






无监督学习输入数据没有被标记,也没有确定的结果,样本数据类别未知,需要根据样本间的相似性对样本集进行分类。
常用的无监督模型主要指各种聚类,主要有K均值聚类、层次聚类、密度聚类等
一,k-means(k-均值算法)
1.算法原理
K-Means算法是一个经典的聚类算法,它接受输入参数k,然后将n个数据对象划分为k个聚类,使所获得的聚类满足以下两个条件。
1)同一聚类中的对象之间的相似度较高。
2)不同聚类中的对象之间的相似度较小。
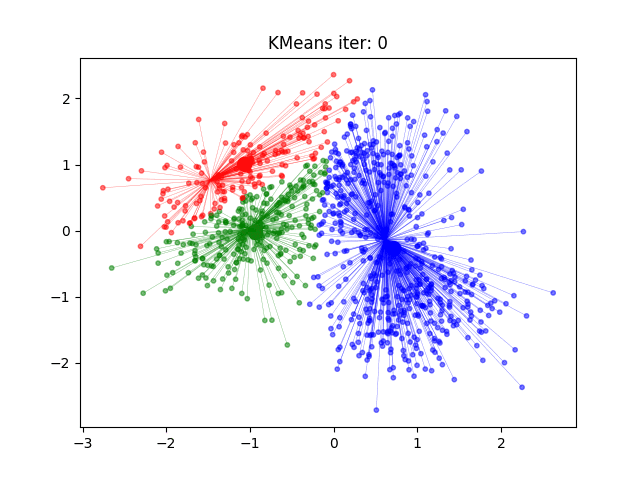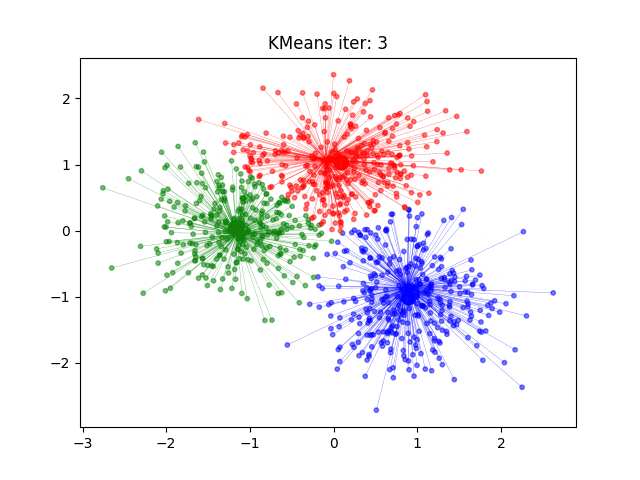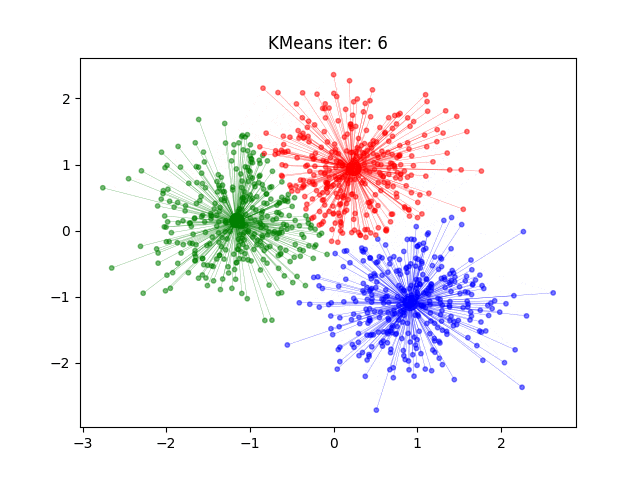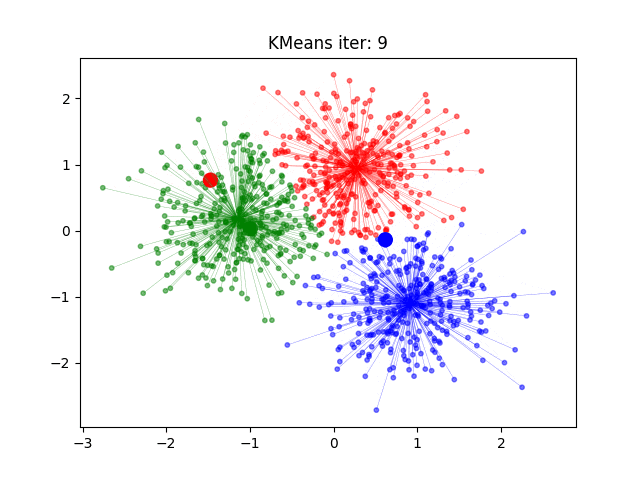
2.算法流程
1)初始化︰随机选择K个数据点作为聚类中心。
2)分类:对于每个数据点,计算它与各个聚类中心的距离,并将它分配给距离最近的聚类中心所代表的类别。
3)更新:对于每个类别,重新计算该类别所有数据点的中心位置(即平均值),作为新的聚类中
4)重复:重复步骤2和3,直到聚类中心不再变化或达到预设的最大迭代次数
5)输出:输出K个聚类中心和每个数据点所属的类别
from sklearn.cluster import KMeans
k = 5
kmeans = KMeans(n_clusters = k,random_state=42)
y_pred = kmeans.fit_predict(X)
3.算法缺点
1)k值难确定
因为没有标签,所以无法确定分成多少组合适,所以一般需要多次尝试)
2)复杂度与样本呈线性相关
因为每个样本都需要与每次的聚类中心计算距离,所以样本量增加会导致计算复杂度增加)
3)不适合任意分布的样本集合
2.DBSCAN算法
1.算法原理
DBSCAN 算法是一种密度聚类算法它基于一组“邻域”参数,来刻画 样本分布的“紧密程度”

2.算法流程
1)随机选择一个“核心对象”作为“种子”
2)人为给定基本参数
3)由“种子”出发,找到所有的“密度可达”对象,生成簇
4)删除已经“成簇”的样本,从剩下的样本随机挑选新的“核心对象”
5)迭代上述过程,直至所有样本都“成簇”
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps = 0.05,min_samples=5)
dbscan.fit(X)
3.算法特点
聚类速度快。能够发现任意形状的空间聚类。不像基于距离的聚类方法,如k-means聚类的结果倾向于球状。能够有效地处理噪声点,对噪声数据不敏感。DBSCAN是基于密度,而噪声点往往是少数的异常点,因而是稀疏的。所以在聚类过程中会自然地被排除在簇之外。而对于基于距离的聚类方法,噪声点很容易影响聚类的中心和分布,从而得到不理想的聚类效果。与k-means比起来,不需要划分的聚类个数。
但是当数据量增大时,要求较大的内存支持,且I/O消耗也很大。当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
3.层次聚类算法
1.算法原理
层次聚类是聚类算法中的一种,通过计算不同类别的相似度组成新的类创建一个层次的嵌套的树
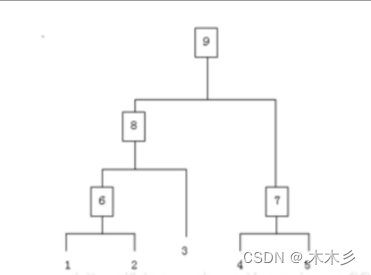
2.算法流程
步骤一:(初始化)将每个样本都视为一个聚类;
步骤二:计算各个聚类之间的相似度;
步骤三:寻找最近的两个聚类,将他们归为一类;
步骤四:重复步骤二,步骤三;直到所有样本归为一类
整个过程就是建立一棵树,在建立的过程中,可以在步骤四设置所需分类的类别个数,作为迭代的终止条件,毕竟都归为一类并不实际。
class sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity='euclidean', compute_full_tree='auto', linkage='ward', distance_threshold=None, compute_distances=False)
3.算法特点
(1)优点:
一次性得到聚类树,后期再分类无需重新计算;
相似度规则容易定义;
可以发现类别的层次关系。
(2)缺点:
计算复杂度高,不适合数据量大的;
算法很可能形成链状。
4.PCA(主成分分析法)
1.算法原理
PCA(主成分分析)是一种数据降维的方法,即用较少特征地数据表达较多特征地数据(数据压缩,PCA属于有损压缩)
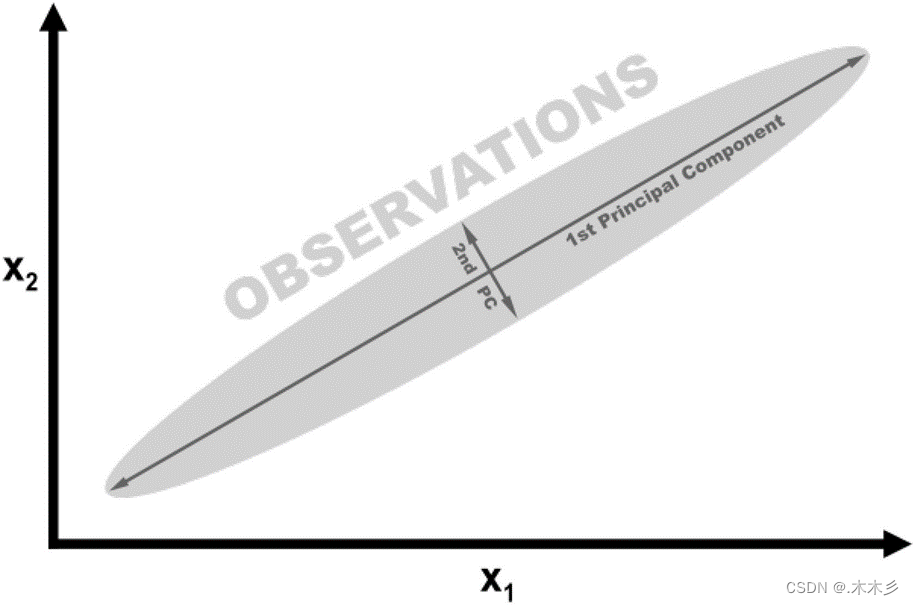
2.算法步骤
1)对数据进行归一化处理;
2)计算归一化后的数据集的协方差矩阵;
3)计算协方差矩阵的特征值和特征向量;
4)保留最重要的k个特征(通常k要小于n);
5)找出k个特征值相应的特征向量
6)将m * n的数据集乘以k个n维的特征向量的特征向量(n * k),得到最后降维的数据。
from sklearn.decomposition import PCA
pca1=PCA(n_components=2)#降到2维
pca1.fit(x_train)
3.算法特点
(1)优点
使得数据集更易使用;
降低算法的计算开销;
去除噪声;
完全无参数限制。
(2)缺点
如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高;















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









