









Binder简单理解
简单来说,Binder 就是用来Client 端和 Server 端通信的。并且 Client 端和 Server 端 可以在一个进程也可以不在同一个进程,Client 可以向 Server 端发起远程调用,也可以向Server传输数据(当作函数参数来传),并且不用关心对方在哪个进程。
Binder的基本原理
Binder借助了内存映射(mmap)的方法,在内核空间和接收方用户空间的数据缓存区之间做了一层内存映射。从发送方用户空间拷贝到内核空间缓存区的数据,就相当于直接拷贝到了接收方用户空间的数据缓存区,从而减少了一次数据拷贝。
IPC通信原理
理解了上面的几个概念,我们再来看看传统的 IPC 方式中,进程之间是如何实现通信的。
通常的做法是消息发送方将要发送的数据存放在内存缓存区中,通过系统调用进入内核态。然后内核程序在内核空间分配内存,开辟一块内核缓存区,调用 copyfromuser() 函数将数据从用户空间的内存缓存区拷贝到内核空间的内核缓存区中。同样的,接收方进程在接收数据时在自己的用户空间开辟一块内存缓存区,然后内核程序调用 copytouser() 函数将数据从内核缓存区拷贝到接收进程的内存缓存区。这样数据发送方进程和数据接收方进程就完成了一次数据传输,我们称完成了一次进程间通信
我们来看下原理图:
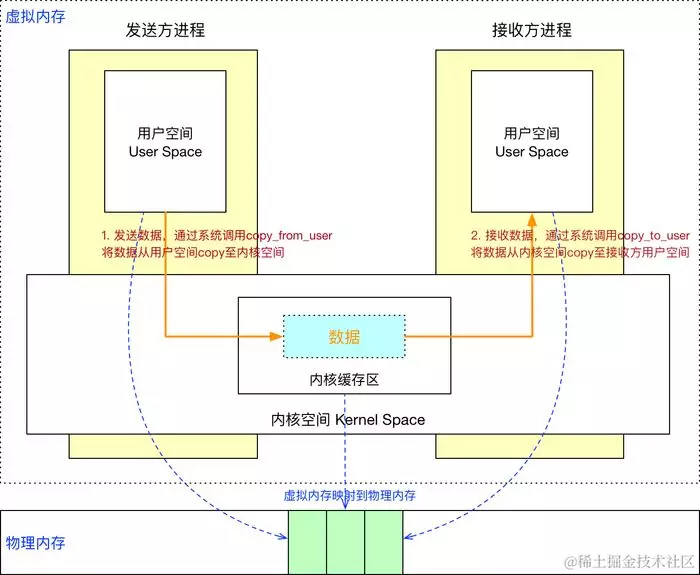
这种传统的 IPC 通信方式有两个问题:
1、性能低下,一次数据传递需要经历:内存缓存区 --> 内核缓存区 --> 内存缓存区,需要 2 次数据拷贝;
2、接收数据的缓存区由数据接收进程提供,但是接收进程并不知道需要多大的空间来存放将要传递过来的数据,因此只能开辟尽可能大的内存空间或者先调用 API 接收消息头来获取消息体的大小,这两种做法不是浪费空间就是浪费时间。
Binder跨进程通信原理
理解了 Linux IPC 相关概念和通信原理,接下来我们正式介绍下 Binder IPC 的原理。
动态内核可加载模块
正如前面所说,跨进程通信是需要内核空间做支持的。传统的 IPC 机制如管道、Socket 都是内核的一部分,因此通过内核支持来实现进程间通信自然是没问题的。但是 Binder 并不是 Linux 系统内核的一部分,那怎么办呢?这就得益于 Linux 的 动态内核可加载模块(Loadable Kernel Module,LKM)的机制;模块是具有独立功能的程序,它可以被单独编译,但是不能独立运行。它在运行时被链接到内核作为内核的一部分运行。这样,Android 系统就可以通过动态添加一个内核模块运行在内核空间,用户进程之间通过这个内核模块作为桥梁来实现通信。
在 Android 系统中,这个运行在内核空间,负责各个用户进程通过 Binder 实现通信的内核模块就叫 Binder 驱动(Binder Dirver)。
那么在 Android 系统中用户进程之间是如何通过这个内核模块(Binder 驱动)来实现通信的呢?难道是和前面说的传统 IPC 机制一样,先将数据从发送方进程拷贝到内核缓存区,然后再将数据从内核缓存区拷贝到接收方进程,通过两次拷贝来实现吗?显然不是,否则也不会有开篇所说的 Binder 在性能方面的优势了。这就涉及到 内存映射 的概念了。
内存映射
Binder IPC 机制中涉及到的内存映射通过 mmap() 来实现,mmap() 是操作系统中一种内存映射的方法。内存映射简单的讲就是将用户空间的一块内存区域映射到内核空间。映射关系建立后,用户对这块内存区域的修改可以直接反应到内核空间;反之内核空间对这段区域的修改也能直接反应到用户空间。
内存映射能减少数据拷贝次数,实现用户空间和内核空间的高效互动。两个空间各自的修改能直接反映在映射的内存区域,从而被对方空间及时感知。也正因为如此,内存映射能够提供对进程间通信的支持。
Binder IPC 实现原理
Binder IPC 正是基于内存映射(mmap)来实现的,但是 mmap() 通常是用在有物理介质的文件系统上的。
比如进程中的用户区域是不能直接和物理设备打交道的,如果想要把磁盘上的数据读取到进程的用户区域,需要两次拷贝(磁盘–>内核空间–>用户空间);通常在这种场景下 mmap() 就能发挥作用,通过在物理介质和用户空间之间建立映射,减少数据的拷贝次数,用内存读写取代I/O读写,提高文件读取效率。
而 Binder 并不存在物理介质,因此 Binder 驱动使用 mmap() 并不是为了在物理介质和用户空间之间建立映射,而是用来在内核空间创建数据接收的缓存空间。
一次完整的 Binder IPC 通信过程通常是这样:
1、首先 Binder 驱动在内核空间创建一个 数据接收缓存区 ;
2、接着在内核空间开辟一块内核缓存区,建立 内核缓存区 和 内核中数据接收缓存区 之间的映射关系,以及 内核中数据接收缓存区 和 接收进程用户空间地址 的映射关系;
3、发送方进程通过系统调用 copyfromuser() 将数据 copy 到内核中的内核缓存区,由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间,这样便完成了一次进程间的通信。
我们来看下原理图:
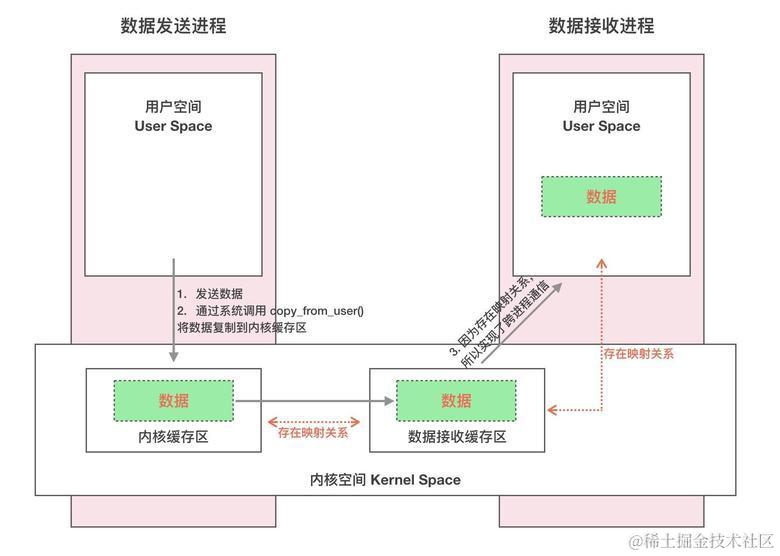
Binder通信流程
我们上面以及聊过,Binder的通信流程是先由Client发出,经过Binder Framework到达Kernel,再经过Kernel转发,最终通过Binder Framework到达Server。整体的通信流程有点像网络通信。
我们以常见的启动四大组件为例来描述Binder的通信流程,如下所示:
1、当我们在Activity里启动一个Service,这个调用会经过层层传递到ActivityManagerProxy,然后ActivityManagerProxy会通过Binder发起跨进程调用。
2、接着Client就会向Binder Driver发起binder ioctl请求,在IPCTreadState::waitForResponse里执行While循环,在While循环中调用IPCThreadState::talkWithDriver()与驱动交互,然后Client线程等待驱动回复
binder驱动收到BC_TRANSACTION事件后的应答消息:
BR_TRANSACTION_COMPLETE:对于oneway transaction(非阻塞通信、单向),当收到该消息,则完成了本次Binder通信
BR_DEAD_REPLY:回复失败,往往是线程或节点为空,则结束本次通信Binder
BR_FAlLED_REPLY:回复失败,往往是transaction出错导致,则结束本次通信Binder
BR_REPLY:对于非oneway transaction时,当收到该消息,则完整地完成本次Binder通信
3、上述命令除了BR_TRANSACTION_COMPLETE:其他回复Client端的进程都会接着调用IPCThreadState::executeCommand()处理驱动返回的命令。
4、对于Server端而言,会调用IPCThreadState::joinThreadPool循环执行IPCThreadState::getAndExecuteCommand,最终调用ActivityManagerService.startService方法。如果需要回复Client会调用talkWithDriver与驱动通信
Client在与Service的通信过程按照是否需要Server返回数据可以分为两种方式:
单向模式:不需要Server返回数据
双向模式:需要Server返回数据
对以上的代码做简单分析:
binder_ioctl -> binder_ioctl_write_read -> binder_thread_write
```java
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
...
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread)
...
}
——————————————————
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
...
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) { //把用户空间数据ubuf拷贝到bwr
ret = -EFAULT;
goto out;
...
if (bwr.write_size > 0) { //写缓冲区有数据时,binder_thread_write
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
...
}
if (bwr.read_size > 0) { //读缓冲区有数据时,binder_thread_read
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
...
}
...
//将内核数据bwr拷贝到用户空间ubuf
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
}
Client端
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
if (reply) {
//等待响应
err = waitForResponse(reply);
} else {
Parcel fakeReply;
err = waitForResponse(&fakeReply);
}
...
} else {
//oneway,则不需要等待 reply 的场景
err = waitForResponse(nullptr, nullptr);
}
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
int32_t cmd;
int32_t err;
//在while循环中做下面的事情:
while (1) {
//循环中通过talkWithDriver与驱动通信
if ((err=talkWithDriver()) < NO_ERROR) break;
...
if (mIn.dataAvail() == 0) continue;
cmd = mIn.readInt32();
switch (cmd) {
... //循环中等待Binder驱动回复,执行executeCommand
err = executeCommand(cmd);
...
}
}
...
return err;
}
—————————————————
status_t IPCThreadState::executeCommand(int32_t cmd)
{
...
switch ((uint32_t)cmd) { //switch判断
case BR_ERROR:
result = mIn.readInt32();
break;
case BR_OK:
break;
case BR_ACQUIRE:
refs = (RefBase::weakref_type*)mIn.readPointer();
obj = (BBinder*)mIn.readPointer();
ALOG_ASSERT(refs->refBase() == obj,
"BR_ACQUIRE: object %p does not match cookie %p (expected %p)",
refs, obj, refs->refBase());
obj->incStrong(mProcess.get());
IF_LOG_REMOTEREFS() {
LOG_REMOTEREFS("BR_ACQUIRE from driver on %p", obj);
obj->printRefs();
}
mOut.writeInt32(BC_ACQUIRE_DONE);
mOut.writePointer((uintptr_t)refs);
mOut.writePointer((uintptr_t)obj);
break;
case BR_RELEASE:
refs = (RefBase::weakref_type*)mIn.readPointer();
obj = (BBinder*)mIn.readPointer();
...
Server端
void IPCThreadState::joinThreadPool(bool isMain)
{
...
do { //循环里面不断的读取命令数据,然后解析命令数据,并给出相应的响应。
processPendingDerefs();
// now get the next command to be processed, waiting if necessary
result = getAndExecuteCommand();
...
}
—————————————————————
status_t IPCThreadState::getAndExecuteCommand()
{
status_t result;
int32_t cmd;
result = talkWithDriver();
if (result >= NO_ERROR) {
size_t IN = mIn.dataAvail();
if (IN < sizeof(int32_t)) return result;
cmd = mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing top-level Command: "
<< getReturnString(cmd) << endl;
}
pthread_mutex_lock(&mProcess->mThreadCountLock);
mProcess->mExecutingThreadsCount++;
if (mProcess->mExecutingThreadsCount >= mProcess->mMaxThreads &&
mProcess->mStarvationStartTimeMs == 0) {
mProcess->mStarvationStartTimeMs = uptimeMillis();
}
pthread_mutex_unlock(&mProcess->mThreadCountLock);
//解析来自驱动的命令
result = executeCommand(cmd);
pthread_mutex_lock(&mProcess->mThreadCountLock);
mProcess->mExecutingThreadsCount--;
if (mProcess->mExecutingThreadsCount < mProcess->mMaxThreads &&
mProcess->mStarvationStartTimeMs != 0) {
int64_t starvationTimeMs = uptimeMillis() - mProcess->mStarvationStartTimeMs;
if (starvationTimeMs > 100) {
ALOGE("binder thread pool (%zu threads) starved for %" PRId64 " ms",
mProcess->mMaxThreads, starvationTimeMs);
}
mProcess->mStarvationStartTimeMs = 0;
}
pthread_cond_broadcast(&mProcess->mThreadCountDecrement);
pthread_mutex_unlock(&mProcess->mThreadCountLock);
}
return result;
}
本文主要对在Android开发中的binder通信机制原理的理解,更多有关通讯以及Android开发的技术进阶可以前往《Android高级开发进阶手册》点击可以查看详细内容板块。
Binder 的完整定义
1.从进程间通信的角度看,Binder 是一种进程间通信的机制;
2.从 Server 进程的角度看,Binder 指的是 Server 中的 Binder 实体对象;
3.从 Client 进程的角度看,Binder 指的是对 Binder 代理对象,是 Binder 实体对象的一个远程代理
4.从传输过程的角度看,Binder 是一个可以跨进程传输的对象;Binder 驱动会对这个跨越进程边界的对象对一点点特殊处理,自动完成代理对象和本地对象之间的转换。














 4475
4475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









