
'continue' , 'def' , 'del' , 'elif' , 'else' ,
'except' , 'exec' , 'finally' , 'for' , 'from' ,
'global' , 'if' , 'import' , 'in' , 'is' , 'lambda' ,
'not' , 'or' , 'pass' , 'print' , 'raise' , 'return' ,
'try' , 'while' , 'with' , 'yield' ]
4. 变量名的命名风格
age_of_alex = 73
print ( age_of_alex)
AgeOfAlex= 73
print ( AgeOfAlex)
5. 变量值的三大特性
name = 'egon'
反应的是变量在内存中的唯一编号,内存地址不同id 肯定不同
print ( id ( name) )
变量值的类型
print ( type ( name) )
变量值
print ( name)
is : 比较左右两个值身份id 是否相等
== : 比较左右两个值他们的值是否相等
作用: 用来记录人的年龄,出生年份,学生人数等整数相关的状态
作用: 用来记录人的身高,体重,薪资等小数相关的状态
作用:用来记录人的名字,家庭住址,性别等描述性质的状态
用单引号、双引号、多引号,都可以定义字符串,本质上是没有区别的,但是
msg = "My name is Tony , I'm 18 years old!"
msg = '''
天下只有两种人。比如一串葡萄到手,一种人挑最好的先吃,另一种人把最好的留到最后吃。
照例第一种人应该乐观,因为他每吃一颗都是吃剩的葡萄里最好的;第二种人应该悲观,因为他每吃一颗都是吃剩的葡萄里最坏的。
不过事实却适得其反,缘故是第二种人还有希望,第一种人只有回忆。
'''
索引对应值,索引从0 开始,0 代表第一个
作用: 记录多个值,并且可以按照索引取指定位置的值
定义: 在[ ] 内用逗号分隔开多个任意类型的值,一个值称之为一个元素
>> > stu_names= [ '张三' , '李四' , '王五' ]
>> > stu_names[ 0 ]
'张三'
>> > stu_names[ 1 ]
'李四'
>> > stu_names[ 2 ]
'王五'
>> > students_info= [ [ 'tony' , 18 , [ 'jack' , ] ] , [ 'jason' , 18 , [ 'play' , 'sleep' ] ] ]
>> > students_info[ 0 ] [ 2 ] [ 0 ]
'play'
内置方法:
1. 按索引存取值( 正向存取+ 反向存取)
l = [ 111 , 'egon' , 'hello' ]
print ( l[ 0 ] )
print ( l[ - 1 ] )
l[ 0 ] = 222
print ( l)
print ( l[ 0 : 5 : 2 ] )
print ( len ( l) )
print ( 'aaa' in [ 'aaa' , 1 , 2 ] )
print ( 1 in [ 'aaa' , 1 , 2 ] )
l. append( 3333 )
print ( l)
l. insert( 1 , 'alex' )
print ( l)
new_l = [ 1 , 2 , 3 ]
for i in new_l:
l. append( i)
print ( l)
l. extend( new_l)
print ( l)
del l[ 1 ]
print ( l)
l. pop( 0 )
print ( l)
l. remove( 'egon' )
print ( l)
key对应值,其中key通常为字符串类型,所以key对值可以有描述性的功能
作用: 用来存多个值,每个值都有唯一一个key与其对应,key对值有描述性功能
定义: 在{
} 内用逗号分开各多个key: value
>> > person_info= {
'name' : 'tony' , 'age' : 18 , 'height' : 185.3 }
>> > person_info[ 'name' ]
'tony'
>> > person_info[ 'age' ]
18
>> > person_info[ 'height' ]
185.3
>> > students= [
. . . {
'name' : 'tony' , 'age' : 38 , 'hobbies' : [ 'play' , 'sleep' ] } ,
. . . {
'name' : 'jack' , 'age' : 18 , 'hobbies' : [ 'read' , 'sleep' ] } ,
. . . {
'name' : 'rose' , 'age' : 58 , 'hobbies' : [ 'music' , 'read' , 'sleep' ] } ,
. . . ]
>> > students[ 1 ] [ 'hobbies' ] [ 1 ]
'sleep'
作用: 用来记录真假这两种状态
定义:
>> > is_ok = True
>> > is_ok = False
通常用来当作判断的条件,我们将在if 判断中用到它
x= 10
print ( id ( x) )
y= x
z= x
l= [ 'a' , 'b' , x]
print ( id ( l[ 2 ] ) )
d = {
'mmm' : x}
print ( id ( d[ 'mmm' ] ) )
l1 = [ 111 , ]
l2 = [ 222 , ]
l1. append( l2)
l2. append( l1)
print ( id ( l1[ 1 ] ) )
print ( id ( l2) )
print ( id ( l2[ 1 ] ) )
print ( id ( l1) )
print ( l2)
print ( l1[ 1 ] )
del l1
del l2
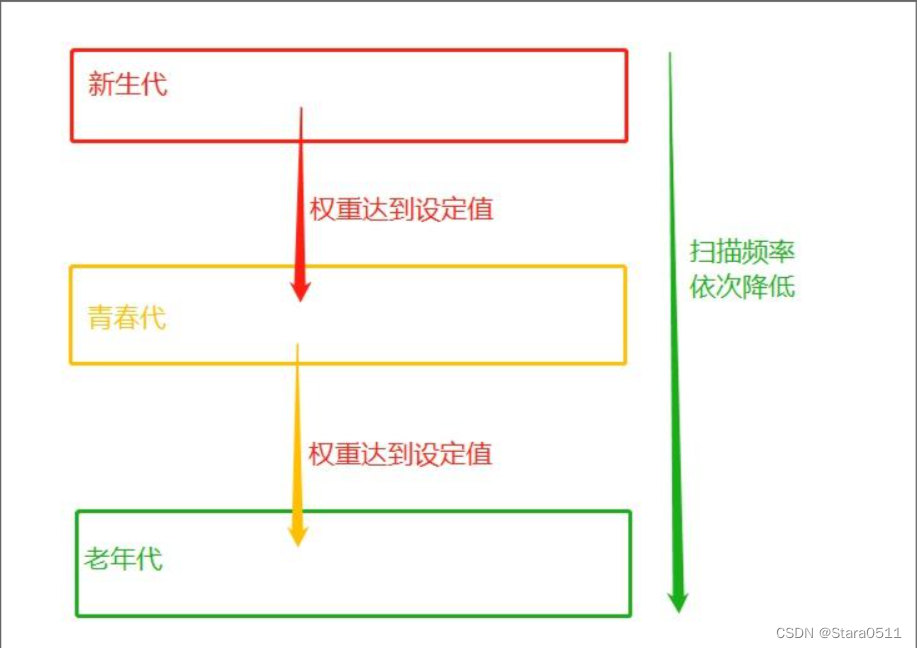
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1 分钟扫描新生代一次,
如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,
当变量的权重大于某个设定得值(假设为3 ),会将它移动到更高一级的青春代,
青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5 分钟扫描青春代一次,
这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低
print ( '%s asked %s to do something' % ( 'egon' , 'lili' ) )
print ( '%s asked %s to do something' % ( 'lili' , 'egon' ) )
print ( '我的名字是 %(name)s, 我的年龄是 %(age)s.' % {
'name' : 'egon' , 'age' : 18 } )
kwargs= {
'name' : 'egon' , 'age' : 18 }
print ( '我的名字是 %(name)s, 我的年龄是 %(age)s.' % kwargs)
print ( '{} asked {} to do something' . format ( 'egon' , 'lili' ) )
print ( '{} asked {} to do something' . format ( 'lili' , 'egon' ) )
print ( '{0}{0}{1}{0}' . format ( 'x' , 'y' ) )
print ( '我的名字是 {name}, 我的年龄是 {age}.' . format ( age= 18 , name= 'egon' ) )
kwargs = {
'name' : 'egon' , 'age' : 18 }
print ( '我的名字是 {name}, 我的年龄是 {age}.' . format ( ** kwargs) )
print ( '{0:*<10}' . format ( '开始执行' ) )
print ( '{0:*>10}' . format ( '开始执行' ) )
print ( '{0:*^10}' . format ( '开始执行' ) )
print ( '{salary:.3f}' . format ( salary= 1232132.12351 ) )
print ( '{0:b}' . format ( 123 ) )
print ( '{0:o}' . format ( 9 ) )
print ( '{0:x}' . format ( 15 ) )
print ( '{0:,}' . format ( 99812939393931 ) )
name = 'egon'
age = 18
print ( f' {
name} {
age} ' )
print ( F' {
age} {
name} ' )
print ( f' {
3 * 3 / 2 } ' )
def foo ( n)








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











