







 文章深入研究了量化RepVGG时性能下降的原因,并提出QARepVGG,一个量化友好的替代架构,减少了INT8和FP32精度之间的差距,适用于实际部署。实验显示QARepVGG在ImageNet和YOLOv6上的量化性能出色,证明了其泛化能力和对量化误差的鲁棒性。
文章深入研究了量化RepVGG时性能下降的原因,并提出QARepVGG,一个量化友好的替代架构,减少了INT8和FP32精度之间的差距,适用于实际部署。实验显示QARepVGG在ImageNet和YOLOv6上的量化性能出色,证明了其泛化能力和对量化误差的鲁棒性。
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文,并对相应的SCI期刊进行介绍,帮助大家解答疑惑,助力科研论文投稿。解读的系列文章,本人会进行 创新点代码复现,有需要的朋友可关注私信我获取。

一、摘要
性能和推理速度之间的折衷对于实际应用是至关重要的。结构重新参数化获得了更好的折衷,并且它正在成为现代卷积神经网络中越来越受欢迎的成分。尽管如此,当需要INT 8推断时,其量化性能通常太差而无法部署(例如,ImageNet上的top-1精度下降超过20%)。在本文中,我们深入研究了这种失效的潜在机制,即原始设计不可避免地增大了量化误差。我们提出了一个简单、健壮、有效的补救措施,以获得一个量化友好的结构,同时也享有重新参数化的好处。我们的方法极大地弥补了RepVGG的INT 8和FP 32精度之间差距。在没有花里胡哨的情况下,通过标准的训练后量化,ImageNet上排名前1的精度下降减少到2%以内。
二、网络模型及核心创新点
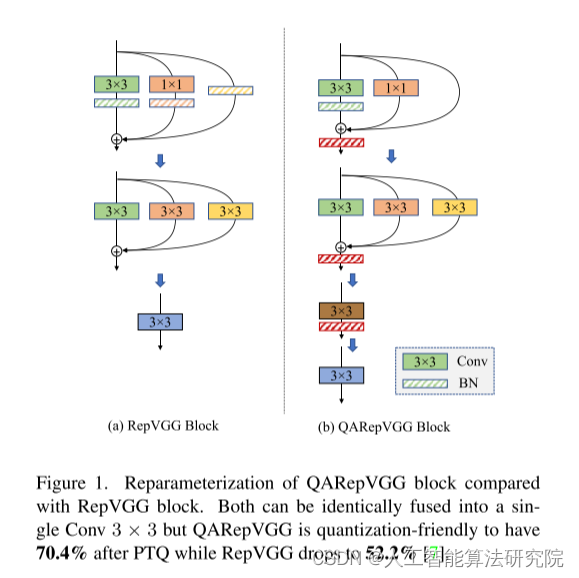
揭示了在量化RepVGG 等基于重新参数化的架构时性能崩溃的根本原因。
设计了RepVGG的量化友好替代品(即QARepVGG),其在权重和激活分布方面具有根本差异,同时保留了速度和性能权衡突出的优势。
我们提出的方法在不同的模型尺度和不同的视觉任务上都有很好的泛化能力,实现了出色的后量化性能,可以随时部署。此外,我们的模型在FP32精度方面与RepVGG相当。
三、实验效果(部分展示)
我们的实验主要集中在ImageNet数据集上。最后,基于最近流行的检测器YOLOv6 验证了该方法的通用性,该检测器广泛采用了重新参数化设计。
1.所有模型均经过120个时期的训练,全球批量为256。我们使用的SGD优化器动量为0.9,权重衰减为10−4。学习速率初始化为0.1,然后按照余弦策略衰减到零。我们还遵循简单的数据扩充,如[11]。所有实验均在8个Tesla-V100 GPU上完成。
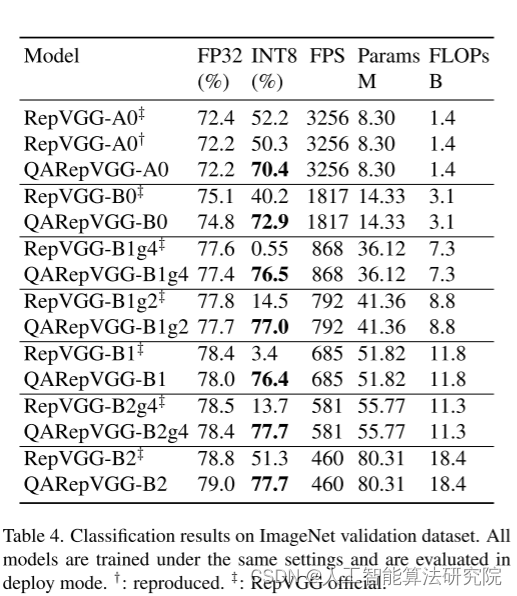
我们观察到具有群卷积的RepVGG的表现要差得多。PTQ后RepVGG-B2 g4的准确度从78.5%下降至13.7%(64.8%↓)。然而,我们的QARepVGG-B2 g4仅损失0.7%的准确度,表明其对其他规模和变体的稳健性。
2.消融研究-变体架构设计。我们研究了不同设计的量化性能,结果如表5所示。
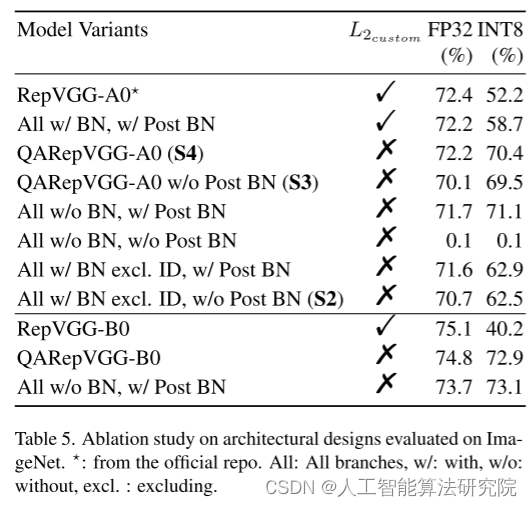
注意,当BN被完全移除时,模型不能收敛。虽然BN后的设置只有71.1%的INT8 top-1精度,但其FP32精度较低。量化间隙随着模型容量的增长(从A0到B0)而增大,这不赞成这种方法。
五、实验结论
通过理论和定量分析,我们剖析了著名的基于重参数化的结构RepVGG的量子化失败.它的结构缺陷不可避免地放大了量化误差,并且累积地产生较差的结果。我们重新设计了QARepVGG,它可以生成有利于量化的权重和激活分布。QARepVGG大大简化了最终部署的量化过程。强调建筑设计中的量化意识应引起重视。
注:论文原文出自 Make RepVGG Greater Again: A Quantization-aware Approach本文仅用于学术分享,如有侵权,请联系后台作删文处理。
解读的系列文章,本人已进行创新点代码复现,有需要的朋友欢迎关注私信我获取 ❤ 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











