







论文信息
论文标题:Deep Graph Infomax
论文作者:Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, R Devon Hjelm
论文来源:2019,ICLR
论文地址:download
论文代码:download
一、Abstract
DGI是一种在图结构数据中以无监督方式学习节点表示的通用方法。DGI依赖于最大化patch representations和相应的high-level summaries of graph之间的互信息,这两者都是使用已建立的图卷积网络体系结构导出的。学习到的patch representations总结了围绕感兴趣节点的子图,因此可以用于下游节点学习任务。与以往使用GCN进行无监督学习的大多数方法相比,DGI不依赖于随机行走目标,并且很容易适用于transductive learning和inductive learning设置。
二、DGI
(一)基于图的无监督学习
目标是学习编码器,
E
:
R
N
×
F
×
R
N
×
N
→
R
N
×
F
′
\mathcal{E}: \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{N \times F^{\prime}}
E:RN×F×RN×N→RN×F′,使得
E
(
X
,
A
)
=
H
=
{
h
⃗
1
,
h
⃗
2
,
…
,
h
⃗
N
}
\mathcal{E}(\mathbf{X}, \mathbf{A})=\mathbf{H}=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \vec{h}_{N}\right\}
E(X,A)=H={h1,h2,…,hN}表示hige-level representations,
h
⃗
i
∈
R
F
′
\vec{h}_{i} \in \mathbb{R}^{F^{\prime}}
hi∈RF′表示第i个节点。然后可以检索这些表示并用于下游任务,例如节点分类。
在这里,我们将重点关注图卷积编码器——一种灵活的节点嵌入体系结构,它通过在局部节点邻域上重复聚合来生成节点表示。一个关键的结果是,生成的节点嵌入
h
⃗
i
\vec h_{i}
hi总结了一个以节点i为中心的图块,而不仅仅是节点本身。以下内容将
h
⃗
i
\vec h_{i}
hicheng称为patch representations。
(二)局部-全局互信息最大化
我们学习编码器的方法依赖于最大化局部互信息,也就是说,我们寻求获得节点(即局部)表示,以捕获整个图的全局信息内容,由summary vector,
s
⃗
\vec s
s 表示。
为了获得graph-level summary vectors,
s
⃗
\vec s
s,我们利用读出函数
R
:
R
N
×
F
→
R
F
\mathcal R:\mathbb R^{N \times F}\rightarrow \mathbb R^{F}
R:RN×F→RF,并使用它将获得的patch representations汇总为graph-level representation;
i
.
e
.
,
s
⃗
=
R
(
E
(
X
,
A
)
)
i.e.,\vec s=\mathcal R\left(\mathcal{E}\left(X,A\right)\right)
i.e.,s=R(E(X,A))。
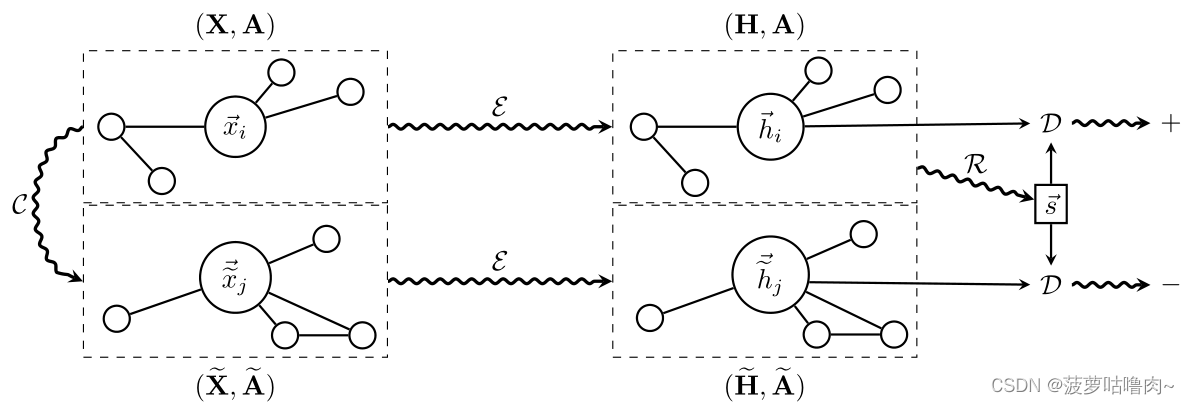
作为最大化局部互信息的代理,我们使用了一个鉴别器 D : R F × R F → R \mathcal{D}: \mathbb{R}^{F} \times \mathbb{R}^{F} \rightarrow \mathbb{R} D:RF×RF→R 这样, D ( h ⃗ i , s ⃗ ) \mathcal{D}\left(\vec{h}_{i}, \vec{s}\right) D(hi,s)代表分配给该patch-summary pair的概率分数(对于summary中包含的patches,概率分数应该更高)。
Negative samples for D \mathcal{D} D是:summary s ⃗ \vec s s from ( X , A ) (X,A) (X,A)和patch representations h ~ → j \overrightarrow{\widetilde{h}}_{j} h j from ( X ~ , A ~ ) (\widetilde{\mathbf{X}}, \widetilde{\mathbf{A}}) (X ,A )。
目标函数:
L
=
1
N
+
M
(
∑
i
=
1
N
E
(
X
,
A
)
[
log
D
(
h
⃗
i
,
s
⃗
)
]
+
∑
j
=
1
M
E
(
X
~
,
A
~
)
[
log
(
1
−
D
(
h
~
→
j
,
s
⃗
)
)
]
)
\mathcal{L}=\frac{1}{N+M}\left(\sum_{i=1}^{N} \mathbb{E}_{(\mathbf{X}, \mathbf{A})}\left[\log \mathcal{D}\left(\vec{h}_{i}, \vec{s}\right)\right]+\sum_{j=1}^{M} \mathbb{E}_{(\tilde{\mathbf{X}}, \tilde{\mathbf{A}})}\left[\log \left(1-\mathcal{D}\left(\overrightarrow{\widetilde{h}}_{j}, \vec{s}\right)\right)\right]\right)
L=N+M1(i=1∑NE(X,A)[logD(hi,s)]+j=1∑ME(X~,A~)[log(1−D(h
j,s))])
最大化
h
⃗
i
\vec h_{i}
hi和
s
⃗
\vec s
s之间的互信息。
对于节点分类,我们的目标是让patches在整个图中建立到类似patches的链接,而不是强制summary包含所有这些相似性(然而,原则上这两种影响应同时发生)。
(三)Overview of DGI
假设输入为单图
(
X
,
A
)
(X,A)
(X,A),DGI过程的步骤可总结如下:















 9437
9437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









