






一、VGG介绍
2014年由牛津大学Visual Geometry Group团队为解决ImageNet中100类图像分类训练的模型。
VGG由5层卷积层、3层全连接层、1层softmax输出层构成,层与层之间使用maxpool(最大化池)分开,所有隐藏层的激活单元都采用ReLU函数。
图片转载地址:手撕 CNN 经典网络之 VGGNet(理论篇) - 知乎 (zhihu.com)

二、VGG特点
1.优点
1)小卷积核
卷积核全部替换为3x3(极少用1x1)
2)小池化核
相比AlexNet的3x3的池化核,VGG全部为2x2的池化核
3)层数更深特征更宽
基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓
4)全连接转卷积
网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
2.缺点
1)耗费更多的计算资源
使用了更多的参数。绝大多数的参数来自于第一个全连接层,并且VGG有三个全连接层。
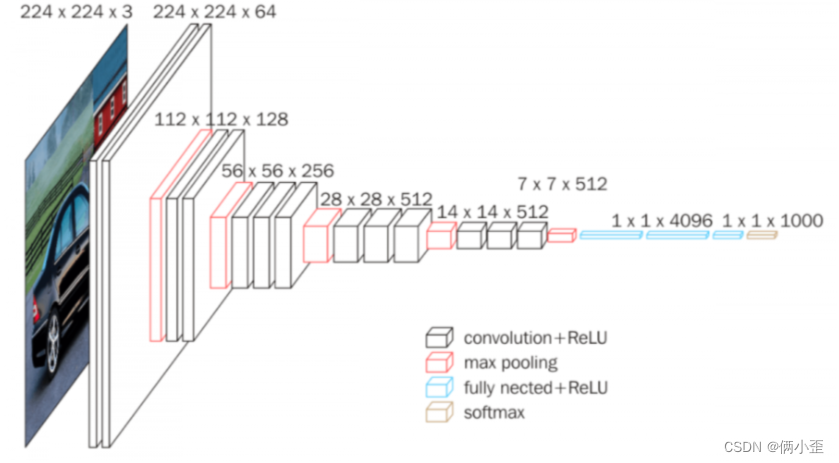
三、VGG模型
这位大神讲的非常清楚,层次结构的推理和计算。
转载自:手撕 CNN 经典网络之 VGGNet(理论篇) - 知乎 (zhihu.com)
四、TensorFlow实现VGG
1.VGG模块
官网指南:tf.keras.applications.vgg16.VGG16 | TensorFlow v2.13.0
tf.keras.applications.vgg16.VGG16
tf.keras.applications.vgg16.VGG16(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax'
)- include_top:是否包含顶层的三个全连接层(顶部的分类层)
- weights:是否加载预训练的参数
- pooling:可选池化模式,用于在include_top=False时进行特征提取。(None\avg\max)
2.数据处理
"""一、单词文本处理函数"""
#1.文本清理函数(大小写、去除标点、删除多余空格、首尾空格删除、以空格分词
def text_clearTitle_word2vec(text):
text = text.lower() #将文本转化成小写
text = re.sub(r"[^a-z]"," ",text) #替换非标准字符,^是求反操作。
text = re.sub(r" +", " ", text) #替换多重空格
text = text.strip() #取出首尾空格
text = text + " eos" #添加结束符
text = text.split(" ")
return text
#2.将标签转为one-hot格式函数
def get_label_one_hot(list):
values = np.array(list)
n_values = np.max(values) + 1
return np.eye(n_values)[values]
#3.获取训练集和标签函数
def get_word2vec_dataset(n = 80):
#读取数据并完成预处理
agnews_label = []
agnews_title = []
agnews_text = []
agnews_train = csv.reader(open("./dataset/train.csv", "r"))
for line in agnews_train:
agnews_label.append(np.int(line[0]))
agnews_text.append(text_clearTitle_word2vec(line[2]))
#建立word2vec模型
model = word2vec.Word2Vec(agnews_text, vector_size=64, min_count=0, window=5)
train_dataset = []
# for line in agnews_title:
for line in agnews_text:
length = len(line)
if length > n:
line = line[:n]
word2vec_matix = (model.wv[line])
train_dataset.append(word2vec_matix)
else:
word2vec_matix = (model.wv[line])
pad_length = n - length
pad_matrix = np.zeros([pad_length,64])+1e-10
word2vec_matix = np.concatenate([word2vec_matix,pad_matrix],axis=0)
train_dataset.append(word2vec_matix)
train_dataset = np.expand_dims(train_dataset,3)
label_dataset = get_label_one_hot(agnews_label)
return train_dataset,label_dataset3.建立模型
train_dataset,label_dataset = get_word2vec_dataset()
X_train,X_test,y_train,y_test = train_test_split(train_dataset,label_dataset,test_size=0.1,random_state=217)
batch_size = 128
train_data = tf.data.Dataset.from_tensor_slices((X_train,y_train)).batch(batch_size)
vgg = tf.keras.applications.VGG16(include_top=False,weights=None)
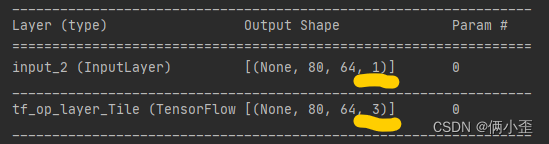
input_xs = tf.keras.Input(shape=(80,64,1))
embedding = tf.tile(input_xs,multiples=[1,1,1,3])
embedding = vgg(embedding)
flatten = tf.keras.layers.Flatten()(embedding)
flatten = tf.keras.layers.Dense(128,activation=tf.nn.relu)(flatten)
output = tf.keras.layers.Dense(5,activation=tf.nn.softmax)(flatten)
model = tf.keras.Model(inputs = input_xs, outputs = output)
print(model.summary())
model.compile(optimizer = tf.optimizers.Adam(1e-3),loss = tf.losses.categorical_crossentropy,metrics=['accuracy'])
model.fit(train_data,epochs=10)Tips:
- 注意vgg模型输入的数据shape要求---(,,3)
- 要先Flatten之后才能Dense

4.模型结果
score = model.evaluate(X_test,y_test)
print("score:",score)
效率很低。。。batch_size=128
训练了半个小时显示第一个epoch还要1h才能训练完。。。

五、报错
1.ValueError: Input 0 of layer block1_conv1 is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: [None, None, None]
1)问题:vgg模型其实是卷积层的堆叠,数据输入要求为三维
2)解决:在Input层时,定义好输入的shape
个人理解,shape的参数 最前面的训练样本量可以省略,后面跟数据集的shape一致---也要符合卷积网络输入的数据要求。
3)数据处理---expand_dim
train_dataset = np.expand_dims(train_dataset,3)
print(train_dataset.shape)
print(train_dataset.ndim)![]()
4)模型输入定义Input的shape
#input_xs = tf.keras.Input([None,None])
input_xs = tf.keras.Input(shape=(80,64,1)) #定义为数据的shape就好
2.ValueError: Input 0 of layer block1_conv1 is incompatible with the layer: expected axis -1 of input shape to have value 3 but received input with shape [None, 12, 64, 1]
input_xs = tf.keras.Input(shape=(80,64,1))
embedding = vgg(embedding)
flatten = tf.keras.layers.Flatten()(embedding)
flatten = tf.keras.layers.Dense(128,activation=tf.nn.relu)(flatten)
output = tf.keras.layers.Dense(5,activation=tf.nn.softmax)(flatten)
model = tf.keras.Model(inputs = input_xs, outputs = output)1)问题
VGG16的预训练模型设置的输入数据axis=-1的那维必须是3 ---- shape=(,,3)

2)解决
embedding = tf.tile(input_xs,multiples=[1,1,1,3])
模型的结构:model.summary()















 5638
5638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









