







一、向量化表示的核心概念
1.1 特征空间与向量表示
- 多维特征表示:通过多个特征维度(如体型、毛发长度、鼻子长短等)描述对象,每个对象对应高维空间中的一个坐标点,来表示狗这个对象,这样可以区分出不同种类的狗狗;如果有些种类难以区分,还可以继续扩充向量的维度。世界万物都可以用这种方法表达。
- 向量特性:
- 相似对象在特征空间中距离更近
- 支持向量运算(如:警察-小偷 ≈ 猫-老鼠)
- 典型应用场景:
- 以图搜图(图片向量化)
- 视频推荐(视频向量化)
- 商品推荐(商品向量化)
- 智能问答(文本向量化)

1.2 向量数据库特点
| 特性 | 传统数据库 | 向量数据库 |
|---|---|---|
| 存储结构 | 数据表 | 向量集合 |
| 查询方式 | 精确匹配 | 相似度搜索 |
| 查询结果 | 确定值 | 近似最近邻 |
二、最近邻问题(Nearest Neighbors)
2.1 暴力搜索(Flat Search)
- 原理:线性扫描所有向量,计算与查询向量的相似度
- 相似度度量:
- 余弦相似度(向量夹角)
- 欧氏距离(向量间距)
- 优缺点:
- ✅ 100%准确率
- ❌ O(n)时间复杂度
- 暴力算法:优点是搜索质量是完美的,缺点是耗时;如果数据集小,搜索时间可以接受,那可以用。
- 优化思路:**缩小搜索范围**,比如用【***聚类算法***】(比如k-means),【***哈希算法***】(位置敏感哈希)等,但不能不能保证是最近邻的(除了暴搜能保证,其他都不能保证)
2.2 近似最近邻搜索(ANN)(Approximate Nearest Neighbors)-提速度
2.2.1 基于聚类的方法(以K-Means为例)
- 随机生成四个点,作为初始的聚类中心点,然后根据与中心点距离的远近进行分类;
- 计算已有分类的平均点,该平均点作为中心点继续分类,然后不断重复,趋于收敛
# K-Means伪代码
1. 随机初始化k个中心点
2. while not converged:
a. 将每个向量分配到最近的中心点
b. 重新计算每个簇的中心点(均值)
3. 搜索时只需查询最近簇内的向量
- 优化技巧:
- 增加聚类数量(降低速度)
- 查询多个最近簇(降低速度)
- 权衡:搜索质量 vs 搜索速度
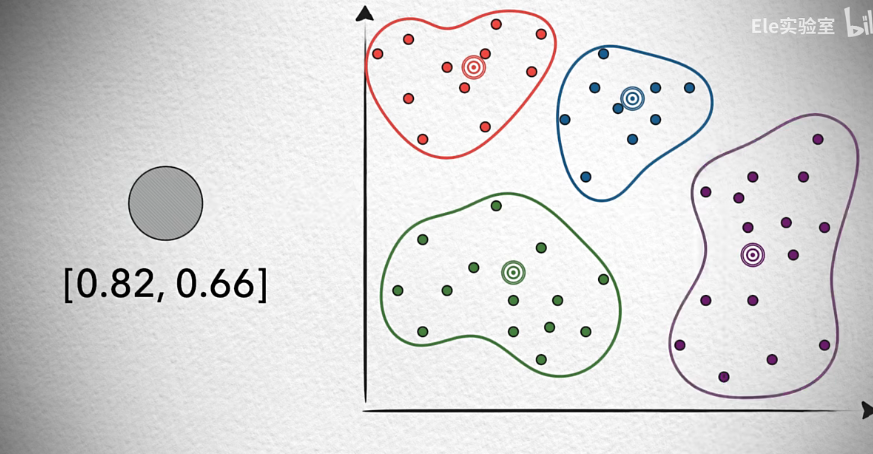
2.2.2 位置敏感哈希(LSH)(Locality Sensitive Hashing)
核心特性:
- 高碰撞概率设计
- 相似向量更可能哈希到同桶
- 哈希碰撞:由于输入是固定长度的数据,而输出是固定长度的哈希值,根据鸽巢原理,必然会出现数据不同而哈希值相同的情况,这叫碰撞。
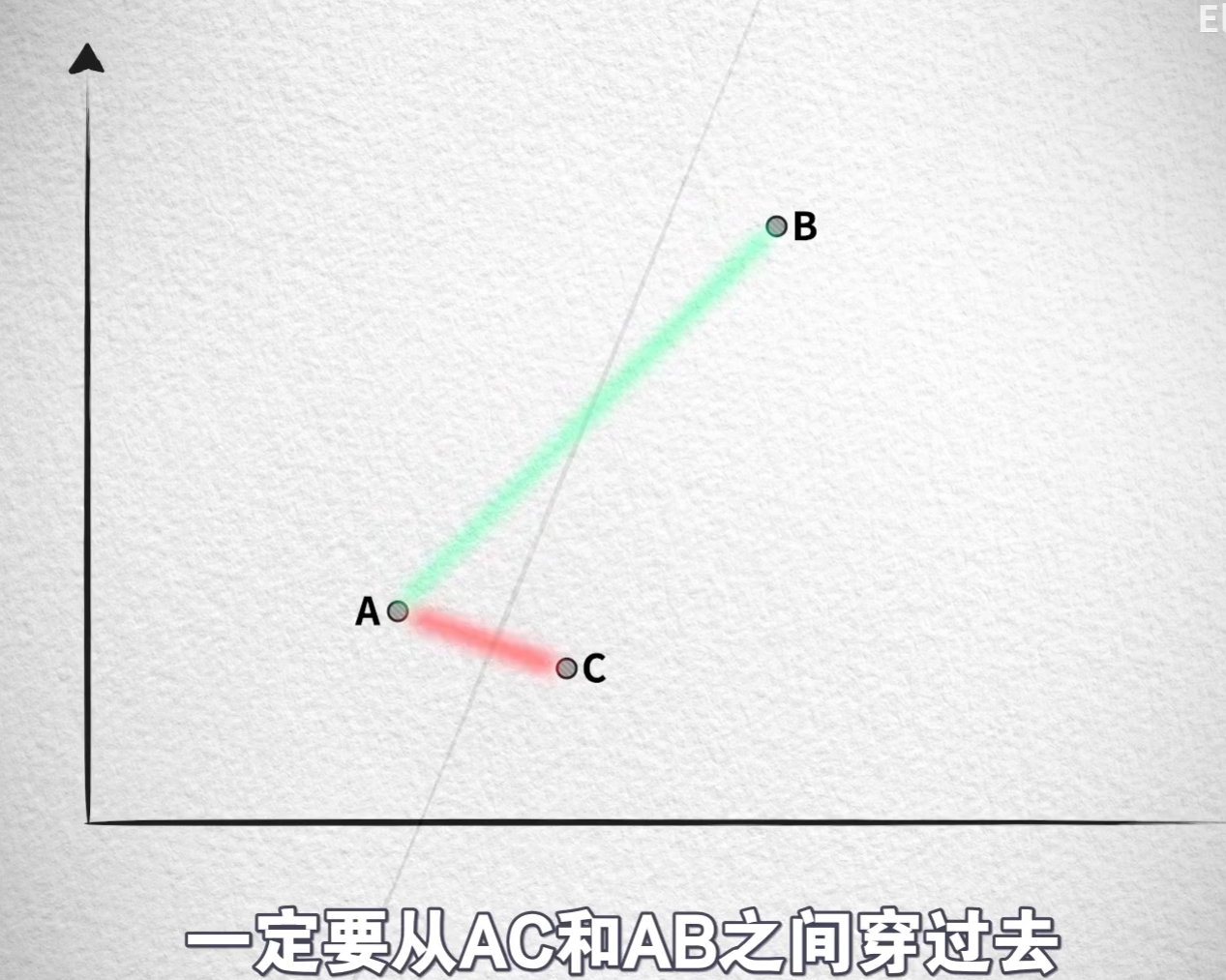
- 正常而言,哈希算法要尽可能减少碰撞的发生,而(对向量)位置敏感哈希函数-LSH则相反,尽可能让位置相近的数据发生碰撞,然后根据哈希碰撞来进行分组,构建方法:随机划出直线分割平面,两面的点分别增加意味0或1来表示
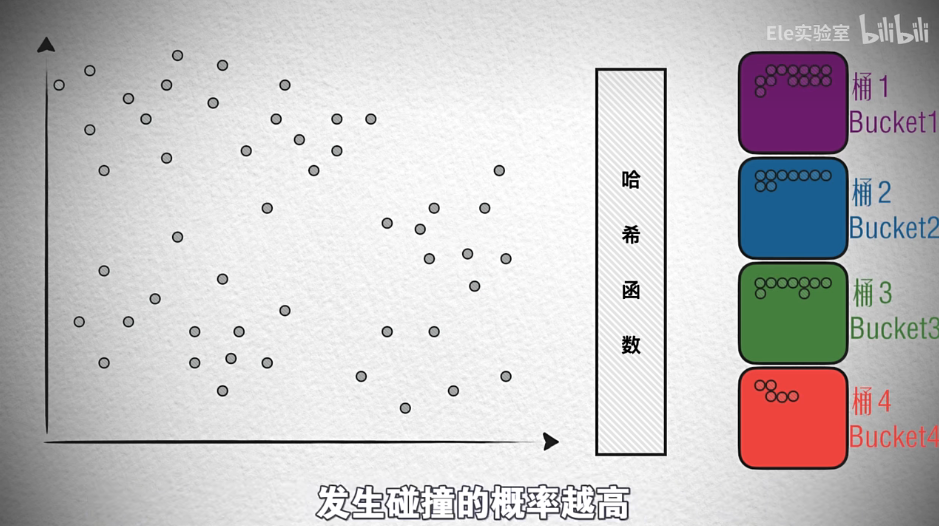
随机超平面哈希实现(随机投影):
- 在d维空间中随机生成超平面
- 根据向量在超平面哪侧生成bit(1/0)
- 组合多个超平面结果生成二进制哈希码
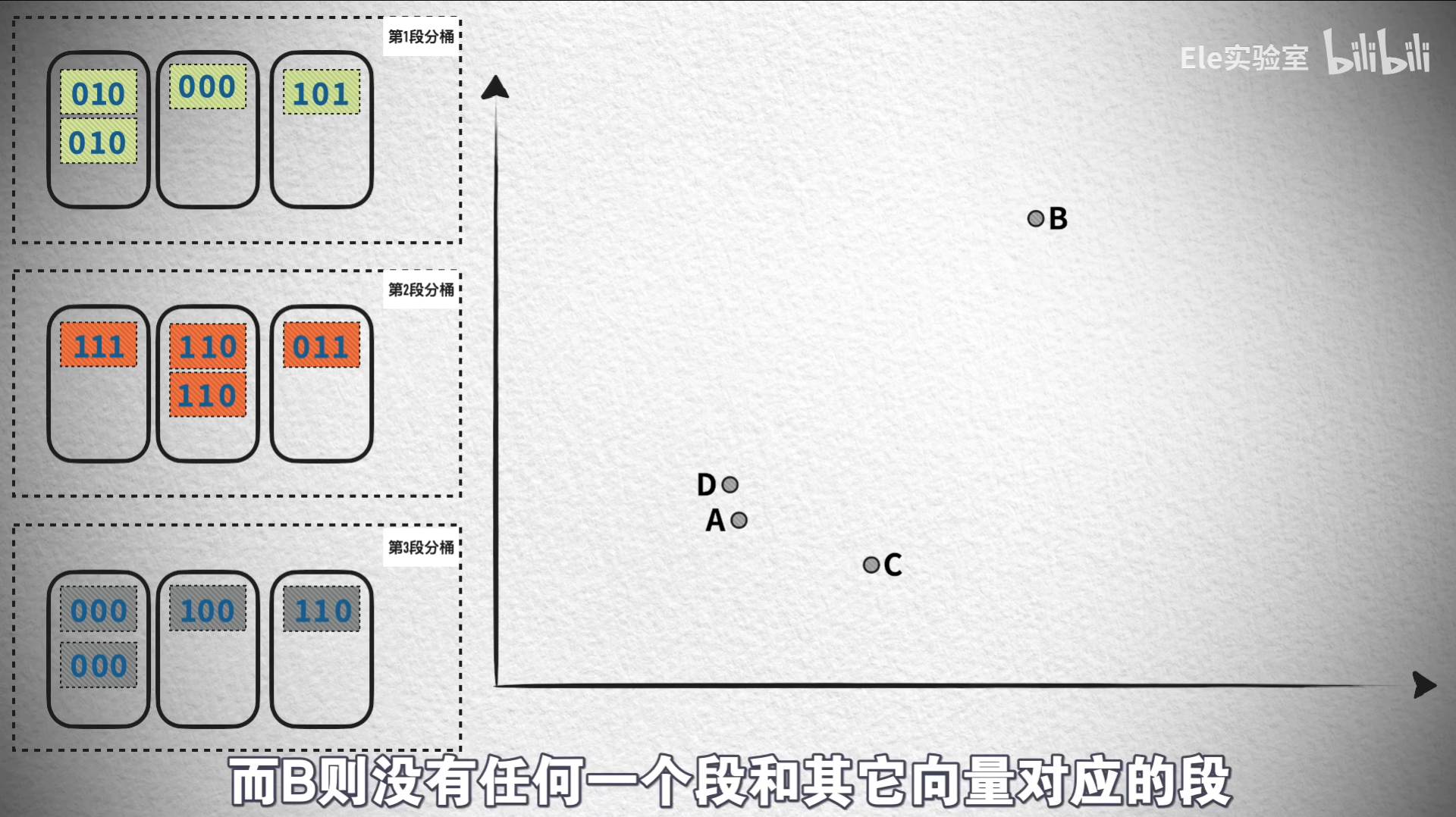
分段优化策略:合理地扩充
- 将哈希码分成m段
- 只要任意一段匹配即作为候选
- 显著提高召回率
积量化(Product Quantization)-省内存
问题:除了搜索速度,还有内存开销问题
方法——量化(Quantization):降低向量本身大小,但产生码本
聚类算法训练——有损压缩(图片中每个像素点都被其所在分类质心点所替代)——在一定程度保留原始信息——给质心编码,只需存储单个编码值,减少空间(把向量用质心编码表示就是量化)——码本

存在问题——维度灾难:
维度增加(数据稀疏)——需要非常大的聚类数——维度灾难——码本指数级膨胀,超过了量化节约出来的内存,得不偿失
进一步解决:高维分成低维(128->16–子空间需要的聚类数量小2^8)——拼接子向量——笛卡尔积——积量化PQ(Product Quantization)


NSW (Navigable Small World) - 牺牲内存,换取速度和质量
6人理论小世界——导航小世界nsw

需要手动建立图结构
保证以下性质:

需要这个:德劳内三角剖分法

但是这个建立的图结构搜索时候不一定很快速,所以nsw方法如下,
在随机足够放回向量的初始阶段向量点非常的稀疏,很容易在距离较远的点之间建立连接,通过长链接快速导航,再通过短链接精细化搜索
这就是NSW算法的大致工作原理,短连接满足了德劳内三角,长链接帮助快速导航,妙在先粗快,后细慢

HNSW(Hierarchical NSW):分层的导航小世界
搜索时候从最上层进入,快速导航,逐步进入下一层,比 NSW 更可控稳定。缺点就是占用内存太大

三、关键技术对比
| 方法 | 预处理成本 | 查询速度 | 内存消耗 | 准确性 | 补充说明 |
|---|---|---|---|---|---|
| 暴力搜索 | 无 | 慢 | 低 | 100% | 线性扫描所有向量,保证结果完全准确,但时间复杂度高(O(n)),仅适用于小规模数据集。 |
| K-Means聚类 | 高 | 快 | 中 | 80-95% | 通过聚类缩小搜索范围,牺牲少量精度换取速度。增加聚类数量可提高准确性,但会降低查询速度。 |
| LSH | 中 | 最快 | 高 | 70-90% | 基于哈希碰撞的近似搜索,适合高维数据。分段策略可提高召回率,但内存开销较大。 |
| NSW | 中 | 快 | 中 | 85-98% | 基于图结构的导航小世界,通过长链接快速导航、短链接精细化搜索。预处理成本低于HNSW,但稳定性稍差。 |
| HNSW | 高 | 最快 | 高 | 90-99% | 分层NSW,搜索时从顶层快速导航到底层,精度接近暴力搜索,但内存占用高,适合大规模实时场景和高维向量场景:既解决了高维数据的稀疏性问题,又避免了传统方法因维度增长导致的性能崩塌,成为高维向量搜索的黄金标准 |
| PQ(积量化) | 高 | 中 | 低 | 75-90% | 通过子空间量化和笛卡尔积压缩向量,显著节省内存,但需权衡精度损失。适合内存受限的部署场景。 |
关键总结
- 速度优先级:LSH ≈ HNSW > NSW > K-Means > PQ > 暴力搜索
- 内存优先级:PQ < 暴力搜索 < NSW < K-Means < HNSW < LSH
- 精度优先级:暴力搜索 > HNSW > NSW > K-Means > PQ > LSH
适用场景建议
- 实时推荐/搜索:HNSW(高精度+高速)
- 内存敏感型应用:PQ(如移动端、嵌入式设备)
- 中等规模数据:NSW(平衡速度与内存)
- 高维数据快速过滤:LSH(如去重、粗筛)
- 小数据集或验证场景:暴力搜索(确保100%准确率)
四、典型应用场景
-
大语言模型:
- 对话历史向量化存储
- 实现"记忆检索"功能
-
推荐系统:
- 用户/商品联合向量空间
- 实时相似推荐
-
多媒体检索:
- 跨模态向量搜索(图→文,文→视频)
以上是整理的笔记,笔记 pdf 下载 --》 【向量数据库与近似最近邻算法】-CSDN文库
速览b站原片!–》 【上集】向量数据库技术鉴赏_哔哩哔哩_bilibili
我的其他文章
RAG调优|AI聊天|知识库问答
- 你是一名平平无奇的大三生,你投递了简历和上线的项目链接,结果HR真打开链接看!结果还报错登不进去QAQ!【RAG知识库问答系统】新增模型混用提示和报错排查【用户反馈与优化-2025.04.28-CSDN博客
- 你知不知道像打字机一样的流式输出效果是怎么实现的?AI聊天项目实战经验:流式输出的前后端完整实现!图文解说与源码地址(LangcahinAI,RAG,fastapi,Vue,python,SSE)-CSDN博客
- 【豆包写的标题…】《震惊!重排序为啥是 RAG 调优杀手锏?大学生实战项目,0 基础也能白嫖学起来》(Langchain-CSDN博客
- 【Langchain】RAG 优化:提高语义完整性、向量相关性、召回率–从字符分割到语义分块 (SemanticChunker)-CSDN博客
- 分享开源项目oneapi的部分API接口文档【oneapi?你的大模型网关】-CSDN博客


















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











