







一、理论学习
1.0、概念
- 1、方差分析(ANOVA)用于研究一个或多个分类型自变量与一个数值型因变量的关系。方差分析通过检验多个总体(同属于一个大整体)的均值是否相等来判断一个或多个分类型自变量对数值型因变量是否由显著影响。
- 2、方差分析包含的三个重要概念:(以小学六年级的学习成绩为例)
- 因子:分类型自变量。例如:六年级的所有班级
- 水平:某个因子下的不同取值。例如六年级有一班、二班、三班。
- 观测值:每个因子水平下的样本观测值。例如:六年级三个班各自的学生成绩。
1.1、单因素方差分析
1.1.1、概念理解
- 1、单因素方差分析就是只有一个因子自变量对因变量的影响。例如,地区差异是否影响农作物的产量,人们的学历对工资收入的影响等。这些问题都可以通过单因素方差分析得到答案。
- 2、方差分析满足条件
- 各实验总体均服从正态分布;
- 各实验均独立;
- 方差齐性假设:H0:各实验的总体方差均相等
- 3、、单因素方差分析步骤:
- 1、明确观测变量和控制变量。上述问题中的观测变量分别是农作物产量和工资收入;控制变量(自变量)分别为地区和学历。
- 2、剖析观测变量的方差。方差分析认为:观测变量值的变动会受控制变量和随机变量两方面的影响。据此,单因素方差分析将观测变量总的离差平方和分解为组间离差平方和和组内离差平方和两部分,用数学形式表述为:SST=SSA+SSE。
- 3、通过比较观测变量总离差平方和各部分所占的比例,推断控制变量是否给观测变量带来了显著影响。
- 3、总结:在观测变量总离差平方和中,如果组间所占比例较大,则说明观测变量的变动主要是由控制变量引起的;反之,如果组间所占比例小,则说明观测变量的变动不是主要由控制变量引起的,是由随机变量因素引起的。
1.1.2、基本步骤
- 1、提出原假设:H0: μ 1 \mu_1 μ1= μ 2 \mu_2 μ2=…= μ n \mu_n μn每个水平的均值都相等(即无差异);H1:至少有两个均值不相等(即有显著差异)
- 2、选择检验统计量:方差分析采用的检验统计量是F统计量,即F值检验。
- 3、计算检验统计量的观测值和概率P值:该步骤的目的就是计算检验统计量的观测值和相应的概率P值。
- 4、给定显著性水平,并作出决策
1.1.3、方差齐性检验和多重比较检验
- 在完成上述单因素方差分析的基本分析后,可得到关于控制变量是否对观测变量造成显著影响的结论,但下面还要继续做重要分析:方差齐性检验、多重比较检验。
- 1、方差齐性检验
- 是对控制变量不同水平下各观测变量总体方差是否相等进行检验。
前面提到,控制变量不同水平下观测变量总体方差无显著差异是方差分析的前提要求。如果没有满足这个前提要求,就不能认为各总体分布相同。因此,有必要对方差是否齐性进行检验。 - 若不满足方差齐性检验,解决方法如下:可以对因变量进行取对数处理,很大程度上可以满足齐性检验;增加实验次数也可;即使不能满足,也可以利用方差检验提供一些有用的东西。
- 是对控制变量不同水平下各观测变量总体方差是否相等进行检验。
- 2、多重比较检验
- 单因素方差分析的基本分析只能判断控制变量是否对观测变量产生了显著影响。如果控制变量确实对观测变量产生了显著影响,进一步还应确定控制变量的不同水平对观测变量的影响程度如何,其中哪个水平的作用明显区别于其他水平,哪个水平的作用是不显著的,等等。
例子:如某克山病区测得11例克山病患者和13名健康人的血磷值(mmol/L)如下:(来自百度百科)
患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11
健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87
问该地克山病患者与健康人的血磷值是否不同?
在这个例子中:由于患者和健康人都属于人类,因此因子就是所有人;
再将人分为了两种:患者和健康人,这两种人就是水平。
而各水平下的血磷值就是观测值。
问题研究的是人的血磷值与患没患病有无关系?
从以上资料可以看出,24个患者与健康人的血磷值各不相同,如果用离均差平方和(SS)描述其围绕总均值的变异情况,则总变异有以下两个来源:
- 组内变异,即由于随机误差的原因使得各组内部的血磷值各不相等;
- 组间变异,即由于克山病的影响使得患者与健康人组的血磷值均值大小不等。
- SS总=SS组间+SS组内
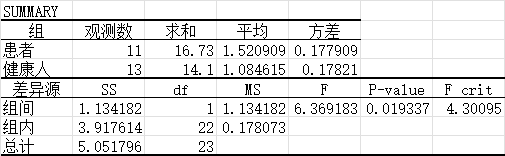
- 通过excel中的单因素方差分析结果可知:
- a、患者和健康人各自总体的方差仅有0.001的误差,可以认为方差相同,满足方差齐性检验,可以做方差分析;
- b、P<0.05,具有统计学意义且拒绝原假设,说明患者和健康人的血磷值均值存在显著差异;组间方差低于组内方差,说明血磷值的不同不是由于是否患病引起的,而是因为随机发生的。
1.2、双因素方差分析
- 多因素方差分析用来研究两个及两个以上控制变量是否对观测变量产生显著影响。多因素方差分析不仅能够分析多个因素对观测变量的独立影响,更能够分析多个控制因素的交互作用能否对观测变量的分布产生显著影响,进而最终找到利于观测变量的最优组合。
- 例子:小学六年级不同班级不同性别的学生成绩。
- 两个因子:不同班级、不同性别;不同班级和不同性别分别对成绩的影响即为单独影响;而班级与性别的交互(如一班女生,三班男生、二班女生即班级和性别产生的组合) 即为对成绩的交互影响;可以研究到底是哪个班的男生或女生的成绩是最好的。
- 例子:小学六年级不同班级不同性别的学生成绩。
例子:现有三个班的学生成绩如图:横向1男生、0女生,纵向1、2、3分别为一班、二班、三班,值为成绩。利用excel方差分析
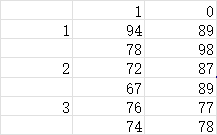

这里的样本为班级,列为性别,交互为班级与性别交互,内部为误差。班级和性别分别对学生成绩的存在显著影响,但班级与性别的交互并未对成绩产生显著影响。
二、python实现方差分析
数据集来自于我们老师的课后作业
背景:数据集展示了已迁离北京的高学历外来人口现在的月收入、教育程度和职业数据。
试分析教育程度和职业对外来人口的收入是否有显著影响以及有怎样的影响

编码如下: 我直接再excel中将其编码了 python里就不展示了
| 职业编码 | 说明 |
|---|---|
| 1 | 领导干部为主的群体 |
| 2 | 办事员和职员为主的群体 |
| 3 | 专业技术人员为主的群体 |
| 4 | 商业人员为主的群体 |
| 教育编码 | 说明 |
|---|---|
| 0 | 本科 专科 |
| 1 | 硕士 博士 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats # 里面有方差齐性检验方差
from statsmodels.formula.api import ols # 最小二乘法拟合
from statsmodels.stats.anova import anova_lm # 方差分析
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('fangcha.csv',sep=',',encoding='gbk')
df['ln_income'] = np.log(df['income']) # 收入取对数 防止方差齐性检验不通过
df.head(2)
education career income ln_income
0 1 3 12000 9.392662
1 1 3 8000 8.987197
# 查看教育程度和职业的箱线图
fig, ax = plt.subplots(1,2,figsize=(12,6)) # 1行2列的子图
ax1 = sns.boxplot(x='education',y='ln_income',data=df,ax=ax[0]) # ax[i] 表示第i个子图
ax1.set_title('教育程度—收入对数箱线图',size=12)
ax2 = sns.boxplot(x='career',y='ln_income',data=df,ax=ax[1])
ax2.set_title('职业—收入对数箱线图',size=12)
plt.show()

- 可以看出:教育程度越高,平均收入也越高;领导干部类职业的平均薪资还是较高于其它行业的;商业人员为主的群体平均工资最低。
# 用Levene方法分别对各因素进行方差齐性检验并解释结果
np.round(stats.levene(df['career'],df['ln_income']),4) # (98.2878, 0.0)
np.round(stats.levene(df['education'],df['ln_income']),4) # (20.659, 0.0)
# P=0.0 因此两个因子不用水平对与收入的总体方差均相等
# 对教育程度和职业进行方差分析,对结果进行解释,分析这两个因素对对数收入是否有显著影响以及有怎样的影响。需要考虑因素的交互作用。
model = ols('ln_income ~career + education + career:education', data = df).fit()
# 或者 model = ols('ln_income ~career*education', data = df).fit()
anova_table = anova_lm(model, type = 2)
pd.DataFrame(anova_table)
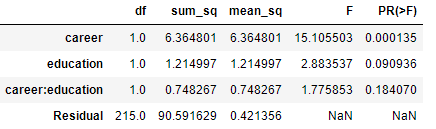
- 从结果可以看出:
- 职业对收入的影响通过5%的显著性水平 ;教育程度通过10%的显著性水平;说明职业和教育程度对个人收入还是存在显著影响的。
- 职业与教育程度的交互项并未通过显著性检验,说明交互项对收入没什么影响。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









