







目录
论文信息
论文标题:COMPLETER: Incomplete Multi-view Clustering via Contrastive Prediction
论文作者:Yijie Lin, Yuanbiao Gou, Zitao Liu, Boyun Li, Jiancheng Lv, Xi Peng
论文来源: 2021,CVPR
论文地址:download
论文代码:download
一、Abstract
本文研究了不完全多视图聚类分析中两个具有挑战性的问题,i)如何在没有标签的帮助下学习不同视图之间的信息性和一致性表示,ii)如何从数据中恢复缺失的视图。
本文提出了一个新的目标,即从信息论的角度将表示学习和数据恢复整合到一个统一的框架中。具体来说,通过对比学习最大化不同视图之间的互信息来学习信息丰富的一致表示,通过双重预测最小化不同视图的条件熵来恢复缺失的视图。
本文所指的数据恢复是面向任务的,即只恢复共享的信息而不是所有的信息,以便于MVC等下游任务的完成。
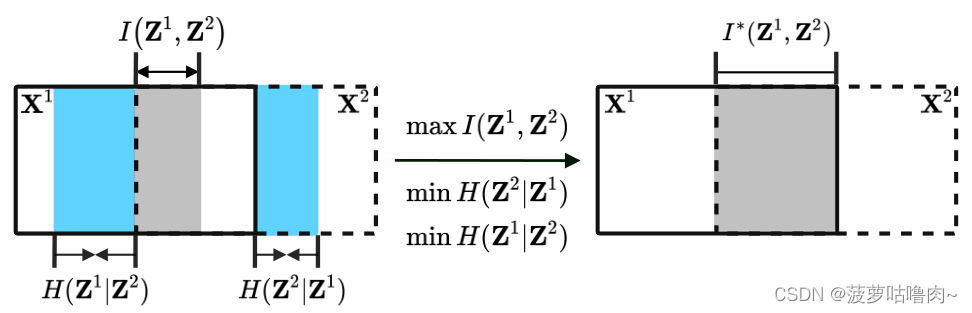
实线和虚线矩阵分别表示视图1
(
X
1
)
(X^1)
(X1)和视图2
(
X
2
)
(X^2)
(X2)中包含的信息。
互信息
I
(
Z
1
,
Z
2
)
I(Z^1,Z^2)
I(Z1,Z2)(灰色区域),量化了
Z
1
Z^1
Z1和
Z
2
Z^2
Z2共享的信息量,其中
Z
1
Z^1
Z1和
Z
2
Z^2
Z2分别是
X
1
X^1
X1和
X
1
X^1
X1的表示。【为了学习一致的表示,最大化互信息】
条件熵
H
(
Z
i
∣
Z
j
)
H(Z^i|Z^j)
H(Zi∣Zj)(蓝色区域)最小化,这将鼓励恢复丢失的视图,因为当且仅当
H
(
Z
i
∣
Z
j
)
=
0
H(Z^i|Z^j)=0
H(Zi∣Zj)=0时,
Z
i
Z^i
Zi完全由
Z
j
Z^j
Zj确定,其中i=1,j=2或i=2,j=1。
一方面,
I
(
Z
1
,
Z
2
)
I(Z^1,Z^2)
I(Z1,Z2)的最大化可以增加共享信息的数量,从而提高数据的可恢复性,即更容易从一个视图恢复到另一个视图。另一方面,当
H
(
Z
i
∣
Z
j
)
H(Z^i|Z^j)
H(Zi∣Zj)量化以
Z
j
Z^j
Zj为条件的
Z
i
Z^i
Zi的信息量时,
H
(
Z
i
∣
Z
j
)
H(Z^i|Z^j)
H(Zi∣Zj)的最小化将鼓励丢弃不同视图之间的不一致信息,从而进一步提高一致性。
二、Introduction
1.一些研究表明:对比学习的成功可以归因于互信息的最大化。
2.不一致性可以用条件熵来定义,而缺失的数据可以通过最小化不一致性来恢复。
三、The Proposed Method(COMPLETER)
对比预测的不完全多视图聚类(COMPLETER)
(一)整体框架
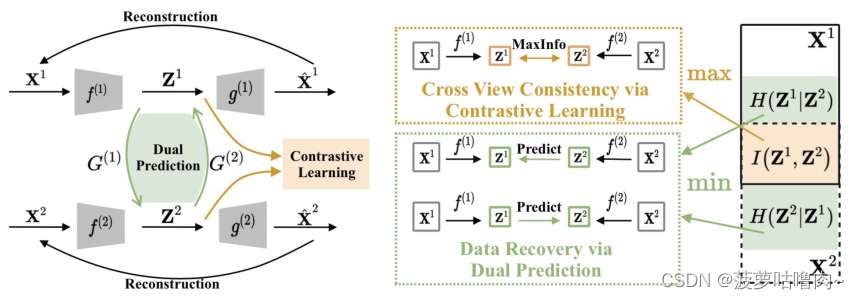
方法包含三个联合学习目标,即视图内重建、跨视图对比学习和跨视图双重预测。具体而言,视图内重建目标旨在以最小的重建损失将所有视图投影到视图特定的空间中。通过最大化
Z
1
Z^1
Z1和
Z
2
Z^2
Z2之间的互信息来实现跨视角对比学习目标。交叉视图双重预测目标通过最小化条件熵
H
(
Z
i
∣
Z
j
)
H(Z^i|Z^j)
H(Zi∣Zj),利用两个映射
G
(
1
)
G^{(1)}
G(1)和
G
(
2
)
G^{(2)}
G(2)从另一个视图恢复一个视图。
(二)目标函数
以双视图数据为例。给定n个实例的数据集,
X
‾
=
{
X
‾
1
,
2
,
X
‾
1
,
X
‾
2
}
\overline{\mathbf{X}}=\left\{\overline{\mathbf{X}}^{1,2}, \overline{\mathbf{X}}^{1}, \overline{\mathbf{X}}^{2}\right\}
X={X1,2,X1,X2},其中
X
‾
1
,
2
,
X
‾
1
,
X
‾
2
\overline{\mathbf{X}}^{1,2}, \overline{\mathbf{X}}^{1}, \overline{\mathbf{X}}^{2}
X1,2,X1,X2分别表示examples presented in both views,the first view only,and the second view only。
m为
X
‾
1
,
2
\overline{\mathbf{X}}^{1,2}
X1,2的完整examples的数据大小。
L
=
L
c
l
+
λ
1
L
p
r
e
+
λ
2
L
r
e
c
\mathcal{L}=\mathcal{L}_{c l}+\lambda_{1} \mathcal{L}_{p r e}+\lambda_{2} \mathcal{L}_{r e c}
L=Lcl+λ1Lpre+λ2Lrec
1.视图内重建
对于每个视图,我们将其通过自动编码器,通过最小化来学习潜在表示
Z
v
Z^v
Zv。
L
r
e
c
=
∑
v
=
1
2
∑
t
=
1
m
∥
X
t
v
−
g
(
v
)
(
f
(
v
)
(
X
t
v
)
)
∥
2
2
\mathcal{L}_{r e c}=\sum_{v=1}^{2} \sum_{t=1}^{m}\left\|\mathbf{X}_{t}^{v}-g^{(v)}\left(f^{(v)}\left(\mathbf{X}_{t}^{v}\right)\right)\right\|_{2}^{2}
Lrec=v=1∑2t=1∑m∥∥∥Xtv−g(v)(f(v)(Xtv))∥∥∥22
X
t
v
X_t^v
Xtv表示
X
v
X^v
Xv的第t个样本。
f
(
v
)
、
g
(
v
)
f^{(v)}、g^{(v)}
f(v)、g(v)表示第v视图的编码器和解码器。因此,第v视图中第t个样本的表示如下所示:
Z
t
v
=
f
(
v
)
(
X
t
v
)
\mathbf{Z}_{t}^{v}=f^{(v)}(X_t^v)
Ztv=f(v)(Xtv)
2.跨视图对比学习
在
L
r
e
c
\mathcal L_{rec}
Lrec参数化的潜在空间中,我们进行对比学习,学习不同视图之间的共同表示。
L
c
l
=
−
∑
t
=
1
m
(
I
(
Z
t
1
,
Z
t
2
)
+
α
(
H
(
Z
t
1
)
+
H
(
Z
t
2
)
)
)
\mathcal{L}_{c l}=-\sum_{t=1}^{m}\left(I\left(\mathbf{Z}_{t}^{1}, \mathbf{Z}_{t}^{2}\right)+\alpha\left(H\left(\mathbf{Z}_{t}^{1}\right)+H\left(\mathbf{Z}_{t}^{2}\right)\right)\right)
Lcl=−t=1∑m(I(Zt1,Zt2)+α(H(Zt1)+H(Zt2)))
从信息论来看,信息熵是一个事件所传递的平均信息量。因此更大的熵 H ( Z i ) H(Z^i) H(Zi)表示信息更丰富的表示 Z i Z_i Zi。
另一方面, H ( Z 1 ) H(Z^1) H(Z1)和 H ( Z 2 ) H(Z^2) H(Z2)的最大化将避免将所有样本分配给同一个簇。
为了表示
I
(
Z
t
1
,
Z
t
2
)
I\left(\mathbf{Z}_{t}^{1}, \mathbf{Z}_{t}^{2}\right)
I(Zt1,Zt2),我们首先定义变量
z
z
z和
z
′
z^{\prime}
z′的联合概率分布
P
(
z
,
z
′
)
\mathcal{P}\left(z, z^{\prime}\right)
P(z,z′)。由于softmax函数堆叠在编码器的最后一层,
Z
1
Z_1
Z1和
Z
2
Z_2
Z2的每个元素都可以被视为超簇类概率。换句话说,
Z
1
Z_1
Z1和
Z
2
Z_2
Z2可以理解为两个离散的cluster分配变量z和
z
′
z^{\prime}
z′在D“类”上的分布,其中D是
Z
1
Z_1
Z1和
Z
2
Z_2
Z2的维数。因此,
P
(
z
,
z
′
)
\mathcal{P}\left(z, z^{\prime}\right)
P(z,z′)被定义为
P
∈
R
D
×
D
P \in \mathcal R^{D \times D}
P∈RD×D,
i
.
e
.
i.e.
i.e.,
P
=
1
m
∑
t
=
1
m
Z
t
1
(
Z
t
2
)
⊤
\mathbf{P}=\frac{1}{m} \sum_{t=1}^{m} \mathbf{Z}_{t}^{1}\left(\mathbf{Z}_{t}^{2}\right)^{\top}
P=m1t=1∑mZt1(Zt2)⊤
P
d
\mathbf{P}_d
Pd和
P
d
′
\mathbf{P}_d^{\prime}
Pd′表示边际概率分布
P
(
z
=
d
)
\mathcal P(z=d)
P(z=d)和
P
(
z
=
d
′
)
\mathcal P(z=d^{\prime})
P(z=d′),它们可以通过对联合概率分布矩阵
P
\mathbf P
P的第
d
d
d行和第
d
′
d^{\prime}
d′列求和得到。
对于离散分布:
L
c
l
=
−
∑
d
=
1
D
∑
d
′
=
1
D
P
d
d
′
ln
P
d
d
′
P
d
α
+
1
⋅
P
d
′
α
+
1
\mathcal{L}_{c l}=-\sum_{d=1}^{D} \sum_{d^{\prime}=1}^{D} \mathbf{P}_{d d^{\prime}} \ln \frac{\mathbf{P}_{d d^{\prime}}}{\mathbf{P}_{d}^{\alpha+1} \cdot \mathbf{P}_{d^{\prime}}^{\alpha+1}}
Lcl=−d=1∑Dd′=1∑DPdd′lnPdα+1⋅Pd′α+1Pdd′
P
d
d
′
{\mathbf{P}_{d d^{\prime}}}
Pdd′是P的第d行和第d′列的元素,α是熵的平衡参数。
3.跨视图双重预测
H
(
Z
i
∣
Z
j
)
=
−
E
P
Z
i
,
Z
j
[
log
P
(
Z
i
∣
Z
j
)
]
=
0
H\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)=-\mathbb{E}_{\mathcal{P}_{\mathbf{Z}^{i}, \mathbf{Z}^{j}}\left[\log \mathcal{P}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)\right]=0}
H(Zi∣Zj)=−EPZi,Zj[logP(Zi∣Zj)]=0
一种常用的近似方法是引入variational distribution(变分分布)
Q
(
Z
i
∣
Z
j
)
\mathcal{Q}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)
Q(Zi∣Zj),
E
P
Z
i
,
Z
j
[
log
P
(
Z
i
∣
Z
j
)
]
=
E
P
z
i
,
Z
j
[
log
Q
(
Z
i
∣
Z
j
)
]
+
D
K
L
(
P
(
Z
i
∣
Z
j
)
∥
Q
(
Z
i
∣
Z
j
)
)
\begin{aligned} \mathbb{E}_{\mathcal{P}_{\mathbf{Z}^{i}, \mathbf{Z}^{j}}}\left[\log \mathcal{P}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)\right]=& \mathbb{E}_{\mathcal{P}_{\mathbf{z}^{i}, \mathbf{Z}^{j}}}\left[\log \mathcal{Q}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)\right]+\\ & D_{\mathrm{KL}}\left(\mathcal{P}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right) \| \mathcal{Q}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)\right) \end{aligned}
EPZi,Zj[logP(Zi∣Zj)]=EPzi,Zj[logQ(Zi∣Zj)]+DKL(P(Zi∣Zj)∥Q(Zi∣Zj))
这种变分分布
Q
\mathcal Q
Q可以是任何类型,如高斯分布和拉普拉斯分布。实际上,我们简单地假设分布
Q
\mathcal Q
Q为高斯分布
N
(
Z
i
∣
G
(
j
)
(
Z
j
)
,
σ
I
)
\mathcal{N}\left(\mathbf{Z}^{i} \mid G^{(j)}\left(\mathbf{Z}^{j}\right), \sigma \mathbf{I}\right)
N(Zi∣G(j)(Zj),σI),其中,
G
(
j
)
(
⋅
)
G^{(j)}\left(\cdot\right)
G(j)(⋅)可以是一个将
Z
j
\mathbf{Z}^{j}
Zj映射到
Z
i
\mathbf{Z}^{i}
Zi的参数化模型,
σ
I
\sigma \mathbf{I}
σI 是方差矩阵。通过忽略高斯分布得出的常数,最大化
E
P
z
i
,
Z
j
[
log
Q
(
Z
i
∣
Z
j
)
]
\mathbb{E}_{\mathcal{P}_{\mathbf{z}^{i}, \mathbf{Z}^{j}}}\left[\log \mathcal{Q}\left(\mathbf{Z}^{i} \mid \mathbf{Z}^{j}\right)\right]
EPzi,Zj[logQ(Zi∣Zj)]相当于
min
E
P
Z
i
,
Z
j
∥
Z
i
−
G
(
j
)
(
Z
j
)
∥
2
2
\min \mathbb{E}_{\mathcal{P}_{\mathbf{Z}^{i}, \mathbf{Z}^{j}}}\left\|\mathbf{Z}^{i}-G^{(j)}\left(\mathbf{Z}^{j}\right)\right\|_{2}^{2}
minEPZi,Zj∥∥Zi−G(j)(Zj)∥∥22
对于给定的双视图数据集,有:
L
pre
=
∥
G
(
1
)
(
Z
1
)
−
Z
2
∥
2
2
+
∥
G
(
2
)
(
Z
2
)
−
Z
1
∥
2
2
\mathcal{L}_{\text {pre }}=\left\|G^{(1)}\left(\mathbf{Z}^{1}\right)-\mathbf{Z}^{2}\right\|_{2}^{2}+\left\|G^{(2)}\left(\mathbf{Z}^{2}\right)-\mathbf{Z}^{1}\right\|_{2}^{2}
Lpre =∥∥∥G(1)(Z1)−Z2∥∥∥22+∥∥∥G(2)(Z2)−Z1∥∥∥22
需要指出的是,上述损失可能导致无视图内重建损失的平凡解,即 Z 1 \mathbf Z^1 Z1和 Z 2 \mathbf Z^2 Z2等效相同常数。
模型收敛后,通过双重映射,可以很容易地从
Z
‾
j
\overline{\mathbf{Z}}^{j}
Zj预测缺失的表示
Z
‾
i
\overline{\mathbf{Z}}^{i}
Zi,即:
Z
‾
i
=
G
(
j
)
(
Z
‾
j
)
=
G
(
j
)
(
f
(
j
)
(
X
‾
j
)
)
\overline{\mathbf{Z}}^{i}=G^{(j)}\left(\overline{\mathbf{Z}}^{j}\right)=G^{(j)}\left(f^{(j)}\left(\overline{\mathbf{X}}^{j}\right)\right)
Zi=G(j)(Zj)=G(j)(f(j)(Xj))















 3061
3061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









