






目录
官网:models.fasttext – FastText model — gensim (radimrehurek.com)
一、FastText原理和算法
1.fastText作用
1)训练词向量
2)进行文本分类
2.fastText优点
相比于传统的word2vec,fastText的优点
- fastText保持高精度的同时,加快了训练精度和测试精度
- fastText对word embedding的训练更加准确
- fastText采用两个重要算法:N-gram、Hierarchical Softmax
- 使用n-gram的词向量使得Fast-text模型可以很好的解决未登录词(OOV——out-of-vocabulary)的问题
3.N-gram
在word2vec中采取的是CBOW架构,而fastText采用N-gram架构。
N-gram常用的三种:一元(1-gram)、二元(2-gram)、三元(3-gram)
n就是滑动窗口大小 例:“我在成都吃火锅”
1-gram:["我","在","成","都","吃","火","锅"]
2-gram:["我在","在成","成都","都吃","吃火","火锅"]
3-gram:["我在成","在成都","成都吃","都吃火","吃火锅"]
ps:当fastTest用于训练词向量时,n-gram时采取的skip-gram;而且fasttext并没有保存ngram信息,只是hash并用于检索了。
4.Hierarchical Softmax
Hierarchical Softmax(hs)主要是为了减轻计算量。通过哈夫曼树实现,将词向量作为叶子节点,根据词向量建立哈夫曼树。
二、FastText训练词向量
1.从gensim包加载FastText
本实验从gensim包加载FastText:
from gensim.models import FastText2.模型超参数
model = FastText(min_count=5,vector_size=300,window=7,workers=10,epochs=50,seed=17,sg=1,hs=1)- min_count(int,optional):忽略词频小于该值的词
- size(int,optional):word向量的维度
- window(int,optional):一个句子中当前词和被预测单词的最大距离
- workers(int,optional):训练模型时使用的线程数
- sg({0,1},optional):模型的训练算法 1:skip-gram 0:CBOW
- hs({0,1},optional): 1:采用Hierarchical Softmax训练模型 0:使用负采样
3.模型训练词向量
model.build_vocab(jieba_cut_list)
model.train(jieba_cut_list, total_examples=model.corpus_count, epochs=model.epochs)- jieba_cut_list:是已经分词好的句子。例如[ ["我","在","成","都","吃","火","锅"],["我在","在成","成都","都吃","吃火","火锅"]]
4.模型的保存和加载
#保存
model.save("./ceshi_fasttext_model_jieba.model")
#加载
model = FastText.load("./ceshi_fasttext_model_jieba.model")5.词向量的使用
ps:fasttext和word2vec类似 不再赘述
embedding = (model.wv["卷积","神经网络"])
print(embedding)
print(embedding.shape)[[ 0.00227801 -0.00387814 0.00224288 -0.00488548 0.00748316 -0.01994031
0.01059218 -0.00755341 0.00369787 0.00486877 -0.01610742 -0.00284252
-0.00361041 0.01498076 -0.01373026 -0.00912138 0.02075874 0.00217725
0.00075823 -0.01980595 -0.01588477 0.00566112 -0.00869555 -0.01784998
-0.00690811 -0.01436063 -0.00855923 -0.00983512 0.00802138 -0.00407105]
[ 0.00704242 -0.00535574 0.00206528 -0.00332001 0.00821603 0.00378277
0.00374471 -0.00333902 0.0018149 0.00255797 0.0008302 -0.00475089
0.00044787 0.01418014 -0.00519747 0.00257629 0.00276021 -0.0068962
-0.00523948 0.0022739 0.00367826 0.00574936 -0.00668766 0.00037117
-0.00311675 0.0114288 -0.00077431 -0.00180964 -0.00337033 0.00084218]]
(2, 30)
- 只能使用已经训练好的词向量,若想要获取的词不在模型中,则加载报错
三、更新模型语料库
步骤:加载已经训练好的模型-->输入新的语料库model.build_vocab(sentence)-->model.train-->model.save
#更新语料库
from gensim.models import FastText
model = FastText.load("./ceshi_fasttext_model_jieba.model")
model.build_vocab(second_sentences,update=True)
model.train(second_sentences,total_examples=model.corpus_count, epochs=model.epochs)
#调整模型超参数
model.min_count =10
model.save("./ceshi_fasttext_model_jieba.model")ps:second_sentences 就是新的语料库
四、提取FastText模型训练结果
- 训练好的fastText模型可以作为卷积网络的embedding层的输入
vocab_list = Word2VecModel.wv.index_to_key
def get_embedding_model(Word2VecModel):
vocab_list = Word2VecModel.wv.index_to_key
word_index = {" ": 0} # 初始化 `[word : token]` ,后期 tokenize 语料库就是用该词典。
word_vector = {} # 初始化`[word : vector]`字典
# 初始化存储所有向量的大矩阵,留意其中多一位(首行),词向量全为 0,用于 padding补零。
# 行数 为 所有单词数+1 比如 10000+1 ; 列数为 词向量“维度”比如100。
embeddings_matrix = np.zeros((len(vocab_list) + 1, Word2VecModel.vector_size))
## 填充 上述 的字典 和 大矩阵
for i in range(len(vocab_list)):
word = vocab_list[i] # 每个词语
word_index[word] = i + 1 # 词语:序号
word_vector[word] = Word2VecModel.wv[word] # 词语:词向量
embeddings_matrix[i + 1] = Word2VecModel.wv[word] # 词向量矩阵
#这里的 word_vector 不好打印
return word_index, word_vector, embeddings_matrix
# 序号化 文本,tokenizer句子,并返回每个句子所对应的词语索引
# 这个只能对单个字,对词语切词的时候无法处理
def tokenizer(texts, word_index):
token_indexs = []
for word in texts:
new_txt = []
new_txt.append(word_index[word]) # 把句子中的 词语转化为index
token_indexs.append(new_txt)
return token_indexs
if __name__ == "__main__":
## 1 获取gensim的模型
model = gensim.models.word2vec.Word2Vec.load("./xiaohua_fasttext_model_jieba.model")
word_index, word_vector, embeddings_matrix = get_embedding_model(model)
token_indexs = tokenizer(["卷积"],word_index)
print(token_indexs)
#下面就是这个的实现,embedding_table
import tensorflow as tf
embedding_table = tf.keras.layers.Embedding(input_dim=len(embeddings_matrix),output_dim=300,weights=[embeddings_matrix],trainable=False)
char = "卷积"
char_index = word_index[char]
#下面是一个小测试,分别打印对应词嵌入的前5个值
print(model.wv.get_vector(char)[:5])
print((embedding_table(np.array([[char_index]])))[0][0][:5])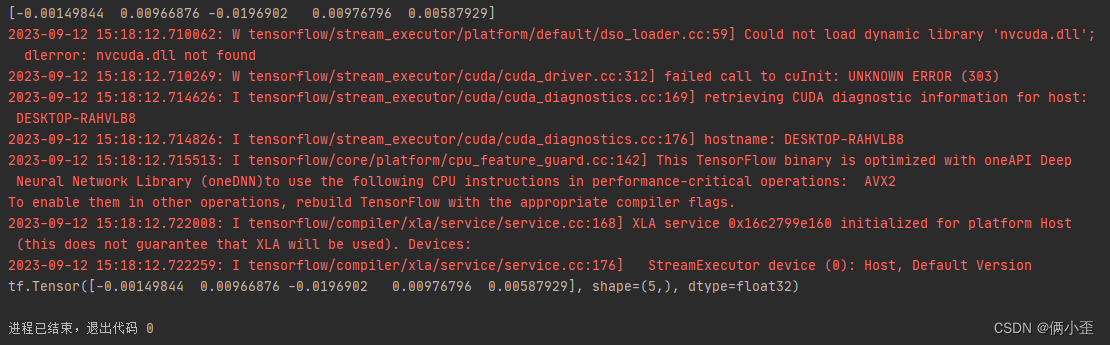















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









