







2024/3/25:
SPSS 二元logisitic 回归:
基本了解:因变量:分类变量;
自变量:连续变量;(若有分类变量,则变为哑变量)

-à主要用于医学方面:![]()
重点:样本量:是自变量的5-10倍;(总样本量是自变量的5倍以上)
(样本量的一般准则)
结局变量:(如阳性)不能低于总样本量的15%(注意:用PASS的计算样本量的计算软件)
分析->回归->二元logisitic回归
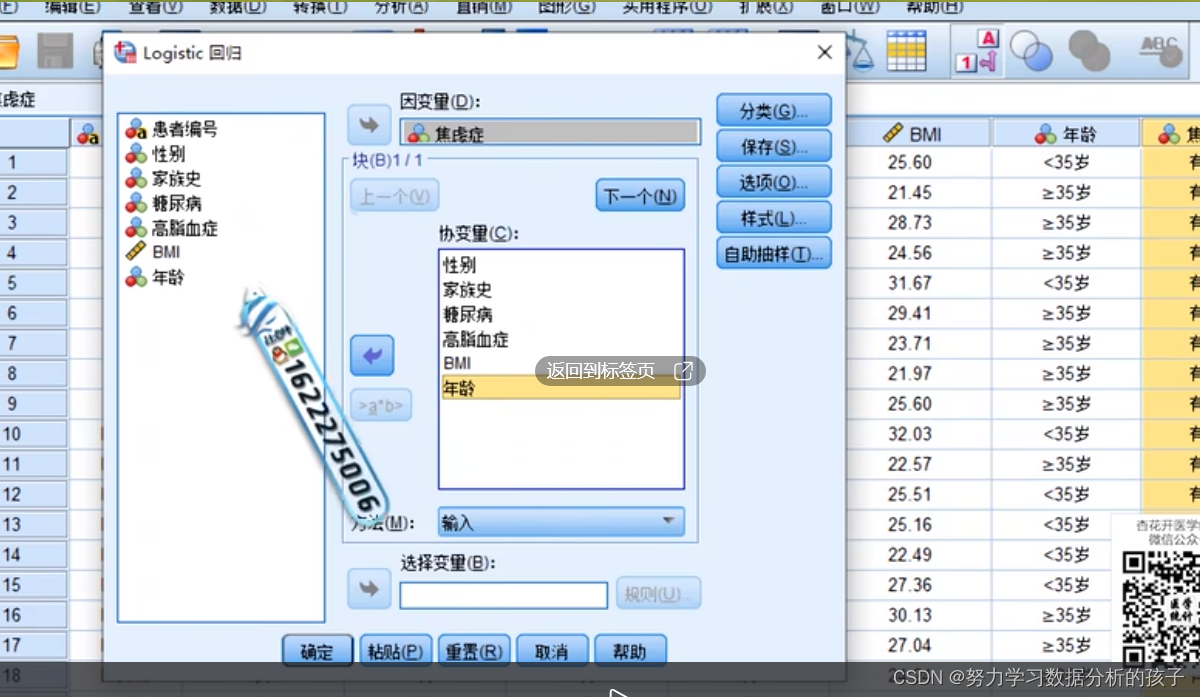
自变量为分类变量的处理:->将分类变量做一个哑变量的处理
即分类协变量;
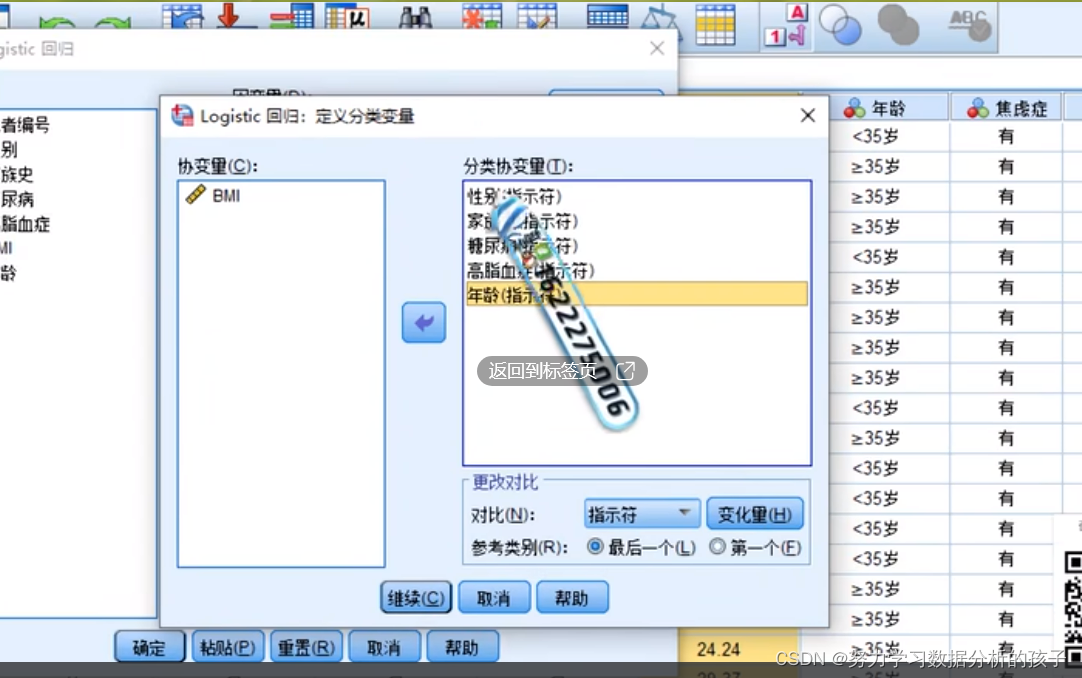
生成哑变量之后:
一般:无(否)->0; 是(有)->1(阴性一定是0,阳性的一定是1)
其中,无作为一个参考类别(即0作为一个参考类别)
继续->选项->霍斯摩…+Exp(B)的置信区间.->
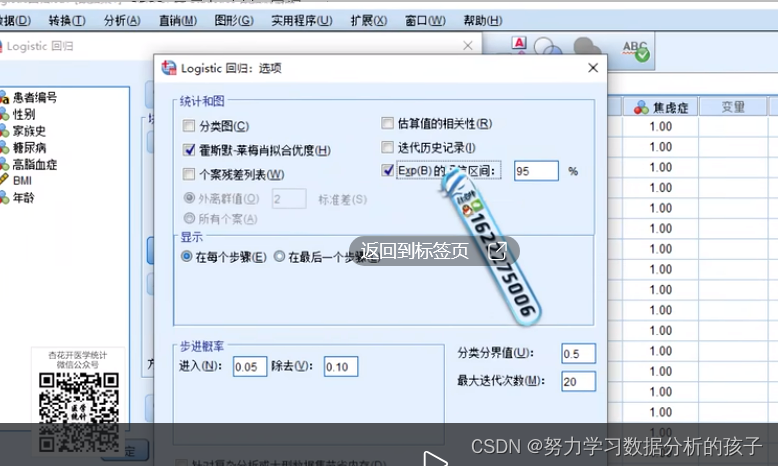
确定:
结果:
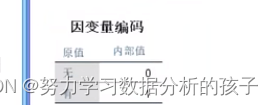
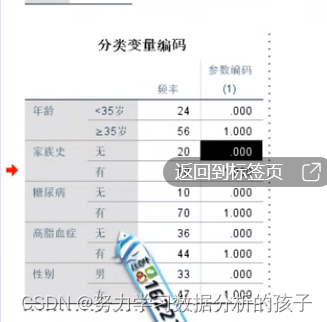 0代表一个参考类别,1代表一个
0代表一个参考类别,1代表一个

拟合优度的状况:(是否良好)
(显著性)p=0.653>0.5(接受原假设,即能够反映原始变量的真实关系
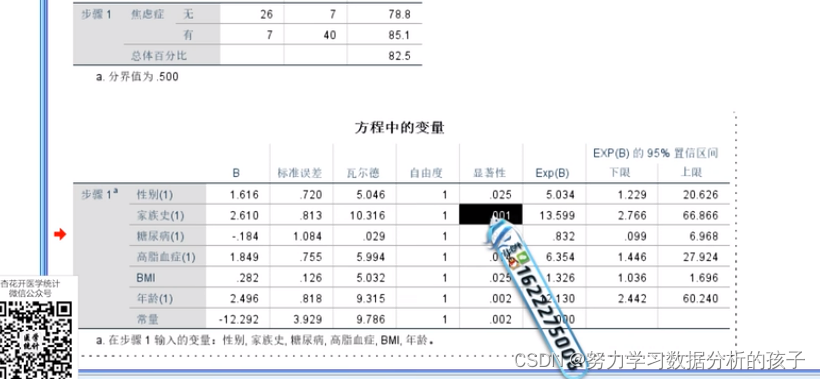
Exp(B):(OR)
分类协变量
意思是女(1)=5.034*男(0)倍;
(显著性<0.5,显著性影响)
其他变量类同;
自变量(协变量):
BMI:
比多一个单位,导致因变量提升0.326倍。
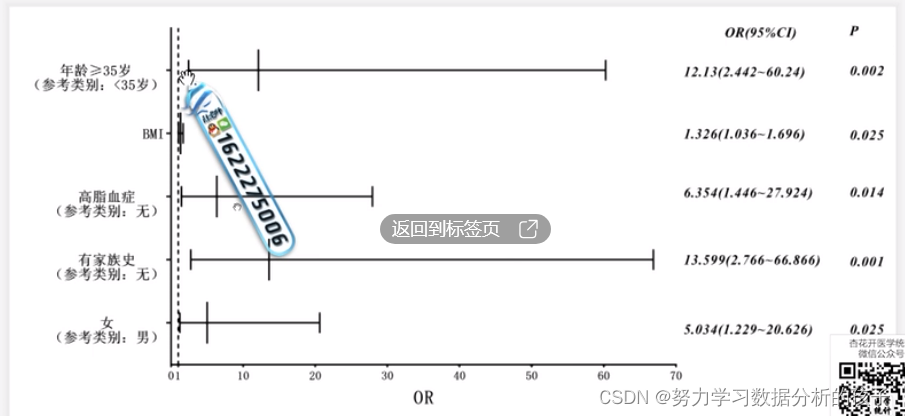
可见,家族史是一个核心因素;(OR)
该图又GraphPad进行绘制

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









