







结合最新开源的LLM模型、TTS语音合成、Lip-Sync唇形同步等技术,我们可以构建出一个流式数字人的问答系统。该系统不仅能够理解复杂问题并给出精准回答,还能通过自然的语音输出和逼真的口型动画,实现类似真人般的沟通体验。其中整个系统框架如下图所示:
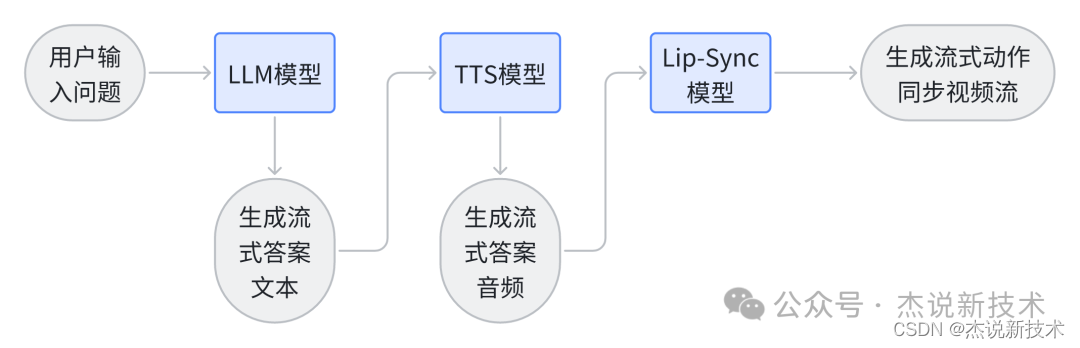
整个系统的框架可以分为三个关键部分:LLM模型、TTS模型和Lip-Sync模型。下面分别介绍这三个部分的原理概念和推荐的现有开源模型。
一、LLM模型

原理概念:LLM模型,即大型语言模型(Large Language Model),是一种具有大规模参数和复杂计算结构的大型机器学习模型。
LLM的核心是Transformer模型,这是一种基于自注意力机制的深度学习架构。自注意力机制允许模型在处理输入数据时同时考虑序列中的所有其他元素,从而有效捕捉文本中的长距离依赖关系。
此外,位置编码的引入解决了Transformer模型处理序列数据时缺乏位置信息的问题,增强了模型对语言结构的建模能力。
在该问答系统中,用户通过输入任意的问题,现有的LLM模型都可以回答得上。LLM凭借其强大的泛化能力,即使在没有见过完全相同问题的情况下,也能基于相关知识推断出答案。
现有开源LLM模型推荐:
1、Mistral 7B:由Mistral AI开发的开源LLM,支持长上下文长度,适用于扩展文本任务如文档摘要、长问答和上下文感知生成。
2、ChatGLM-6B:一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化,基于General Language Model (GLM)架构,具有62亿参数。
3、Gemma:Google开发的开源LLM,支持长达8192个标记的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









