







 本文是关于联邦学习的综述,介绍了其出现原因,包括数据不充分或不完整。详细阐述纵向、横向联邦学习流程,如纵向的加密样本对齐、加密模型训练和效果激励,横向的模型下载、训练、聚合更新等。还对比了联邦学习与数据中心分布式学习的区别,指出其数据偏见性和通信限制等问题。
本文是关于联邦学习的综述,介绍了其出现原因,包括数据不充分或不完整。详细阐述纵向、横向联邦学习流程,如纵向的加密样本对齐、加密模型训练和效果激励,横向的模型下载、训练、聚合更新等。还对比了联邦学习与数据中心分布式学习的区别,指出其数据偏见性和通信限制等问题。
联邦学习出现的原因:联邦双方数据不充分或者数据不完整(一方只有标签、一方只有特征数据)
纵向联邦:样本重叠多,特征重叠少,拓展特征维
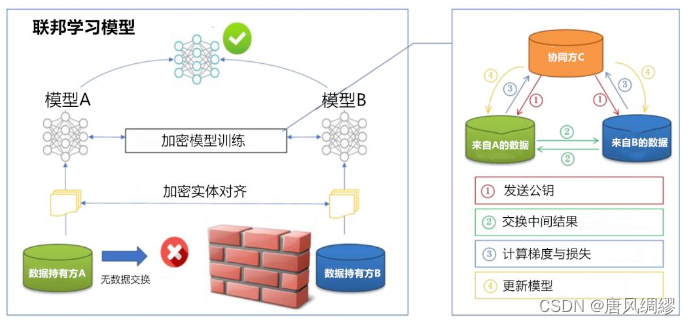
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相
联邦学习出现的原因:联邦双方数据不充分或者数据不完整(一方只有标签、一方只有特征数据)
纵向联邦:样本重叠多,特征重叠少,拓展特征维
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相
 346
8171
3976
4万+
3034
346
8171
3976
4万+
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























