







泰坦尼克号是20世纪最著名的沉船之一,造成了大量的人员伤亡。在这个悲剧事件中,有人能够生还,也有人不幸丧生。在本文中,我们将尝试利用支持向量机(Support Vector Machine,简称SVM)这一分类算法,根据一些特征数据来预测泰坦尼克号上的乘客是否能够生还。通过实践案例我们将展示SVM如何应用于预测分类问题,并提供对泰坦尼克号生还情况的预测。
一、数据获取和理解
首先,我们需要获取泰坦尼克号乘客的相关数据,包括乘客的年龄、性别、舱位等信息,并了解数据的结构和特征。我们可以通过一些开放的数据集,如Kaggle提供的泰坦尼克号数据集进行实践。
二、数据预处理
在进行数据分析之前,我们需要对数据进行预处理。这可能包括处理缺失值、对文本类别变量进行编码、特征标准化等操作。预处理的目的是将数据转化为模型能够处理的形式。
三、特征工程
根据我们的目标,我们需要选择那些对生还情况具有影响力的特征。比如,乘客的性别、舱位、年龄等特征可能对生还与否有重要影响。我们将根据数据中的特征进行分析,并选择适当的特征作为模型输入。

四、数据集划分
为了评估模型的性能,我们需要将数据集划分为训练集和测试集。这样我们可以用训练集来训练模型,并用测试集来评估模型的预测能力。
五、构建支持向量机模型
在Sklearn库中,我们可以选择合适的SVM模型,并根据我们的数据集选择适当的核函数。在这个案例中,我们可以选择线性核函数或高斯核函数,并设置其他的参数。
from sklearn.svm import SVC
# 创建SVM模型
svm_model = SVC(kernel='rbf', C=1.0, gamma='scale') 六、模型训练与预测
我们使用训练集对模型进行训练,并使用训练好的模型对测试集进行预测。
# 模型训练
svm_model.fit(X_train, y_train)
# 模型预测
y_pred = svm_model.predict(X_test)七、模型评估
为了评估模型的性能,我们可以计算预测结果的准确率或其他指标,如精确率、召回率等。
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)通过核心的分类准确率,我们可以评估SVM模型在预测泰坦尼克号乘客是否生还的性能。
八、结论
本文通过应用支持向量机算法来预测泰坦尼克号乘客的生还情况,通过构建SVM模型、数据预处理和特征工程的过程,详细揭示了SVM在分类问题上的应用。实践过程中,我们利用Sklearn库来实现SVM模型,预测结果的准确率可以作为模型性能的评估指标。
希望通过本文对于如何利用支持向量机判断乘客是否能从泰坦尼克号生还有所了解。当然,该方法只是一个简单的示例,实际应用中可能需要更多的特征工程和模型调优才能取得更好的结果。
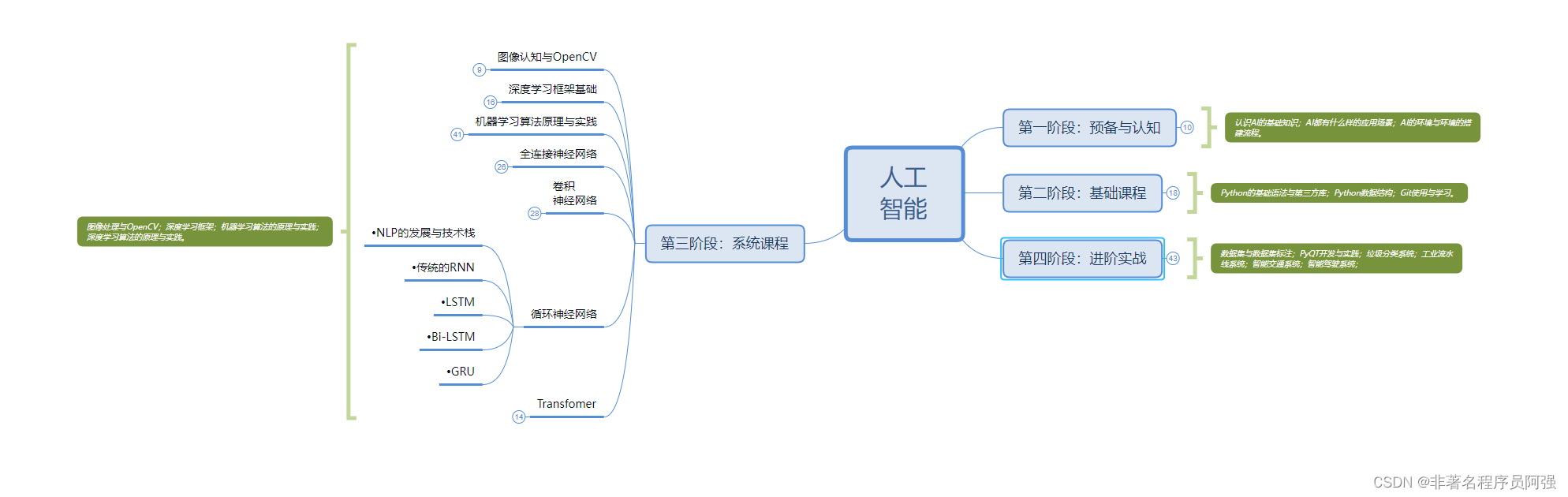
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料















 2213
2213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









