






开启这个系列的笔记主要用于记录个人的学习内容和路程,更好地激励自己在BIGDATA这一块发展前行。该笔记主要记录两个模块:1.在业务上所学习或者生产的知识;2.个人学习所想要记录的内容。不求技术牛逼plus,只求坚持不懈地学习。
一、Work Summary
今日熟悉数据库中大概20-30张表,并进行划分,做成自己的数据表关系图,但是呢,速度还是比较慢,明天后天努努力,争取本周把数据库中的表浏览完。
二、Individual learning
近期计划主要学习MaxCompute,同时学习Spark为辅。方式以官方技术文档为主,以个人购买图书为辅。今日值得记录的内容有:
1.MaxCompute在多个静态分区插入时,不会自动分区,而是后面值覆盖前面的值,因此要分开插入。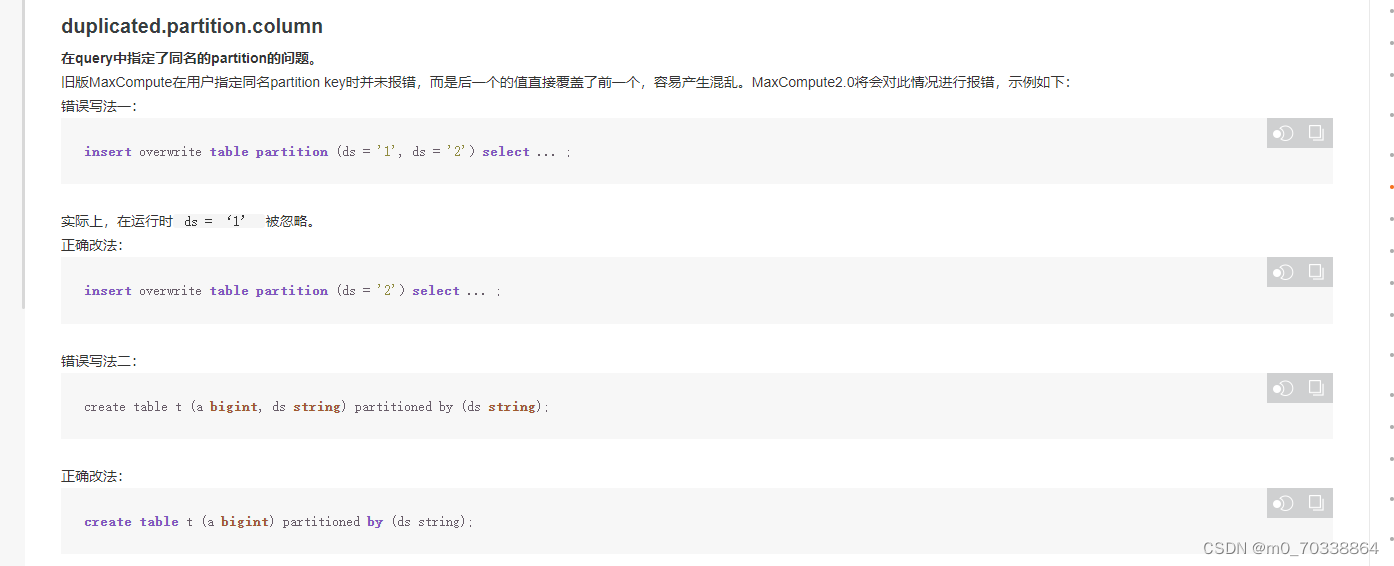
2.Maxcompute2.0的量化操作会导致不及时发送心跳而导致超时,可以手动调节参数或者记录处理时间,优化性能。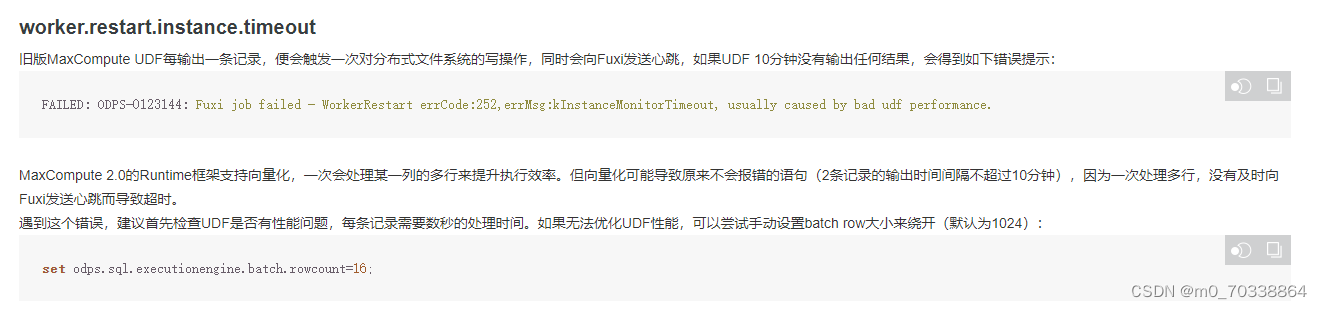 3.关于Multi-way Join和Map Join Hint的优化,该内容在当前阶段只讲了MC1.0和MC2.0的区别,具体使用方法和效果并未讲清楚,具体的使用方法可以在后续中学习。
3.关于Multi-way Join和Map Join Hint的优化,该内容在当前阶段只讲了MC1.0和MC2.0的区别,具体使用方法和效果并未讲清楚,具体的使用方法可以在后续中学习。
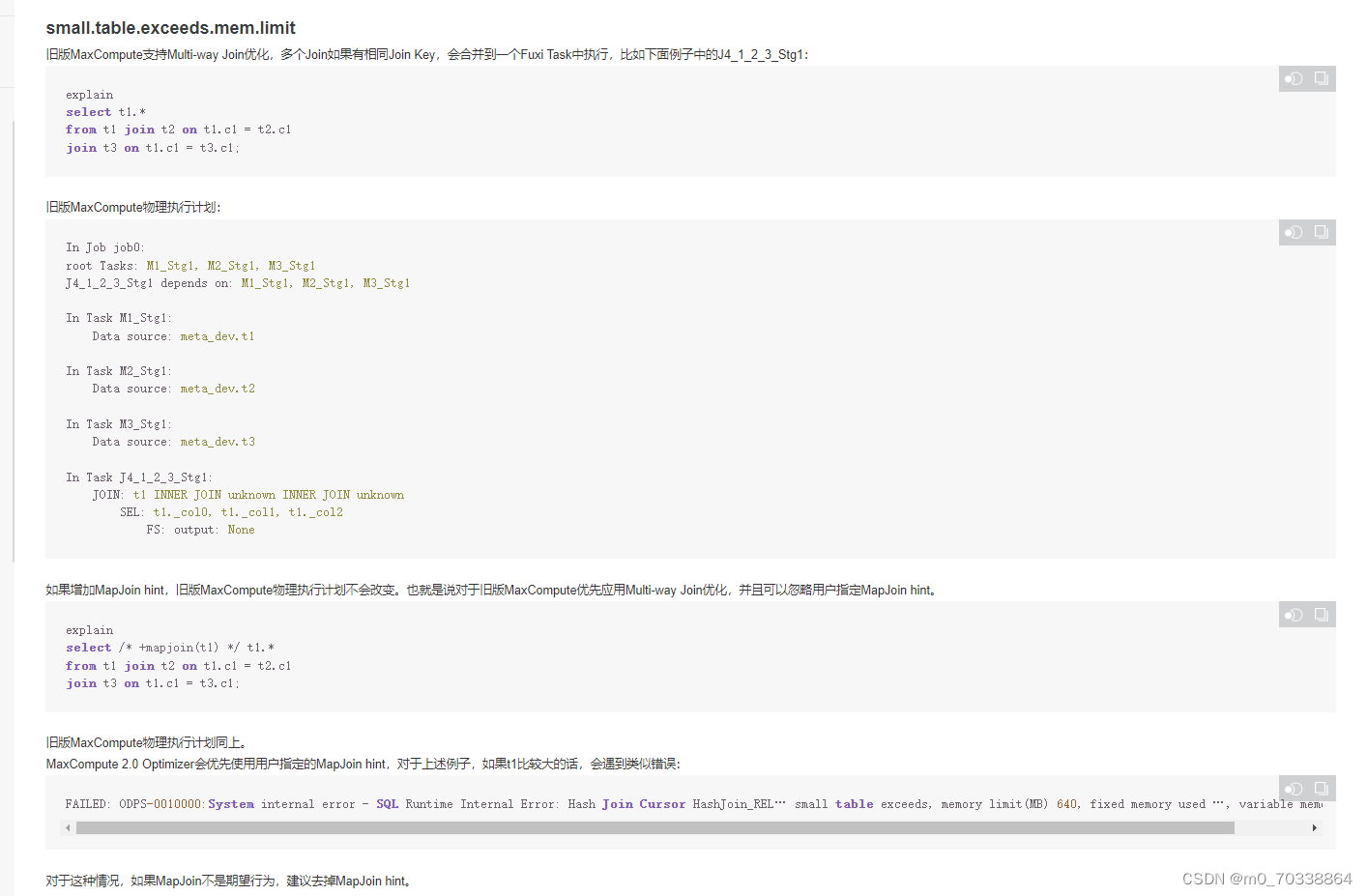
4.MC2.0关于NULL值的判断采用标准的行为进行处理。内容如下: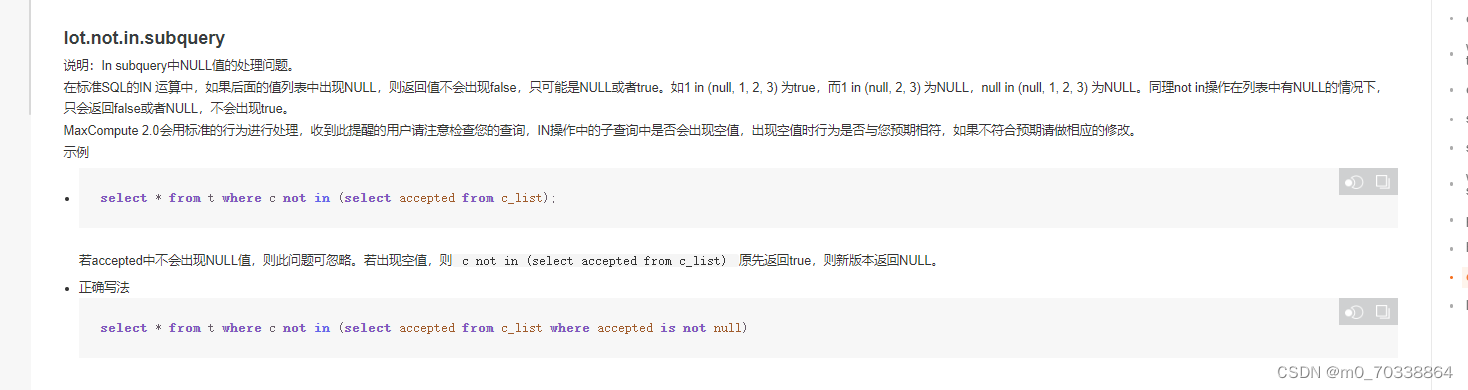
5.wm_concat()在MC2.0中第一个参数必须为常量。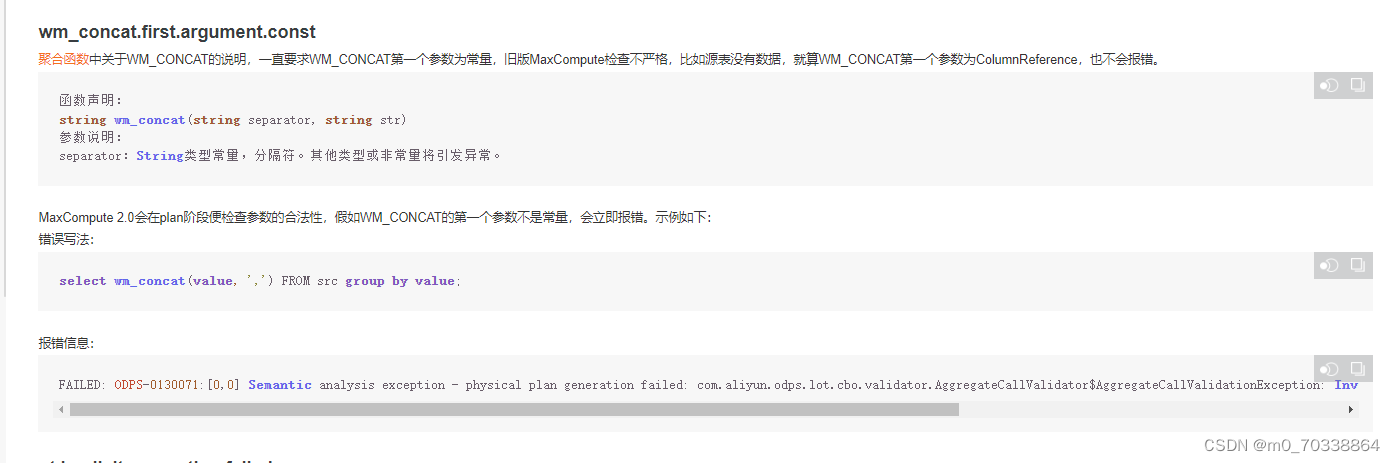
6.错误的escape序列问题
该问题还未搞懂,今日事情今日毕,晚上回家了搞懂它。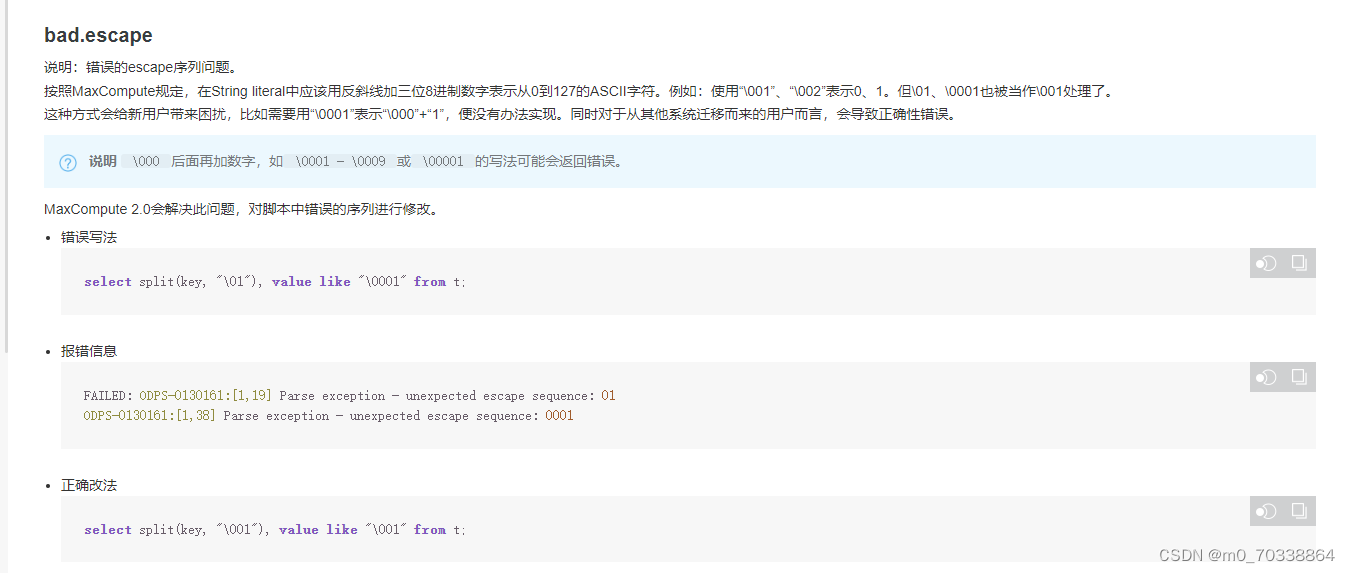
7.目前阶段,MC开启MAP JOIN似乎仍然需要手动开启。
SELECT /*+ MapJoin(a) */ e.empno
, e.ename
, e.sal
FROM emp e
JOIN (
SELECT MAX(sal) AS sal
FROM `emp`
WHERE `ENAME` = 'SMITH'
) a
ON e.sal > a.sal;
-- Hive0.11之前,必须使用MAPJOIN(/*+ MapJoin(small_talbe_name) */)来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小,在MaxCompute中仍然要用。
-- Hive0.11之后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin.可以通过以下两个属性来设置该优化的触发时机
-- set hive.auto.convert.join=true;该参数默认为true,即默认打开MapJoin优化
-- set hive.mapjoin.smalltable.filesize=25000000;
There is no royal road to size, there is no end to learning work boat.
欢迎各位朋友指导、交流、评论!















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









