






目录
1.Error: 'Tensor' object has no attribute 'lower'
2.Error: ValueError: The last dimension of the inputs to `Dense` should be defined. Found `None`
一、任务
- 数据为AG_news 新闻数据集标题文本
- word2vec进行词向量训练 并输入卷积模型
- 利用多种卷积核3*64、5*64、7*64来训练
- 最大池化转二维结构
- 将池化结果连接
- 全连接层分类---5类
二、思路
随手画的---后面模型按这个思路 单数换了参数 懒得画了 将就一下
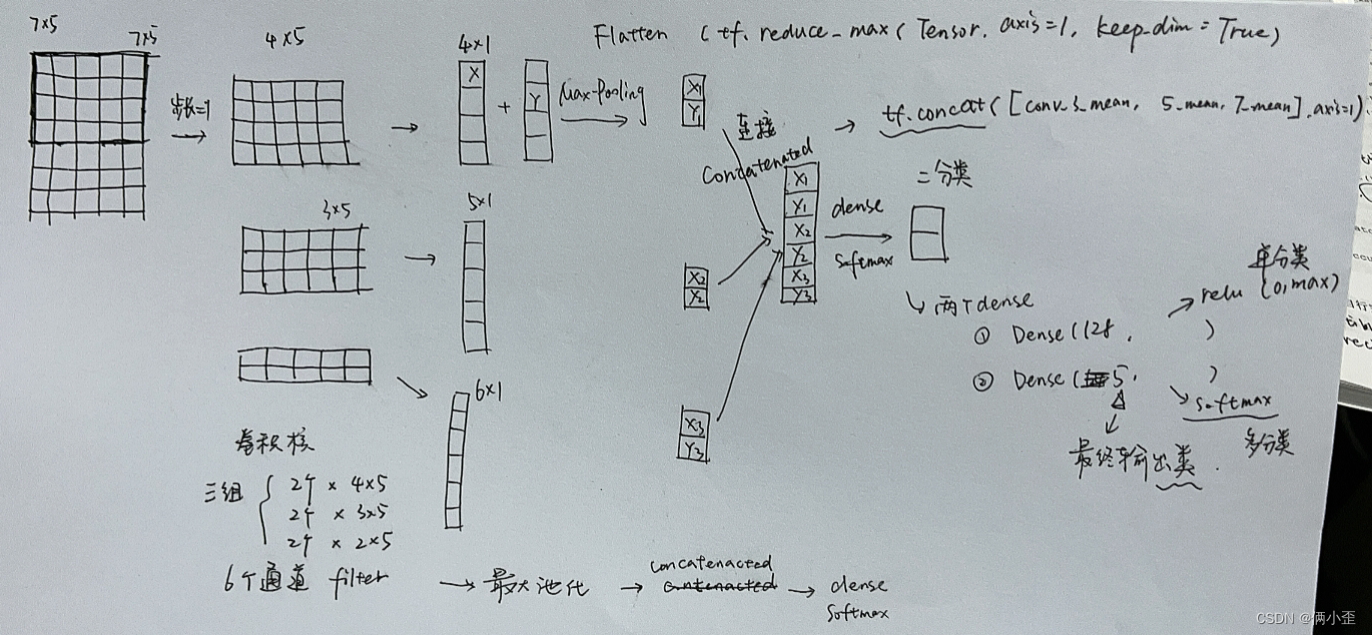
三、数据预处理
- 标题文本清洗
- 标签one-hot
- 标题文本词向量word2vec 向量大小为12 不够补齐 多余截断
"""一、单词文本处理函数"""
#1.文本清理函数(大小写、去除标点、删除多余空格、首尾空格删除、以空格分词
def text_clearTitle_word2vec(text):
text = text.lower() #将文本转化成小写
text = re.sub(r"[^a-z]"," ",text) #替换非标准字符,^是求反操作。
text = re.sub(r" +", " ", text) #替换多重空格
text = text.strip() #取出首尾空格
text = text + " eos" #添加结束符
text = text.split(" ")
return text
#2.将标签转为one-hot格式函数
def get_label_one_hot(list):
values = np.array(list)
# print("values:",values)
n_values = np.max(values) + 1
# print(np.max(values))
return np.eye(n_values)[values]
#3.获取训练集和标签函数
def get_word2vec_dataset(n = 12):
#读取数据并完成预处理
agnews_label = []
agnews_title = []
agnews_train = csv.reader(open("./dataset/train.csv", "r"))
for line in agnews_train:
agnews_label.append(np.int(line[0]))
agnews_title.append(text_clearTitle_word2vec(line[1]))
#建立word2vec模型
model = word2vec.Word2Vec(agnews_title,vector_size=64,min_count=0,window=5)
train_dataset = []
for line in agnews_title:
length = len(line)
if length > n:
line = line[:n]
word2vec_matix = (model.wv[line])
train_dataset.append(word2vec_matix)
else:
word2vec_matix = (model.wv[line])
pad_length = n - length
pad_matrix = np.zeros([pad_length,64])+1e-10
word2vec_matix = np.concatenate([word2vec_matix,pad_matrix],axis=0)
train_dataset.append(word2vec_matix)
train_dataset = np.expand_dims(train_dataset,3)
print(train_dataset.shape)
print(train_dataset.ndim)
label_dataset = get_label_one_hot(agnews_label)
return train_dataset,label_dataset四、建立模型
"""二、创建word2vec模型"""
#word2vec_CNN的模型
def word2vec_CNN():
xs = tf.keras.Input(shape=(12,64,1))
#设置卷积核大小为[3,64]通道为12的卷积计算
conv_3 = tf.keras.layers.Conv2D(12,[3,64],activation=tf.nn.relu)(xs)
#设置卷积核大小为[5,64]通道为12的卷积计算
conv_5 = tf.keras.layers.Conv2D(12,[5,64],activation=tf.nn.relu)(xs)
#设置卷积核大小为[7,64]通道为12的卷积计算
conv_7 = tf.keras.layers.Conv2D(12,[7,64],activation=tf.nn.relu)(xs)
#下面是分别对卷积计算的结果进行池化处理,将池化处理的结果转成二维结构
conv_3_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_3,axis=1,keepdims=True))
conv_5_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_5,axis=1,keepdims=True))
conv_7_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_7,axis=1,keepdims=True))
flatten = tf.concat([conv_3_mean,conv_5_mean,conv_7_mean],axis=1)
fc_1 = tf.keras.layers.Dense(128,activation=tf.nn.relu)(flatten)
logits = tf.keras.layers.Dense(5,activation=tf.nn.softmax)(fc_1)
model = tf.keras.Model(inputs = xs, outputs = logits)
return model
train_dataset,label_dataset = get_word2vec_dataset()
X_train,X_test,y_train,y_test = train_test_split(train_dataset,label_dataset,test_size=0.1,random_state=217)
batch_size = 12
train_data = tf.data.Dataset.from_tensor_slices((X_train,y_train)).batch(batch_size)
model = word2vec_CNN()
model.compile(optimizer = tf.optimizers.Adam(1e-3),loss = tf.losses.categorical_crossentropy,metrics=['accuracy'])
model.fit(train_data,epochs=10)五、模型结果
1.运行结果
score = model.evaluate(X_test,y_test)
print("score:",score)

![]()
2.可视化
history = model.fit(train_data,epochs=10)
history_dict = history.history
train_loss = history_dict["loss"]
train_accuracy = history_dict["accuracy"]
plt.figure()
plt.plot(range(10), train_loss, label='train_loss')
plt.legend()
plt.plot(range(10), train_accuracy, label='train_accuracy')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss & accuracy')
plt.show()
六、报错及处理
1.Error: 'Tensor' object has no attribute 'lower'
1)前后代码:
xs = tf.keras.Input(shape=(12,64,1))
#设置卷积核大小为[3,64]通道为12的卷积计算
conv_3 = tf.keras.layers.Conv2D(12,[3,64],activation=tf.nn.relu)(xs)
#设置卷积核大小为[5,64]通道为12的卷积计算
conv_5 = tf.keras.layers.Conv2D(12,[5,64],activation=tf.nn.relu)(xs)
#设置卷积核大小为[7,64]通道为12的卷积计算
conv_7 = tf.keras.layers.Conv2D(12,[7,64],activation=tf.nn.relu)(xs)
#下面是分别对卷积计算的结果进行池化处理,将池化处理的结果转成二维结构
conv_3_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_3,axis=1,keepdims=True))
conv_5_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_5,axis=1,keepdims=True))
conv_7_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_7,axis=1,keepdims=True))2)报错行:
conv_3_mean = tf.keras.layers.Flatten(tf.reduce_max(conv_3,axis=1,keepdims=True))
3)修改:
参考:python - 'Tensor' object has no attribute 'lower' - Stack Overflow
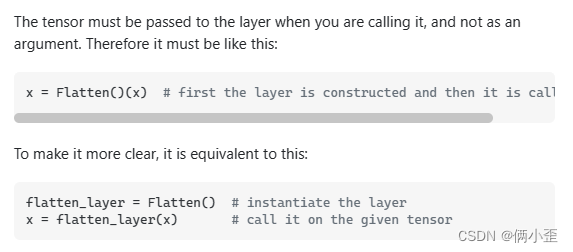
conv_3_mean = tf.keras.layers.Flatten()(tf.reduce_max(conv_3,axis=1,keepdims=True))
2.Error: ValueError: The last dimension of the inputs to `Dense` should be defined. Found `None`
1)问题:Dense层在输入的时候,需要定义shape/size
2)解决:在tf.keras.Input层定义shape---不要用None
# xs = tf.keras.Input([None, None])
xs = tf.keras.Input(shape=(12,64,1))
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









