







1、来历、本质及目标
解决数据不足、不允许交换、不愿意贡献价值造成的数据孤岛和隐私保护的问题。
本质是分布式机器学习技术/框架。
目标是在保证数据隐私安全及合法合规的基础上,共同建模,提升AI模型的效果。
2、分类

1)横向联邦学习

2)纵向联邦学习
是交叉用户在不同业务下的特征联合
本质是特征的联合(用户重叠多、特征重叠少)(样本相同、特征不同)例如某地的商超和银行
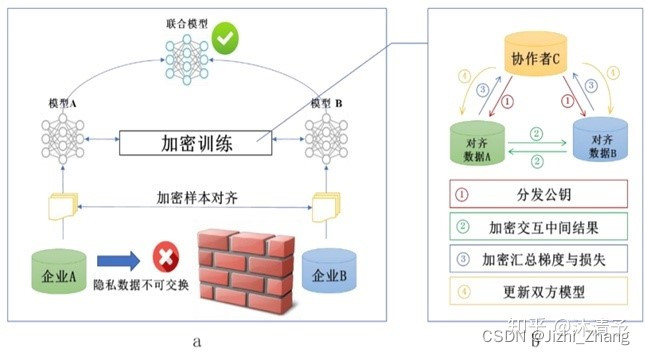
两大步a:
第一步:加密样本对齐:系统级(对齐样本:不同行的数据有相同的数据特征),
即找出参与者拥有的共同的样本,也就叫“数据库撞库。
第二步:对齐样本进行模型加密训练b:
step1:由第三方C向A和B发送公钥,用来加密需要传输的数据;
step2:A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;
step3:A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;
step4:C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
后面需找一些例子
3)联邦迁移学习
- 1、迁移学习是只利用数据、任务或模型之间的相似性,把在源领域学习过的模型应用在目标领域的一种学习过程,核心是找到源领域和目标领域间的相似性(不变量)
- 适用场景:参与者之间的特征和样本重叠都很少的情况,适用于以深度神经网络为基模型
- 2、学习步骤:与纵向联邦学习类似,但中间传递结果不同。

注:横向与纵向对比:
1、横向联邦学习的名称来源于训练数据的“横向划分”,也就是数据矩阵或者表格的按行(横向)划分。不同行的数据有相同的数据特征,即数据特征是对齐的。
2、纵向联邦学习的名称来源于训练数据的“纵向划分”,也就是数据矩阵或者表格的按列(纵向)划分。不同列的数据有相同的样本ID,即训练样本是对齐的。















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









