






1. 背景介绍
在这个大数据时代,各种教育环境中产生了大量的数据,这些数据可以帮助我们运用机器学习技术,从中发现有价值的洞见。学生辍学预测是教育领域中的一个应用领域,机器学习算法可以被应用于预测哪些学生可能会辍学,通过从教育数据中提取有价值的模式和关 键参数。然而,算法的性能取决于我们输入的数据的质量。教育数据通常存在噪声,这会降低机器学习算法的性能,并需要准确的数据预处理。通过使用机器学习技术来预测学生辍学,可以帮助学校和教师及时发现可能会辍学的学生,采取相应的措施,从而降低学生辍学 率,提高教育质量 。
2. 数据集介绍
该数据选自网页https://archive.ics.uci.edu/datasets?skip=10&take=10&sort=desc&orderBy=NumHits&search=中预测学生的辍学和学业成功数据。该数据集含婚姻状况,应用模式,课程,教育水平,国籍,父母教育水平,父母职业,性别,年龄,每学 期的学分,课程评估,失业率,通货膨胀率,国内生产总值等数据,具体数据介绍网页如下https://archive.ics.uci.edu/dataset/697/predict+students+dropout+and+academic+success。
3. 数据处理
在下载的数据集中,可能存在空值,重复数据等情况,在Target列含有辍学,就读,学业成功,3类数据,因此,对数据先进行预处理,将辍学定义为0,就读,学业成功定义为1,代码如下 。
import pandas as pd
data=pd.read_csv('data.csv')
data
print(data.isnull().sum())
# 检查重复数据
print(data.duplicated().sum())
# 删除缺失值行
data.dropna(inplace=True)
# 删除重复数据
data.drop_duplicates(inplace=True)
# 由于数据集中存在就读数据。将就读数据定义为成功
## 定义辍学位0,成功为1
data['Target']=data['Target'].map({'Dropout':0,'Graduate':1,"Enrolled":1})
data运行结果
4. 相关性研究
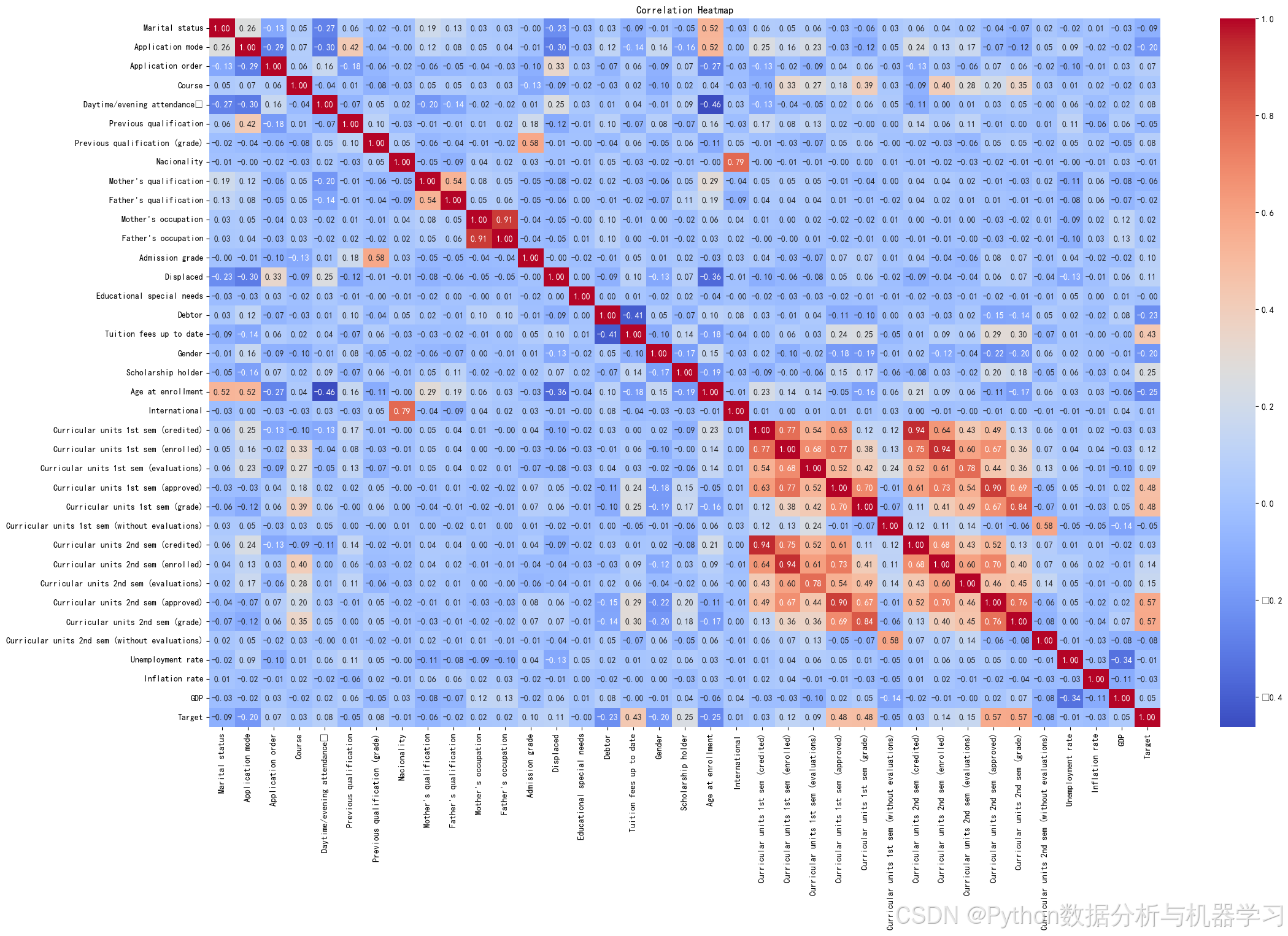
为了了解数据集中各变量之间的相关性,绘制相关性热力图,找出相关性较高的数据,去除相关性较低的数据列,进行数据筛选,提高模型的准确率与模型的表达能力,代码如下 。
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
import warnings
warnings.filterwarnings("ignore",category=UserWarning)
# 设置显示中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams["font.size"]=10
plt.figure(figsize=(25, 15)) # Sets the size of the heatmap
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Heatmap')
plt.show() 运行结果
5. 机器学习模型构建
5.1数据集拆分
对前面数据处理好的数据进行数据拆分,80%为训练集,20%为测试集 。
from sklearn.model_selection import train_test_split
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.2,random_state = 0)
y_test5.2随机森林模型
随机森林是一种监督式学习算法,适用于分类和回归问题。它的核心思路是,当训练数据被输入模型时,随机森林并不是用整个训练数据集建立一个大的决策树,而是采用不同的子集和特征属性建立多个小的决策树,然后将它们合并成一个更强大的模型。通过对多个 决策树的结果进行组合,随机森林可以增强模型的效果 。
from sklearn.ensemble import RandomForestClassifier
import sklearn.metrics as kdddd
from sklearn.metrics import mean_squared_error, r2_score
model1=RandomForestClassifier(n_estimators=30, max_features='sqrt',random_state=10)
model1.fit(X_train, y_train)
y_pred = model1.predict(X_test)
s1=model1.predict(X_test)
s=model1.score(X_test, y_test)
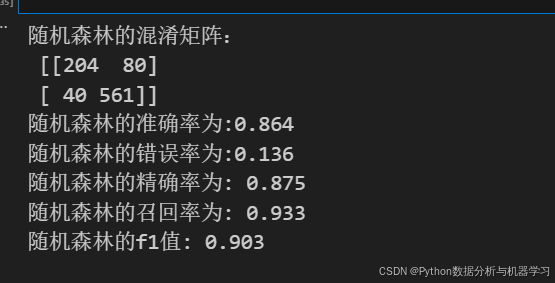
print("随机森林的混淆矩阵:\n",kdddd.confusion_matrix(y_test,s1))
print(f'随机森林的准确率为:{round(s,3)}')
print(f'随机森林的错误率为:{round(1-s,3)}')
print("随机森林的精确率为:",round(kdddd.precision_score(y_test,s1),3))
print('随机森林的召回率为:',round(kdddd.recall_score(y_test,s1),3))
print("随机森林的f1值:",round(kdddd.f1_score(y_test,s1),3))
运行结果
5.3随机森林模型评价
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import RocCurveDisplay
import numpy as np
model1=RandomForestClassifier(n_estimators=30, max_features='sqrt',random_state=10)
model1.fit(X_train, y_train)
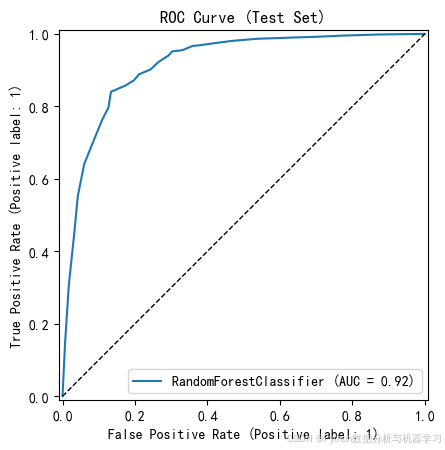
RocCurveDisplay.from_estimator(model1, X_test, y_test)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)
plt.title('ROC Curve (Test Set)')
plt.show()运行结果
5.4 K近邻模型
K近邻模型是一个基本而简单的分类算法,作为监督学习,KNN模型需要的是有标签的训练数据,对于新样本的类别由与新样本距离最近的k个训练样本点按照分类决策规则决定。k近邻法1968年由Cover和Hart提出。它是一种基本的分类与回归方法;是一种基于有标 签训练数据的模型;是一种监督学习算法
from sklearn.neighbors import KNeighborsClassifier
import sklearn.metrics as kdddd
model2 = KNeighborsClassifier(n_neighbors=50)
model2.fit(X_train, y_train)
s=model2.score(X_test, y_test)
s1=model2.predict(X_test)
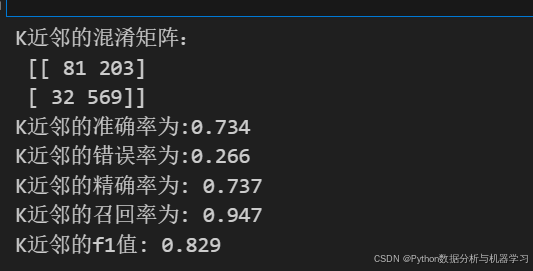
print("K近邻的混淆矩阵:\n",kdddd.confusion_matrix(y_test,s1))
print(f'K近邻的准确率为:{round(s,3)}')
print(f'K近邻的错误率为:{round(1-s,3)}')
print("K近邻的精确率为:",round(kdddd.precision_score(y_test,s1),3))
print('K近邻的召回率为:',round(kdddd.recall_score(y_test,s1),3))
print("K近邻的f1值:",round(kdddd.f1_score(y_test,s1),3))运行结果
5.5 K近邻模型评价
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import RocCurveDisplay
import numpy as np
model2=KNeighborsClassifier(n_neighbors=50)
model2.fit(X_train, y_train)
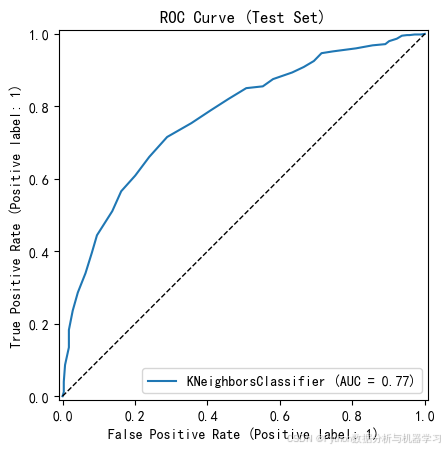
RocCurveDisplay.from_estimator(model2, X_test, y_test)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)
plt.title('ROC Curve (Test Set)')
plt.show()运行结果
5.6逻辑回归模型
逻辑回归(Logistic Regression)是一种广义的线性回归分析模型,主要用于解决二分类问题。它通过给定的训练数据来训练模型,并在训练结束后对测试数据进行分类。逻辑回归模型的核心是使用逻辑函数(Logistic Function)将线性回归的结果映射到0到1之 间,从而表示某个事件发生的概率 。
from sklearn.linear_model import LogisticRegression
model3 = LogisticRegression(C=1e10,max_iter=10000)
model3.fit(X_train, y_train)
s=model3.score(X_test, y_test)
s1=model3.predict(X_test)
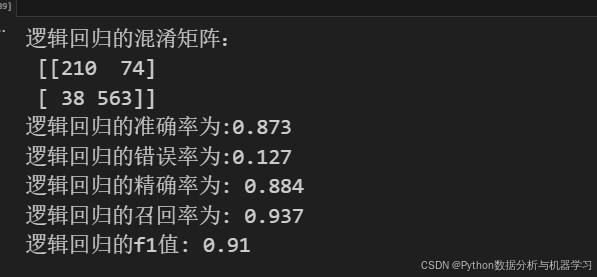
print("逻辑回归的混淆矩阵:\n",kdddd.confusion_matrix(y_test,s1))
print(f'逻辑回归的准确率为:{round(s,3)}')
print(f'逻辑回归的错误率为:{round(1-s,3)}')
print("逻辑回归的精确率为:",round(kdddd.precision_score(y_test,s1),3))
print('逻辑回归的召回率为:',round(kdddd.recall_score(y_test,s1),3))
print("逻辑回归的f1值:",round(kdddd.f1_score(y_test,s1),3))运行结果
5.7逻辑回归模型评价
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import RocCurveDisplay
import numpy as np
model3=LogisticRegression(C=1e10,max_iter=10000)
model3.fit(X_train, y_train)
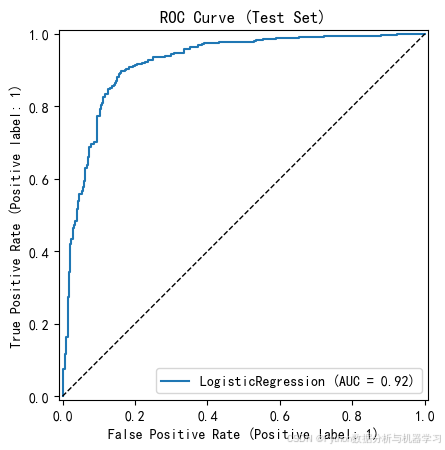
RocCurveDisplay.from_estimator(model3, X_test, y_test)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)
plt.title('ROC Curve (Test Set)')
plt.show()运行结果
5.8决策树模型
决策树(Decision Tree),它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模型,每一条从根结点(对最终分类结果贡献最大的属 性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。
from sklearn.tree import DecisionTreeClassifier
model4 = DecisionTreeClassifier(random_state=77)
model4.fit(X_train, y_train)
s=model4.score(X_test, y_test)
s=model4.score(X_test, y_test)
s1=model4.predict(X_test)
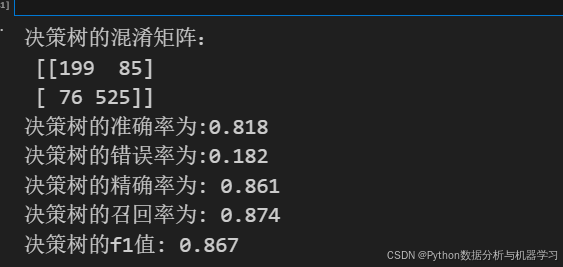
print("决策树的混淆矩阵:\n",kdddd.confusion_matrix(y_test,s1))
print(f'决策树的准确率为:{round(s,3)}')
print(f'决策树的错误率为:{round(1-s,3)}')
print("决策树的精确率为:",round(kdddd.precision_score(y_test,s1),3))
print('决策树的召回率为:',round(kdddd.recall_score(y_test,s1),3))
print("决策树的f1值:",round(kdddd.f1_score(y_test,s1),3))运行结果
5.9决策树模型评价
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import RocCurveDisplay
import numpy as np
model4=DecisionTreeClassifier(random_state=77)
model4.fit(X_train, y_train)
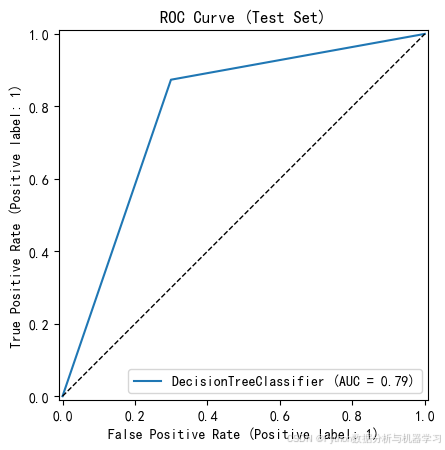
RocCurveDisplay.from_estimator(model4, X_test, y_test)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)
plt.title('ROC Curve (Test Set)')
plt.show()运行结果
6. 总结
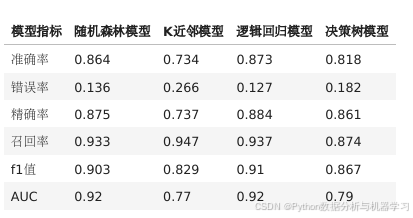
准确率是最直观和常见的机器学习模型评估指标之一。它是指模型正确分类的样本数量与总样本数量之间的比率。在平衡数据集中,准确率是一个很好的评估指标。然而,在不平衡数据集中,准确率可能会因为模型偏向于数量较多的类别而导致误导。因此,在使用准 确率作为评估指标时,我们需要对数据集的平衡性进行考虑。 F1分数是综合考虑精确率和召回率的指标,它是精确率和召回率的调和平均数。F1分数越高,说明模型的性能越好。在实际应用中,我们可以根据具体需求调整精确率和召回率的权重,以获得更符合要求的模 型。 根据上表模型评价表,随机森林模型和逻辑回归模型的效果较好。且准确率较高。
7.参考文献
[1]python机器学习[m],清华大学出版社,2022
[2]python数值计算与模拟,中国青年出版社,2021
[3] Python plotting Matplotlib 2.0.2 documentation[EB/OL]. http:// matplotlib.org/, 2017-05-11/2017/09-15.
[4] 段书勇.Python数据可视化(-)Seaborn介绍. https://www.jians⁃ hu.com/p/5ff47c7d0cc9.
[5] 吴伶琳.Python 语言程序设计基础[M].大连:大连理工大学出 版社,2019:2-5.
[6] 唐永华,刘德山,李玲.Python3 程序设计[M].北京:人民邮电出 版社,2019:3-6.
[7] 李俊杰,谢志明.大数据技术与应用基础项目教程[M].北京:人 民邮电出版社,2017:20-22.
[8] 徐勤亚,蔡继鹏,王星.基于Python的影片数据分析.信息技术与信息 化,2019(08):113-115
[9] 陈俊生,彭莉芬.基于Python+Echarts的大数据可视化系统的设计与实 现.安徽电子信息职业技术学院学报,2019,18(04):6-9.22
[10] 黄琪.基于Python的数据可视化方法和系统实现.信息与电脑(理论 版),2019(14):137-140
[11] 杨凯利,山美娟.基于Python的数据可视化.现代信息科技,2019, 3(05):30-31,34
[12] 段书勇.Python数据可视化(-)Seaborn介绍. https://www.jians⁃ hu.com/p/5ff47c7d0cc9



















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











