






 本文详细介绍了如何在Python环境下使用GPU加速TensorFlow模型,包括前置知识、安装步骤、CUDA与cuDNN的作用、以及常见问题如CUDA版本冲突和GPU未检测到的解决方案。
本文详细介绍了如何在Python环境下使用GPU加速TensorFlow模型,包括前置知识、安装步骤、CUDA与cuDNN的作用、以及常见问题如CUDA版本冲突和GPU未检测到的解决方案。
使用GPU运行TensorFlow模型的教程
使用GPU运行TensorFlow模型的教程
1. 前置知识介绍
1.1 为什么要使用GPU跑模型
优势
- 并行处理能力:GPU 设计用于高效地处理并行任务。由于机器学习和深度学习模型涉及大量的矩阵和向量运算,这些运算可以并行处理,因此 GPU 在这些任务中表现出色。
- 更快的计算速度:对于大规模的深度学习模型,GPU 可以显著加快训练时间。这是因为 GPU 拥有成千上万的小核心,可以同时执行大量的运算,而 CPU 通常只有几个核心。
- 适合复杂运算:深度学习模型,尤其是大型的神经网络,需要大量的复杂运算。GPU 的架构使其更适合这类计算密集型任务。
劣势
- 成本:高性能的 GPU 通常比 CPU 更昂贵。此外,使用 GPU 可能还需要更高成本的电源和冷却系统。
- 能耗:GPU 在运行时通常消耗更多电力,这会导致更高的运营成本。
- 编程复杂性:虽然许多深度学习框架(如 TensorFlow 和 PyTorch)简化了使用 GPU 的过程,但在某些情况下,优化 GPU 代码以获得最佳性能可能比 CPU 更复杂。
- 通用性:对于不涉及大量并行计算的任务,CPU 可能是更好的选择。CPU 通常更适合处理需要复杂逻辑和控制流的程序。
简单来说就是GPU的速度更快,效率更高,但是成本更高,配置起来有难度
1.2 TensorFlow库
TensorFlow 是一个由 Google Brain Team 开发的开源机器学习库,用于数据流编程。它是一个数学软件,特别适用于大规模机器学习。TensorFlow 最初是为了内部使用而开发的,后来在 2015 年被开源。自那以后,它已经成为机器学习和深度学习领域最流行的框架之一。以下是 TensorFlow 的一些关键特点:
- 多种用途:虽然 TensorFlow 最初是为了深度学习而设计的,但它也可以用于其他类型的机器学习算法。
- 灵活性:TensorFlow 允许开发者以 Python 等多种语言创建图模型,这些图模型是一系列可以在多个 CPU 或 GPU 上运行的计算操作。它支持从简单的线性回归到复杂的神经网络的各种算法。
- 可扩展性:TensorFlow 支持从笔记本电脑到大型服务器集群的不同计算平台。它可以在单个 CPU/GPU 上高效运行,也可以在多台机器和大型分布式系统上扩展。
- 强大的社区和支持:作为一个开源项目,TensorFlow 拥有一个活跃的社区,提供大量的教程、文档和新的研究成果。Google 也提供了强大的支持,包括定期更新和新功能。
- 集成工具:TensorFlow 配备了许多用于可视化(如 TensorBoard)、模型部署等的工具,以及与其他谷歌服务的集成,如 Google Cloud Platform。
- 应用广泛:TensorFlow 已被用于多种领域,包括语音和图像识别、自然语言处理、医学信息学、计算机视觉等。
- Keras 集成:Keras 是一个流行的高级神经网络 API,它被集成在 TensorFlow 中,提供了一种简单和快速的方式来构建和训练模型,使得 TensorFlow 对初学者更友好。
1.3 Anaconda
Anaconda是Python的包管理器和环境管理器,在网络上已经有很多安装的教程了,并且相对简单,在此教程中不再赘述
请读者在进行后续的配置前,先安装好Anaconda
1.4 CUDA和cuDNN
使用TensorFlow时,并不一定需要CUDA和cuDNN,这取决于你是否打算在NVIDIA的GPU上运行TensorFlow。下面是关于CUDA、cuDNN和它们与TensorFlow之间关系的详细解释:
CUDA
- 什么是CUDA? CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一个平行计算平台和API模型。它允许软件开发者和软件工程师使用NVIDIA GPU进行通用处理(也就是GPGPU,General-Purpose computing on Graphics Processing Units)。
- 为什么TensorFlow需要CUDA? 如果你想在GPU上运行TensorFlow以加速模型的训练和推理过程,那么就需要CUDA。TensorFlow的GPU支持利用CUDA作为底层来直接与NVIDIA的GPU硬件交互。
cuDNN
- 什么是cuDNN? cuDNN(CUDA Deep Neural Network library)是NVIDIA发布的一个用于深度神经网络的GPU加速库。它提供了高度优化的常用深度学习操作,比如卷积、池化等。
- 为什么TensorFlow需要cuDNN? 当你在使用TensorFlow进行深度学习任务,尤其是涉及到复杂神经网络结构时,cuDNN可以提供额外的优化和加速。TensorFlow在GPU上的许多操作都是通过调用cuDNN库实现的。
关联和使用场景
- 只用CPU:如果你只打算使用CPU运行TensorFlow,那么不需要安装CUDA和cuDNN。
- 用GPU:如果你打算使用NVIDIA GPU,那么需要安装CUDA和cuDNN,因为TensorFlow的GPU支持依赖于这两个库来实现高效的计算。(本教程使用的是GPU,所以需要安装,后续有涉及相关的教程)
1.5 Pycharm和Jupyter
两个都是集成开发环境(IDE),如何在这两个IDE中使用Pycharm本教程都会有所涉及
2. 前期准备工作
在这一部分中,主要要做以下两件事:
- 查看自己电脑的环境配置(Tensorflow-gpu,Python,cuda,cuDNN)
- 安装对应版本的软件
下面进入正式的教程:
-
首先查看自己电脑的GPU
右键
此电脑→右键选管理→设备管理器→显示适配器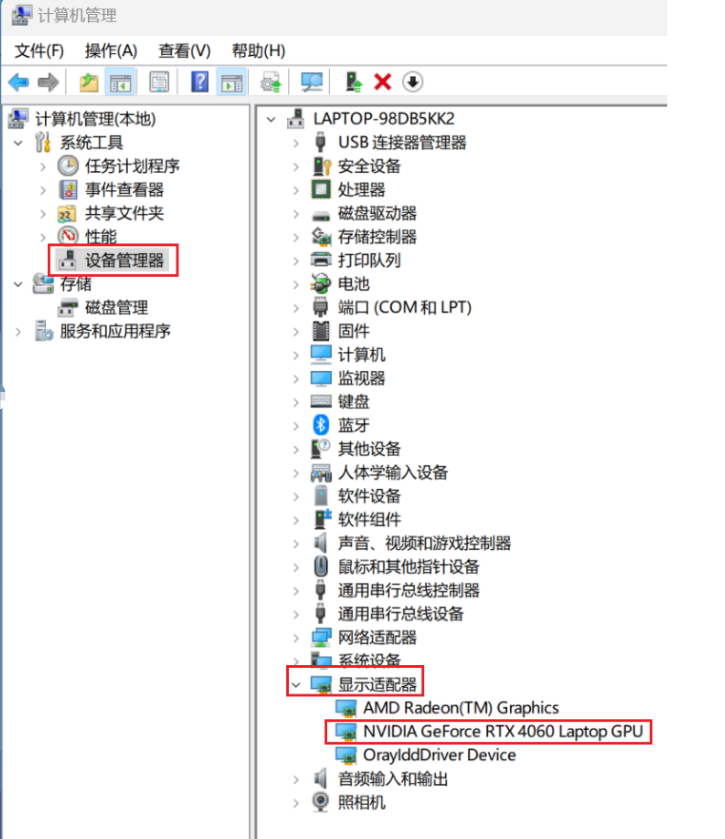
看有没有独显,比如笔者的是
NVIDIA GeForce RTX 4060 -
可在下面网站中查看自己电脑显卡的相应算力,太低的不建议安装(最好>=5.0)
https://developer.nvidia.com/cuda-gpus
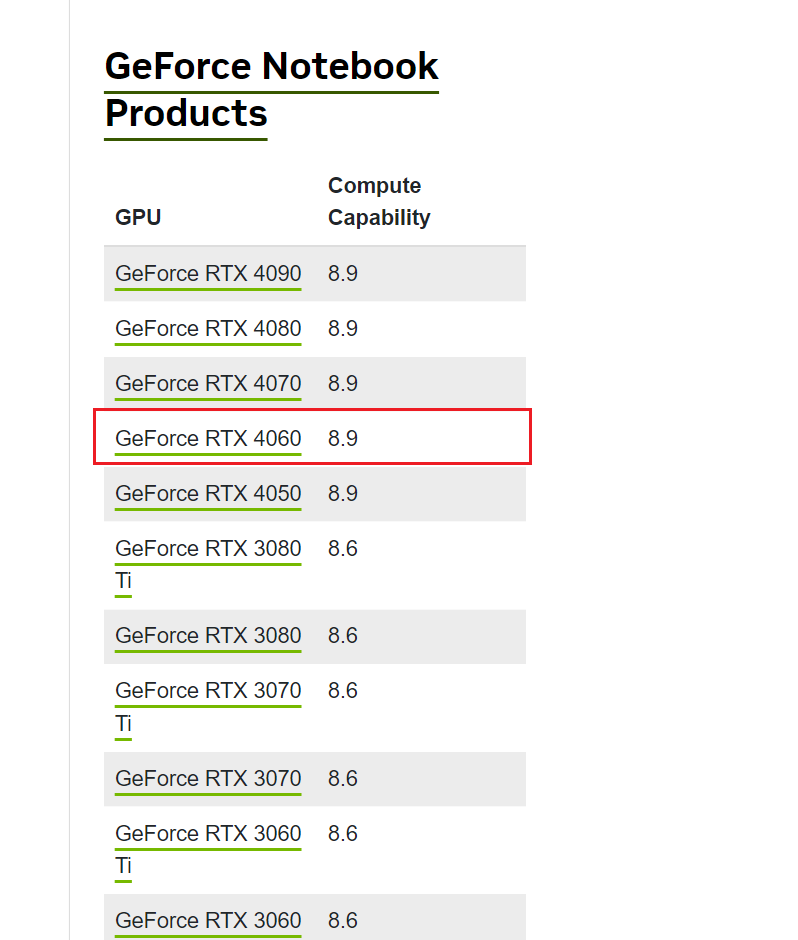
如果对显卡性能感兴趣的读者可以参考该链接 深度学习GPU显卡选型攻略
-
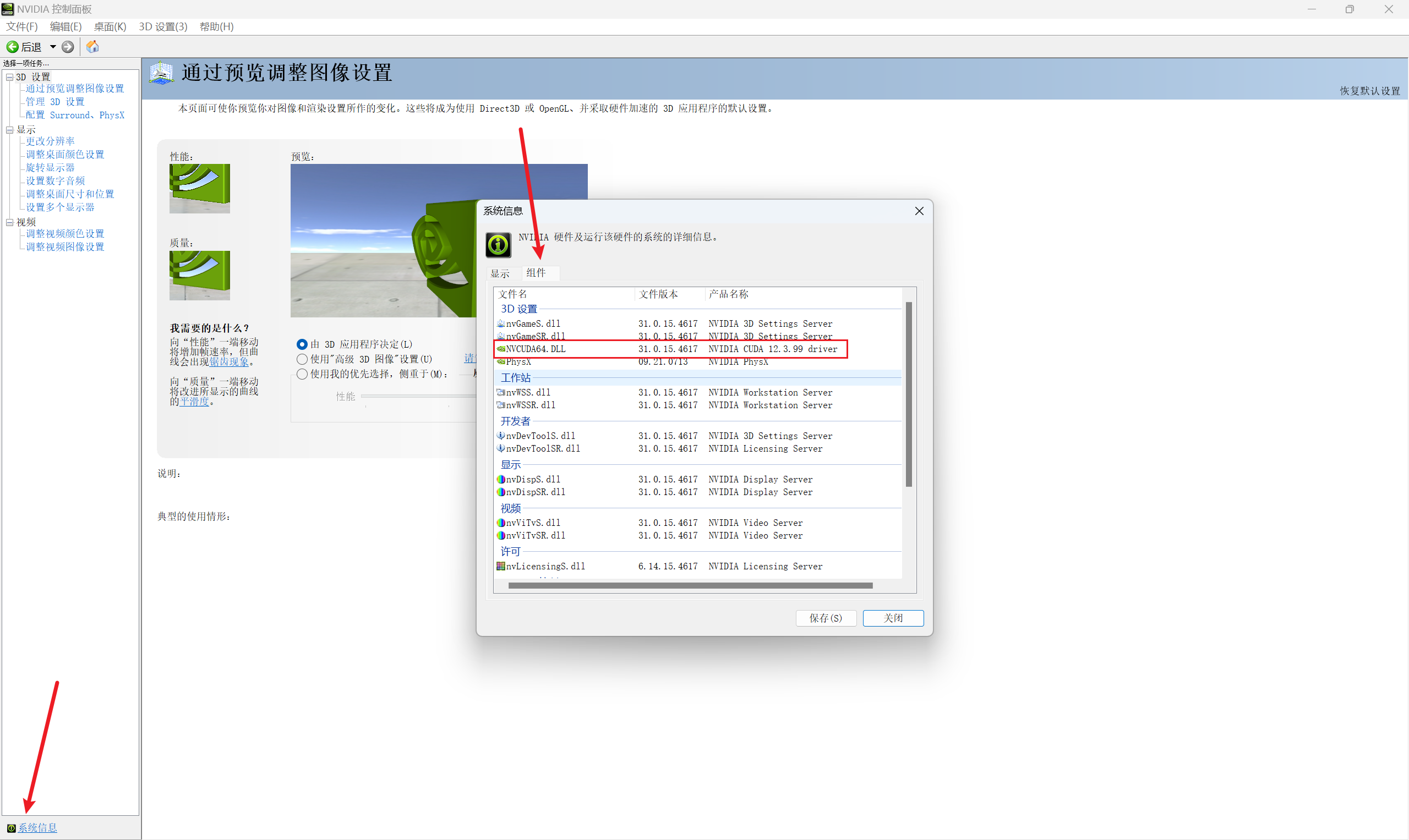
查看相关的显卡驱动,以及最高支持的CUDA版本
- 可以在NVIDIA控制面板查看
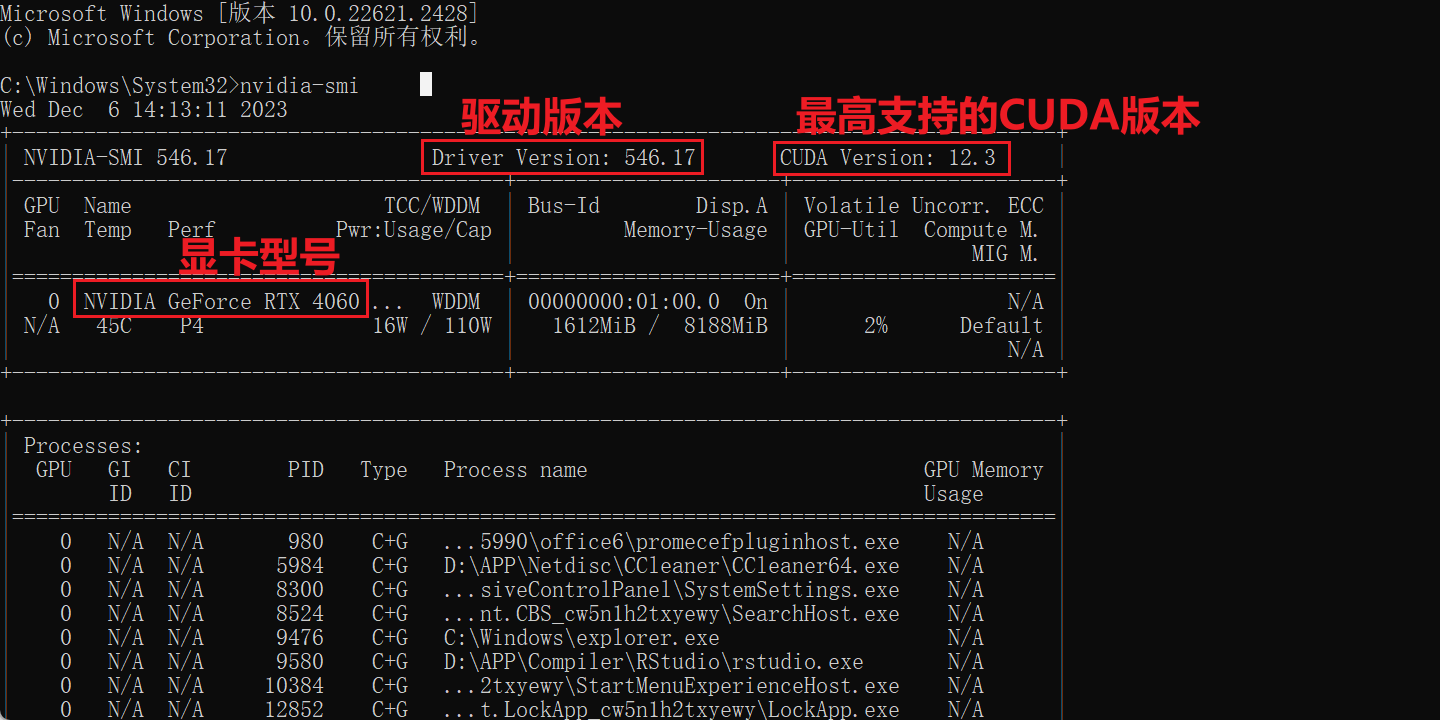
- 也可以在cmd中输入
nvidia-smi查看相关信息
3. 正式安装
-
查看相应版本关系(最重要!!!)
来到官网选择想对应的版本,一定要匹配,按照官方文档一一对应(注意还要切换为英文,中文的参考不完整)
下面是笔者的环境和选择安装的版本:

| 环境/系统信息 | 描述 |
|---|---|
| 操作系统 | win11 |
| 显卡 | NVIDIA GeForce RTX4060 |
| Python | 3.8.18 |
| tensorflow-gpu | 2.10.0 |
| cuda | 11.2 |
| cuDNN | 8.1 |
-
根据选择的版本去下载相应的cuda和cuDNN,可参考以下链接
CUDA、CUDNN在windows下的安装及配置_配置cudnn-CSDN博客
cuda下载地址:CUDA Toolkit Archive | NVIDIA Developer;
cudnn下载地址:cuDNN Archive | NVIDIA Developer。
请验证完毕后再进行后续的操作,没有这两个会导致tensorflow检测不到可用GPU的问题
运行
nvcc --version检查是否成功安装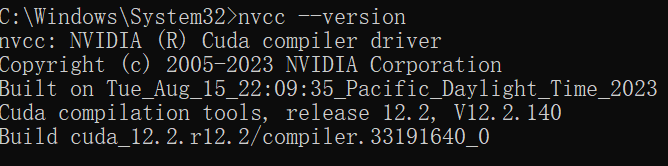
如何验证是否安装完成:
在该目录下C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite分别执行
.\bandwidthTest.exe,.\deviceQuery.exe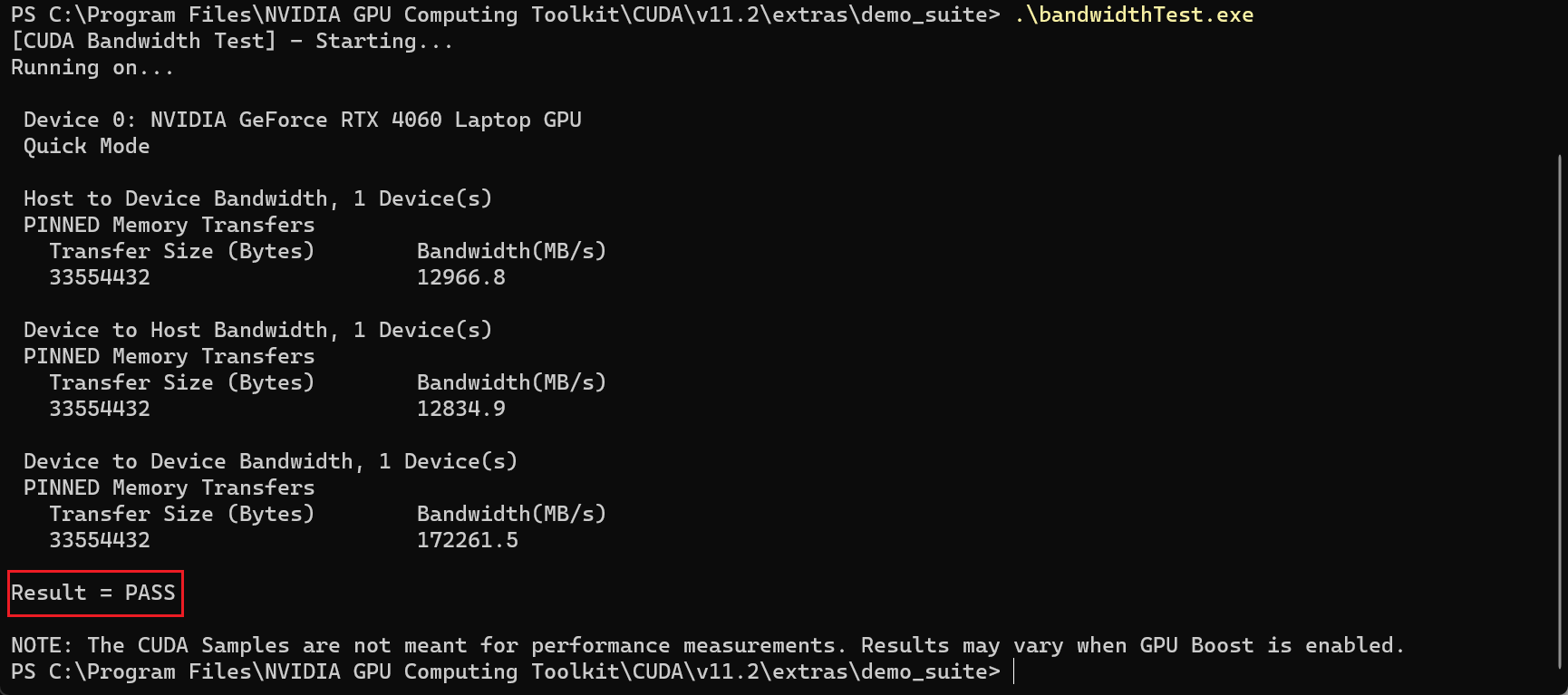
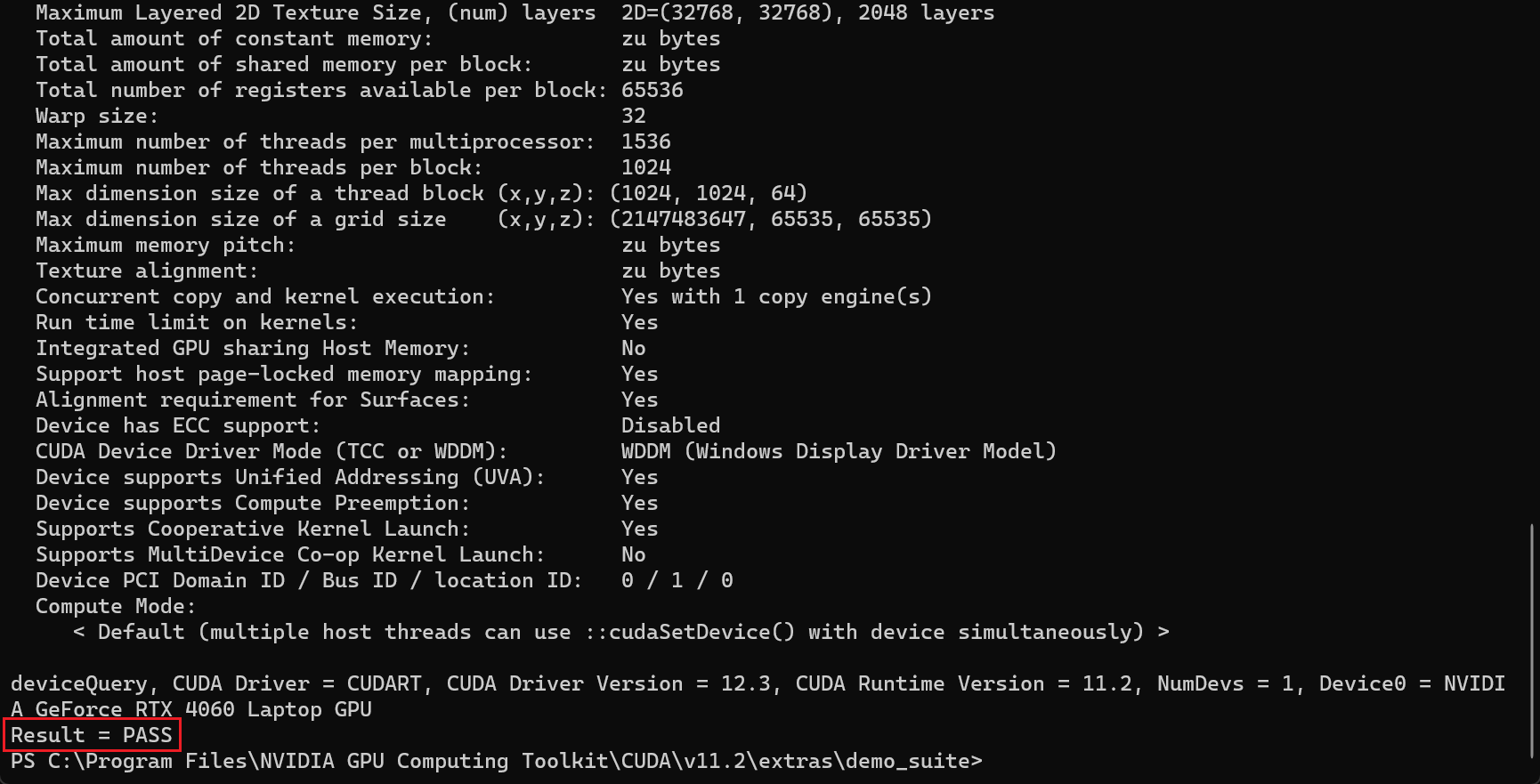
如果
Result都为PASS的话则配置成功 -
打开Anaconda prompt
3.1) 直接以管理员身份运行
3.2) 创建新的环境,名字叫test,指定python版本为
(如果不希望环境创建在C盘,可参考w11下载anaconda在d盘,新建的虚拟环境总是在c盘怎么解决)
3.8.18
conda create -n test python=3.8.18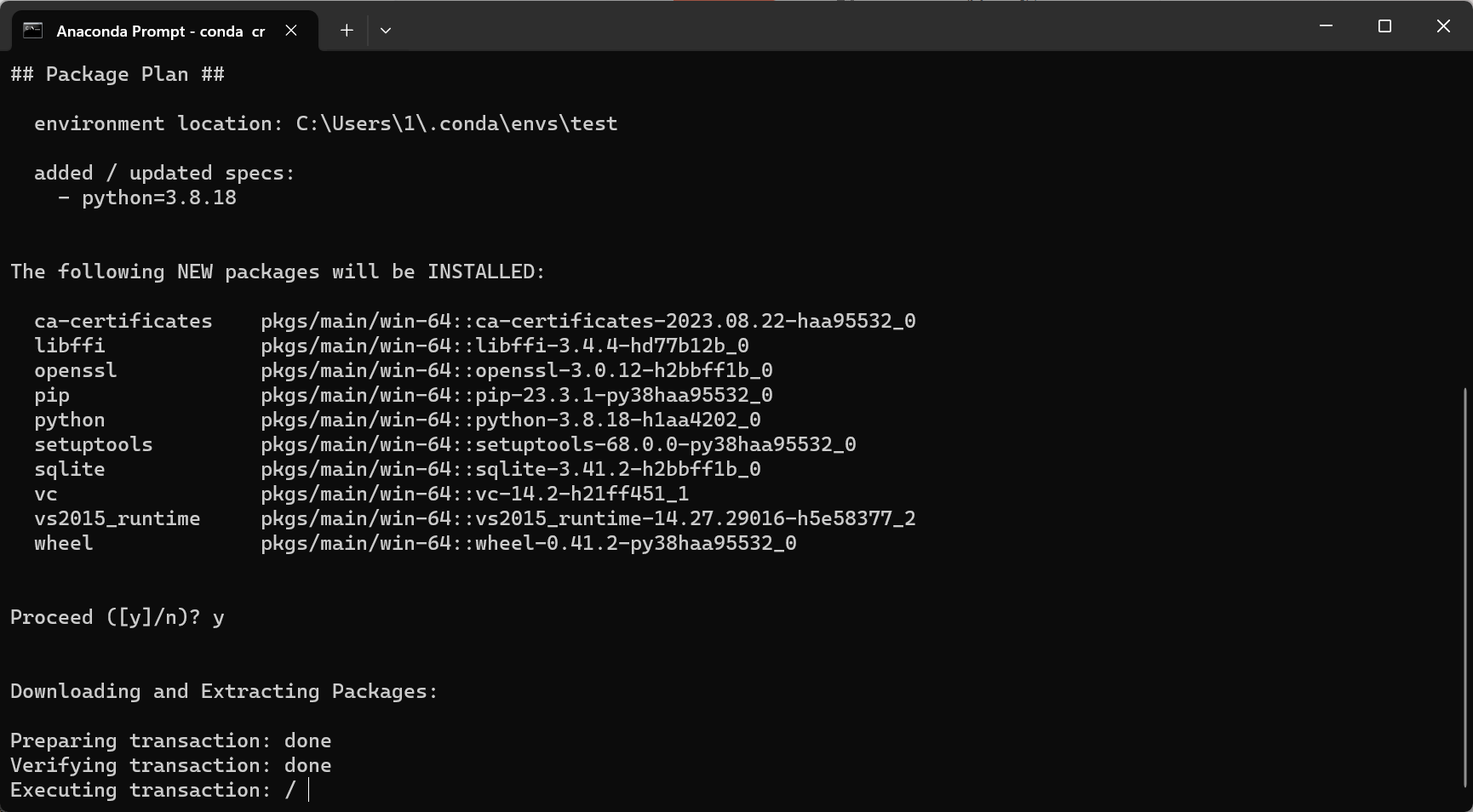
等他跳完,像下面这样就可以了
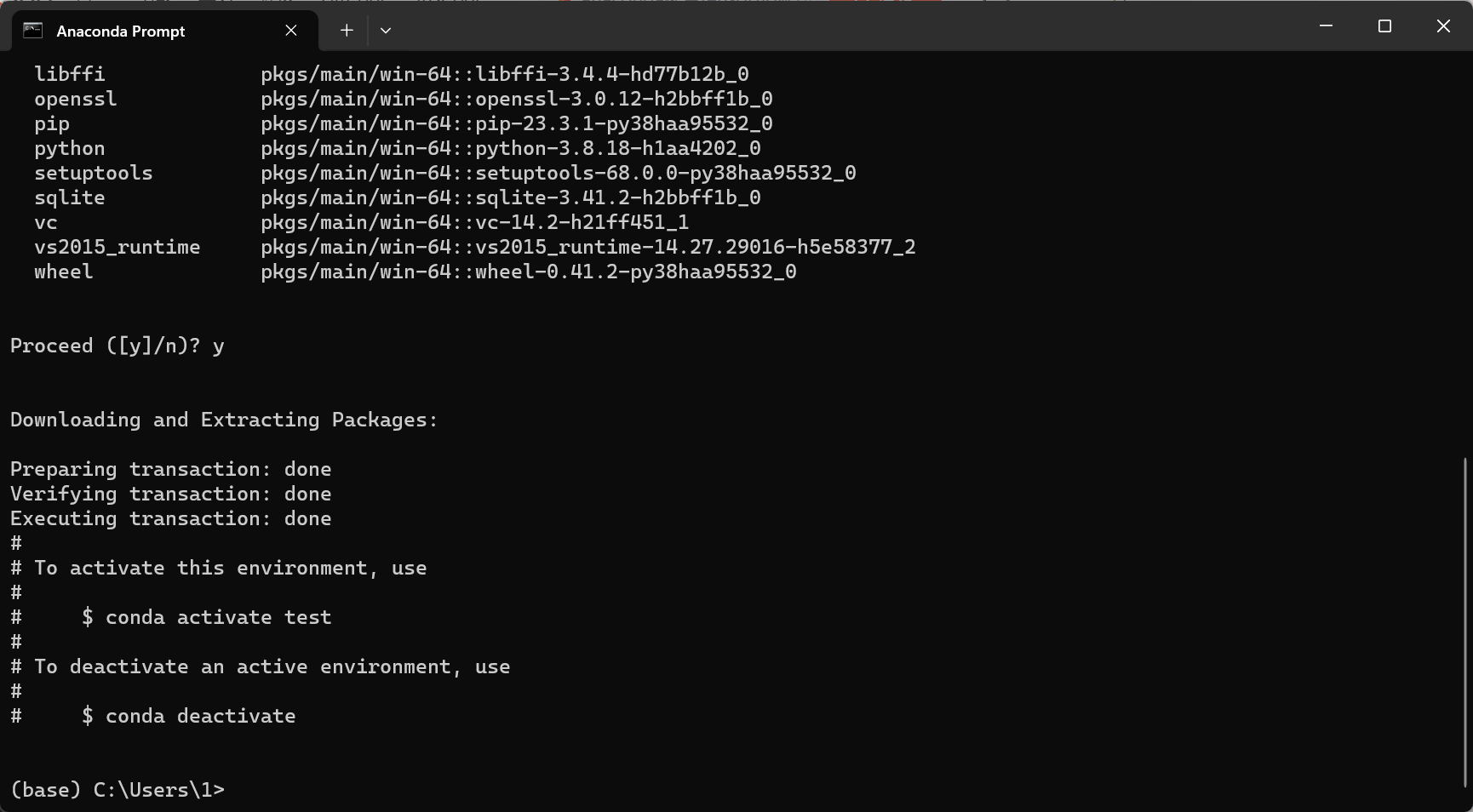
3.3) 进入该环境
conda activate test,使用pip进行下载pip install tensorflow-gpu==2.10.0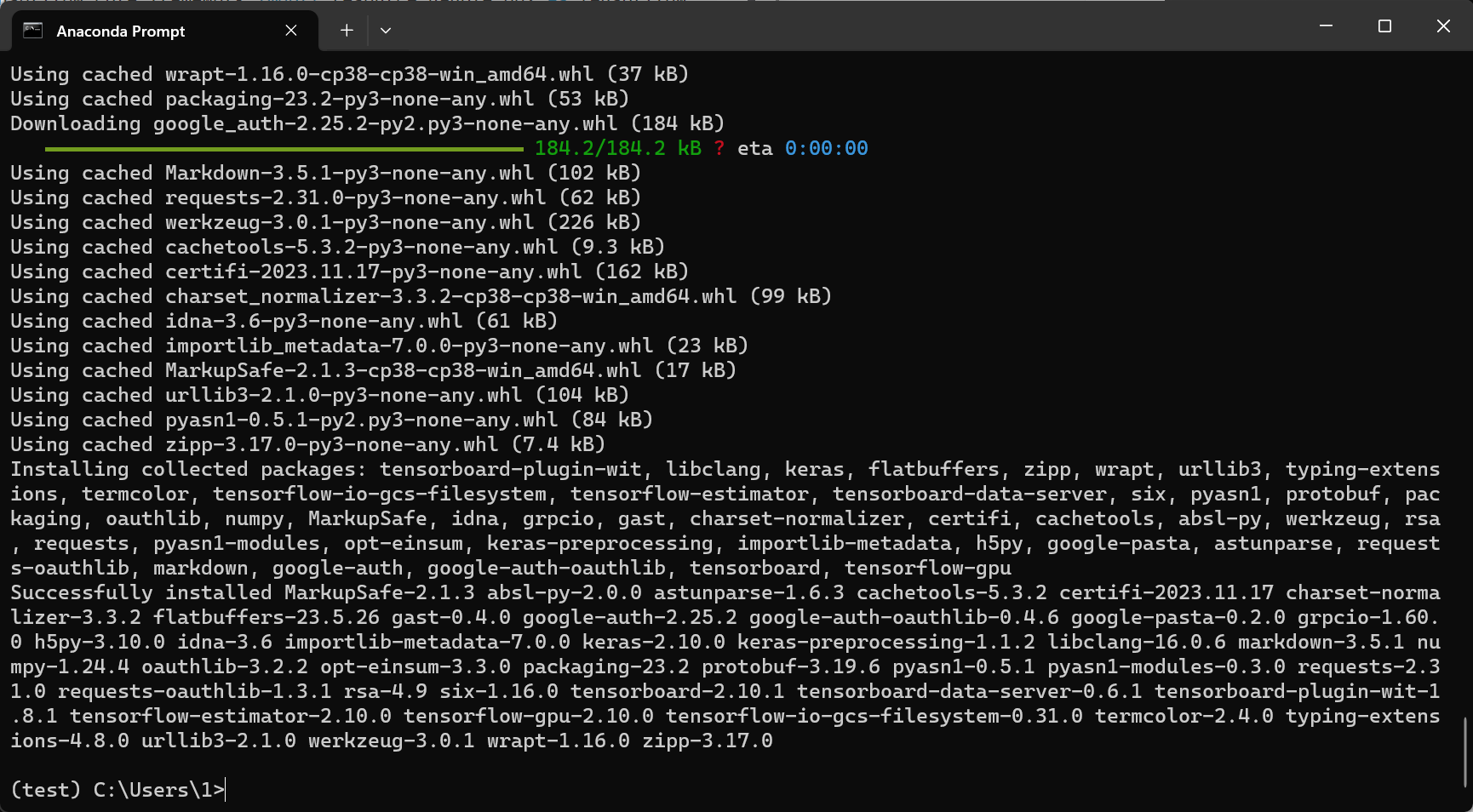
3.4) 进入python,输入以下代码
import tensorflow as tf tf.__version__
如成功显示版本则说明配置成功
3.5) 退出环境
conda deactivate
4. 测试 Tensorflow-gpu 是否安装成功
- pycharm
按如图切换Pycharm的相应配置
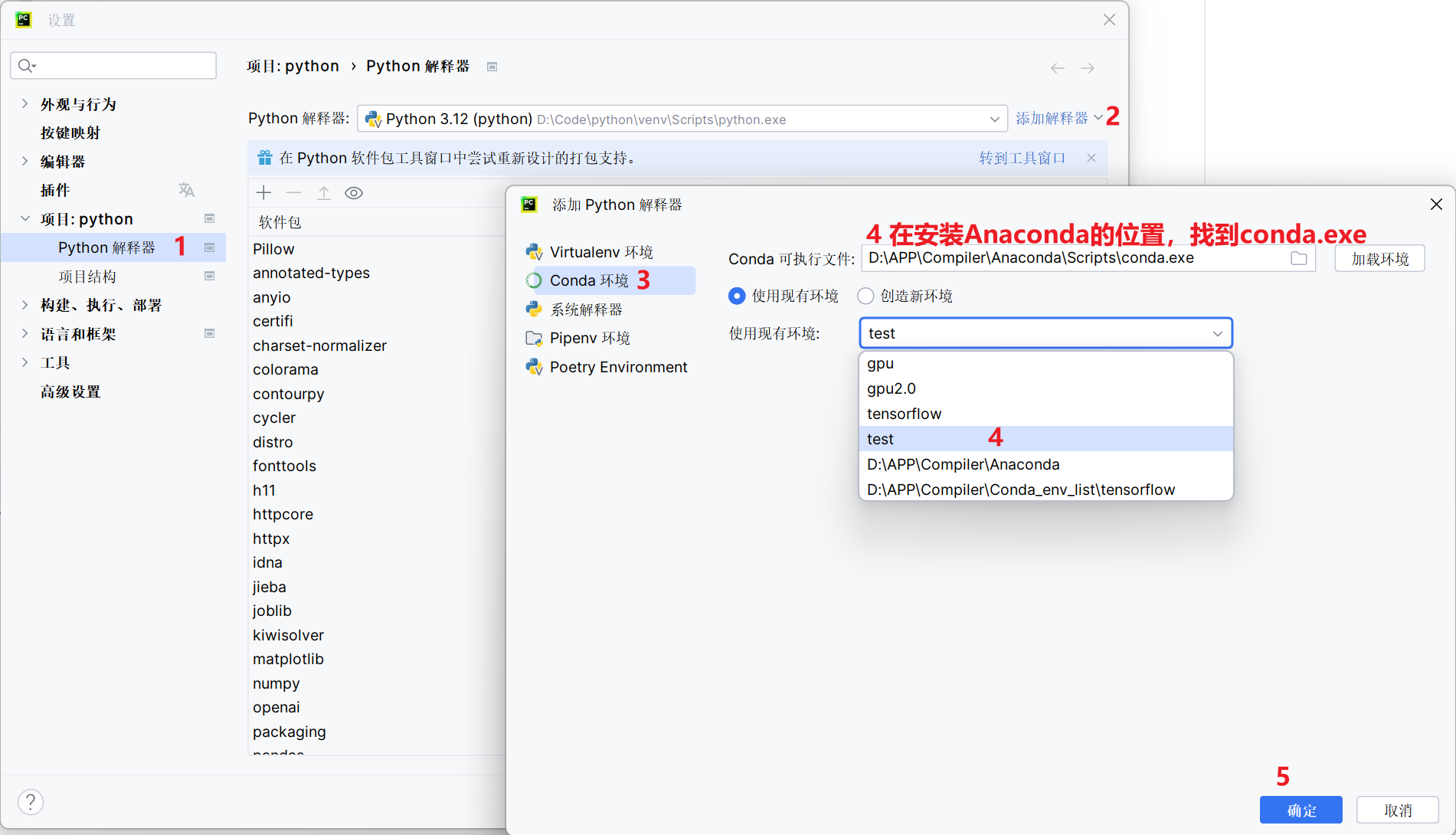
输入以下代码:
import tensorflow as tf
print(tf.__version__)
print(tf.test.gpu_device_name())
print(tf.config.experimental.set_visible_devices)
print('GPU:', tf.config.list_physical_devices('GPU'))
print('CPU:', tf.config.list_physical_devices(device_type='CPU'))
print(tf.config.list_physical_devices('GPU'))
print(tf.test.is_gpu_available())
# 输出可用的GPU数量
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
# 查询GPU设备
若显示True和相应的可用数量,则配置成功

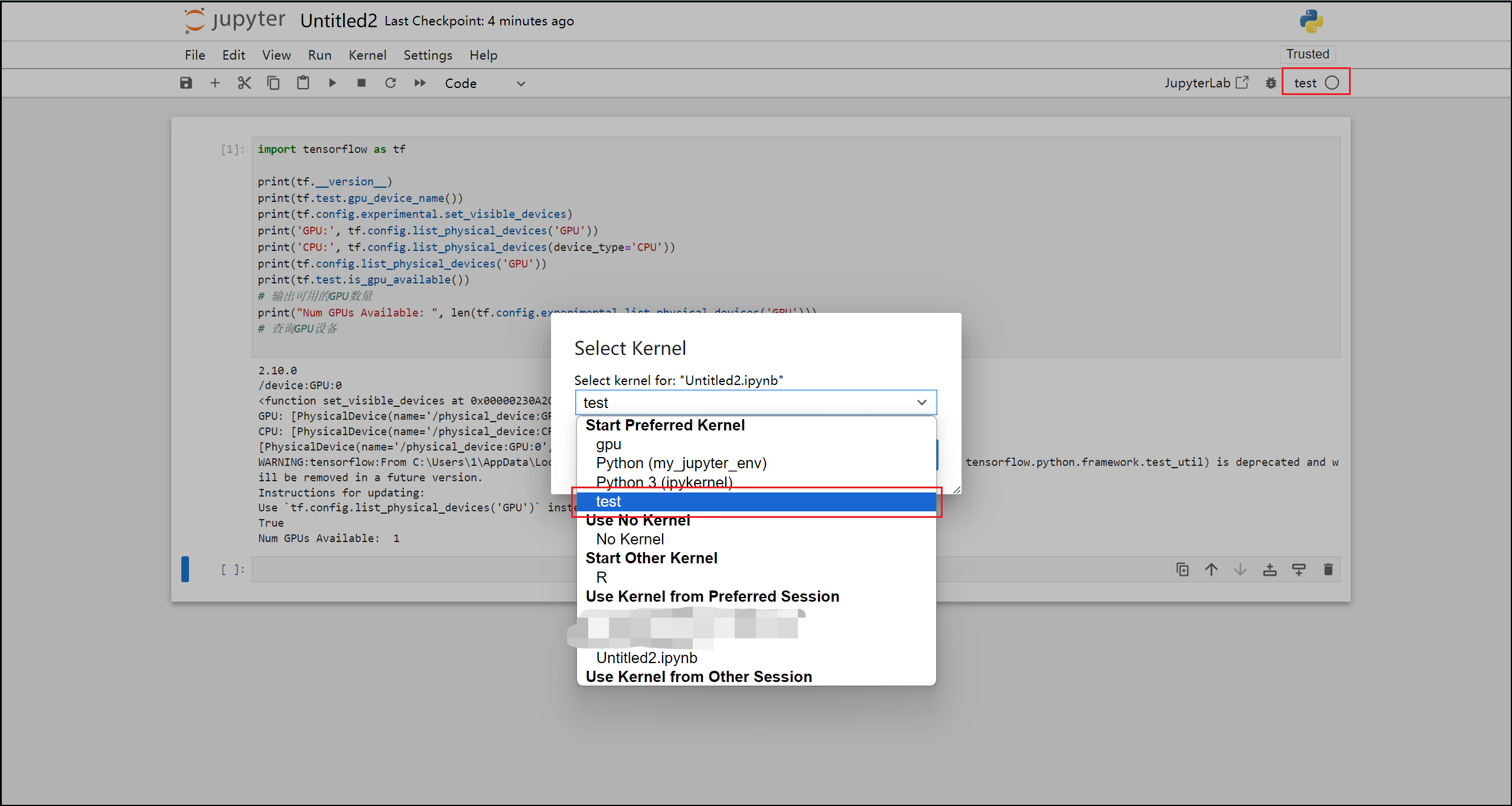
- Jupyter notebook
首先需要添加相应的内核:
python -m ipykernel install --user --name=test --display-name test
--name=test:这指定了新内核的名称。在这个例子中,内核被命名为test。这个名字是在Jupyter Notebook中选择内核时看到的名称。
--display-name "test":这指定了内核在Jupyter Notebook界面中显示的名称。在这个例子中,显示名称也设置为"test"。
图片显示内容来自于conda install nb_conda失败原因
切换相应内核,查看代码输出
5. 其他报错及解决方案
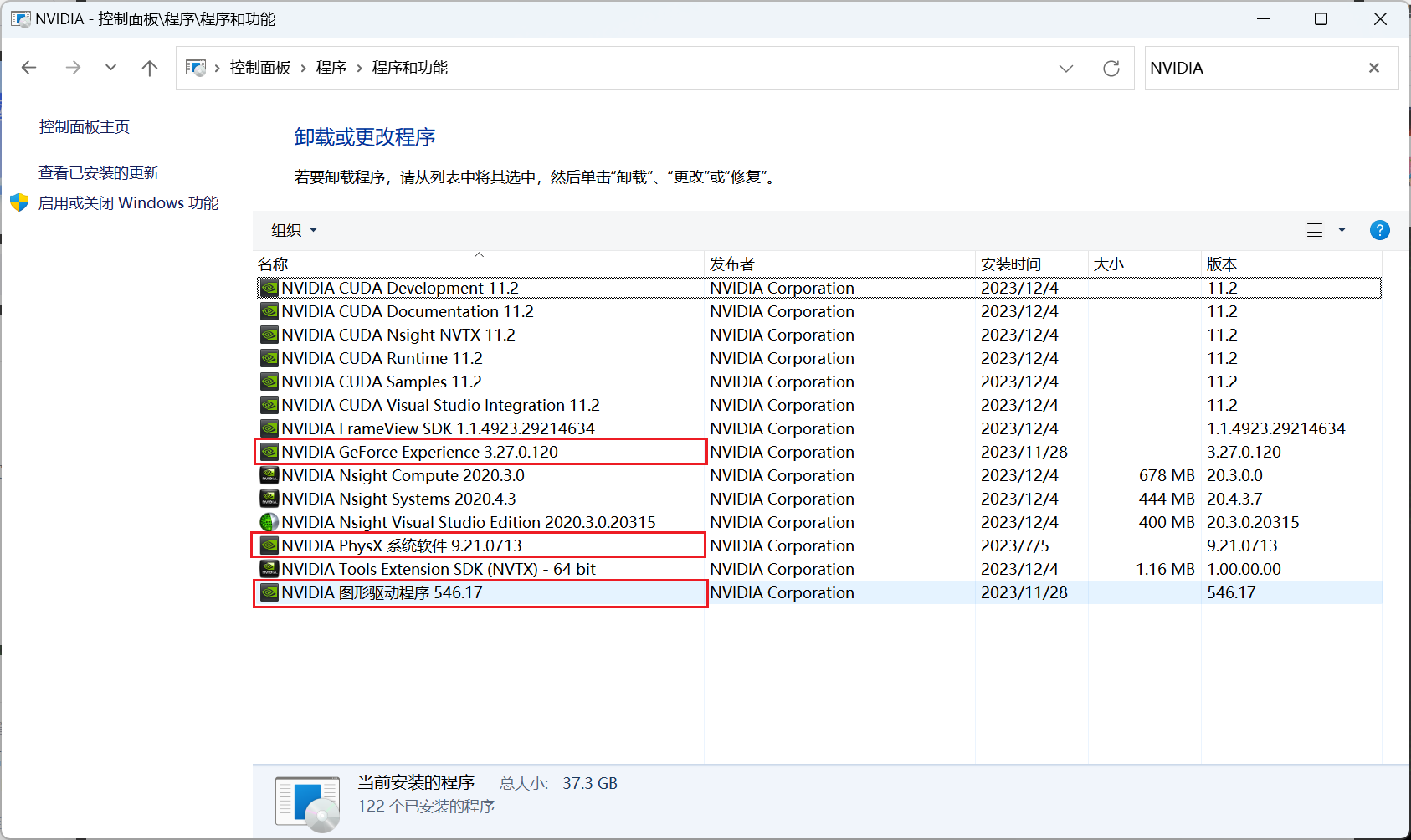
CUDA版本冲突
如果之前下载了新版本的CUDA,后面又想下载老版本的CUDA,在安装时发生了冲突,则需要先卸载新版本的CUDA
(只保留框出来的这几个就可以)
Conda无法下载
如图这是代理问题,关闭电脑的代理即可

可用GPU数量为0
- 未正确安装CUDA或cuDNN(尝试重新下载安装)
- 未正确配置环境变量(检查环境变量数量和路径)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









