






第一步 :确认数据位置 通过谷歌浏览器自带的开发者工具,查找数据
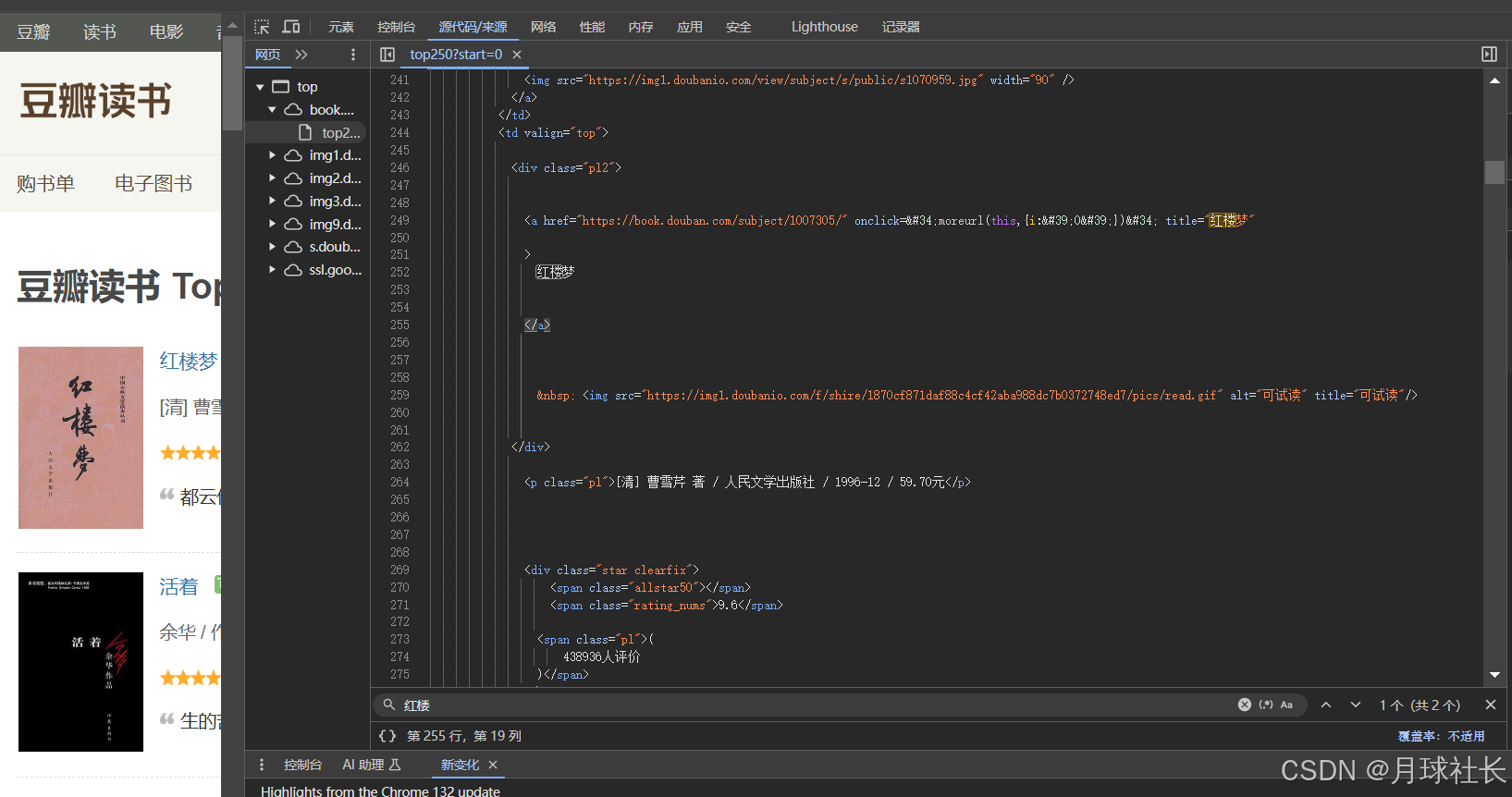
通过这样的方法,可以发现页面中存在的数据有:
中国作品:作者 书名 出版社 价格 等数据
而对于外国作品 则多出译者类型的数据
第二步:了解数据类型和数据所在位置后,可以发现数据就在页面的原代码中,所以使用python中的requests库进行网络请求,获取源代码。
下载并导入requests模块:
# 下载模块
pip install requests
# 导入模块
import requestsimport requests
url = 'https://book.douban.com/top250'
response = requests.get(url)
yuan_dai_ma = response.text
print(yuan_dai_ma)运行代码:发现并不能获取到页面原代码,简单的思路是网站具有一定的反爬机制,可以在请求时携带请求头来反反爬。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/58.0.3029.110 Safari/537.3',
} # 请求头在请求头中加入设备验证,伪装成正常设备,成功获取到网页源代码。
第三步:通过网页源代码解析数据
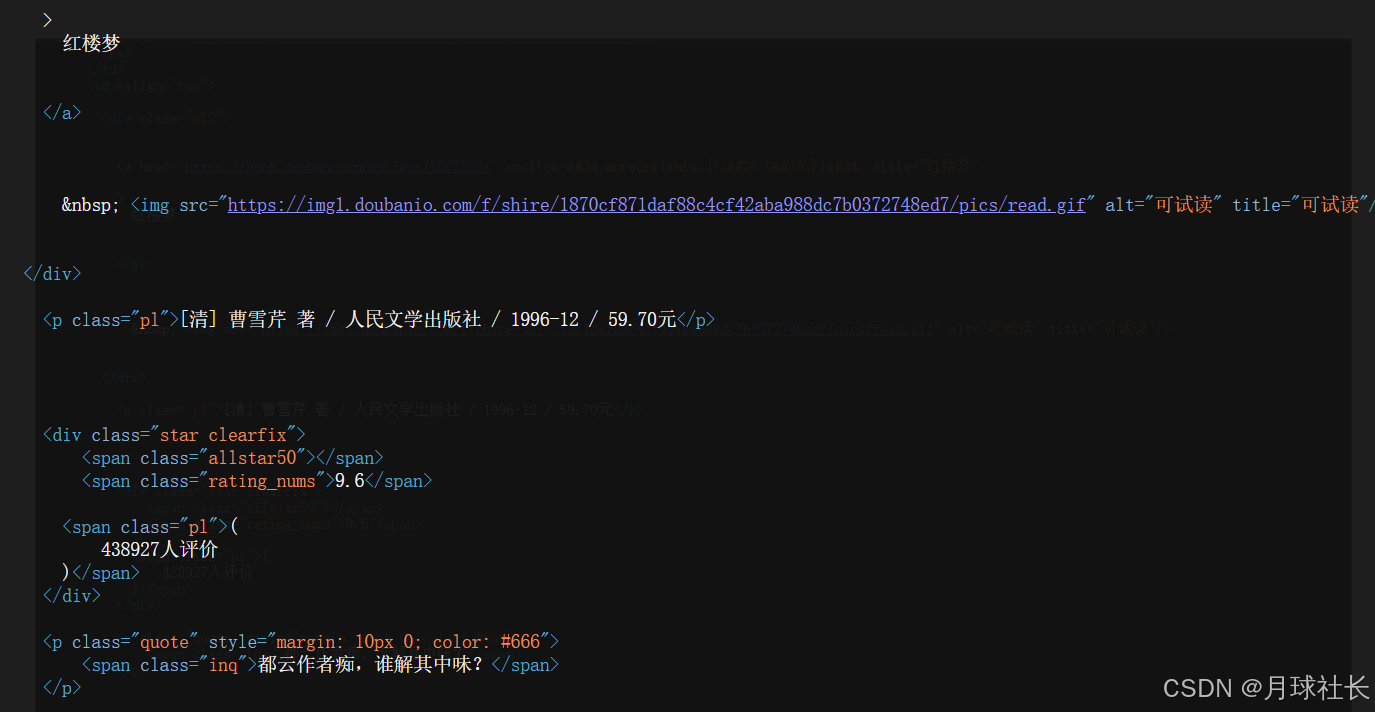
以上是红楼梦的数据,而每本书的格式都相同,这里使用正则表达式解析
首先,要想在python中使用正则表达式,首先需要导入re模块,可以通过终端下载
# 下载模块
pip install re
#导入模块
import re通过简单的正则表达是匹配,创建一个匹配逻辑
obj1 = re.compile(
r'title="(?P<name>.*?)"' # 匹配标题
r'.*?<p class="pl">(?P<shuju>.*?)</p>' # 匹配数据
r'.*?<span class="pl">(?P<renshu>.*?)</span>' # 匹配评价人数
r'.*?<span class="inq">(?P<mingju>.*?)</span>', # 匹配名句
re.S
)但这里需要注意的是 对于shuju来说 它并非单一数据,通过上图的源代码片段可知
shuju 应该包括作者,出版社,出版时间,价格 ,一共是四项(对于外国作品(作者,译者,出版社,出版时间,价格),一共是五项),明确这个,在之后数据的遍历时会更加清晰
results = obj1.finditer(yuan_dai_ma) # 匹配结果
finaal_lst = [] # 存储数据的列表
for result in results: # 遍历匹配结果
name = result.group('name') # 获取书名
shuju = result.group('shuju') # 获取数据
shuju = shuju.split('/') # 分割数据 拿到作者 译者 出版社 出版时间 价格
renshu = result.group('renshu').strip() # 获取评价人数
mingju = result.group('mingju').strip() # 获取名句
if len(shuju) == 4 : # 判断数据长度
author = shuju[0].strip() # 获取作者
chu_ban_she = shuju[1].strip() # 获取出版社
date = shuju[2].strip() # 获取出版时间
price = shuju[3].strip() # 获取价格
dic = { # 存储数据
'name': name,
'author': author,
'chu_ban_she': chu_ban_she,
'date': date,
'price': price,
'renshu': renshu,
'mingju': mingju
}
finaal_lst.append(dic) # 添加到列表
elif len(shuju) == 5: # 判断数据长度
author = shuju[0].strip() # 获取作者
yizhe = shuju[1].strip() # 获取译者
chu_ban_she = shuju[2].strip() # 获取出版社
date = shuju[3].strip() # 获取出版时间
price = shuju[4].strip() # 获取价格
dic = { # 存储数据
'name': name,
'author': author,
'yizhe': yizhe,
'chu_ban_she': chu_ban_she,
'date': date,
'price': price,
'renshu': renshu,
'mingju': mingju
}
finaal_lst.append(dic) # 添加到列表
# print(finaal_lst)
return finaal_lst # 返回数据列表创建一个函数用于数据的获取,并进行数据的解析,最后将数据整理为列表并发送数据
第四步:通过的到的数据进行存储、
(1). 存储到mySQL数据库中
def shuju_mysql(): # 存储数据 到mysql数据库
try : # 异常处理
connect = pymysql.connect( # 连接数据库
host='localhost', # 按照个人配置 修改
password='1234',
database='python数据库',
port=3306,
user='root'
)
cur = connect.cursor() # 创建游标
for i in range(0,10): # 遍历页数
final_lst = get_page_content(i) # 获取数据
sql = '''
insert into 豆瓣读书250(`序号`,`书名`,`作者`,`译者`,`出版社`,`出版时间`,`价格`,`名句`) values(%s,%s,%s,%s,%s,%s,%s,%s)
''' # sql语句 需要提前按sql 语句创建表
for j in range(len(final_lst)): # 遍历数据
cur.execute(sql,(None,final_lst[j]['name'],final_lst[j]['author'],final_lst[j].get('yizhe',''),final_lst[j]['chu_ban_she'],final_lst[j]['date'],final_lst[j]['price'],final_lst[j]['mingju'])) # 执行sql语句
connect.commit() # 提交
cur.close() # 关闭游标
connect.close() # 关闭连接
except Exception as e: # 异常处理
print(e) # 打印异常
connect.rollback() # 回滚
print('存储成功到mysql数据库') # 提示存储成功(2). 存储到csv或者txt文件中
def shuju_txt_csv(mode='txt'): # 存储数据到txt文件
if mode == 'txt': # 判断模式
with open('/豆瓣读书top250.txt','w',encoding='utf-8') as f:
try :
for i in range(0,10):
final_lst = get_page_content(i) # 获取数据
for j in range(len(final_lst)):
f.write(f'{final_lst[j]['name']},{final_lst[j]['author']},{final_lst[j].get('yizhe','')},{final_lst[j]['chu_ban_she']},{final_lst[j]['date']},{final_lst[j]['price']},{final_lst[j]['mingju']}\n')# 写入数据
except Exception as e:
print(e)
print('存储成功到txt文件')
elif mode == 'csv': # 判断模式
with open('豆瓣读书top250.csv','w',encoding='utf-8') as f:
try :
for i in range(0,10):
final_lst = get_page_content(i) # 获取数据
for j in range(len(final_lst)):
f.write(f'{final_lst[j]['name']},{final_lst[j]['author']},{final_lst[j].get('yizhe','')},{final_lst[j]['chu_ban_she']},{final_lst[j]['date']},{final_lst[j]['price']},{final_lst[j]['mingju']}\n')# 写入数据
except Exception as e:
print(e)
print('存储成功到csv文件')以下为完整的代码:
"""
项目名称:豆瓣读书 Top250 爬虫
作者:月球社长
邮箱: yyyygggg15@126.com
时间: 2025-2-14
禁止用于非法用途
"""
import requests
import re
import pymysql
# 导入必须的模块
def get_page_content(page): # 获取页面内容
url = 'https://book.douban.com/top250' + '?start=' + str(page * 25) # 拼接url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
} # 请求头
response = requests.get(url,headers=headers) # 发送请求
# print(response.text)
yuan_dai_ma = response.text # 获取源代码
obj1 = re.compile(
r'title="(?P<name>.*?)"' # 匹配标题
r'.*?<p class="pl">(?P<shuju>.*?)</p>' # 匹配数据
r'.*?<span class="pl">(?P<renshu>.*?)</span>' # 匹配评价人数
r'.*?<span class="inq">(?P<mingju>.*?)</span>', # 匹配名句
re.S
)
results = obj1.finditer(yuan_dai_ma) # 匹配结果
finaal_lst = [] # 存储数据的列表
for result in results: # 遍历匹配结果
name = result.group('name') # 获取书名
shuju = result.group('shuju') # 获取数据
shuju = shuju.split('/') # 分割数据 拿到作者 译者 出版社 出版时间 价格
renshu = result.group('renshu').strip() # 获取评价人数
mingju = result.group('mingju').strip() # 获取名句
if len(shuju) == 4 : # 判断数据长度
author = shuju[0].strip() # 获取作者
chu_ban_she = shuju[1].strip() # 获取出版社
date = shuju[2].strip() # 获取出版时间
price = shuju[3].strip() # 获取价格
dic = { # 存储数据
'name': name,
'author': author,
'chu_ban_she': chu_ban_she,
'date': date,
'price': price,
'renshu': renshu,
'mingju': mingju
}
finaal_lst.append(dic) # 添加到列表
elif len(shuju) == 5: # 判断数据长度
author = shuju[0].strip() # 获取作者
yizhe = shuju[1].strip() # 获取译者
chu_ban_she = shuju[2].strip() # 获取出版社
date = shuju[3].strip() # 获取出版时间
price = shuju[4].strip() # 获取价格
dic = { # 存储数据
'name': name,
'author': author,
'yizhe': yizhe,
'chu_ban_she': chu_ban_she,
'date': date,
'price': price,
'renshu': renshu,
'mingju': mingju
}
finaal_lst.append(dic) # 添加到列表
# print(finaal_lst)
return finaal_lst # 返回数据列表
def shuju_mysql(): # 存储数据 到mysql数据库
try : # 异常处理
connect = pymysql.connect( # 连接数据库
host='localhost', # 按照个人配置 修改
password='1234',
database='python数据库',
port=3306,
user='root'
)
cur = connect.cursor() # 创建游标
for i in range(0,10): # 遍历页数
final_lst = get_page_content(i) # 获取数据
sql = '''
insert into 豆瓣读书250(`序号`,`书名`,`作者`,`译者`,`出版社`,`出版时间`,`价格`,`名句`) values(%s,%s,%s,%s,%s,%s,%s,%s)
''' # sql语句 需要提前按sql 语句创建表
for j in range(len(final_lst)): # 遍历数据
cur.execute(sql,(None,final_lst[j]['name'],final_lst[j]['author'],final_lst[j].get('yizhe',''),final_lst[j]['chu_ban_she'],final_lst[j]['date'],final_lst[j]['price'],final_lst[j]['mingju'])) # 执行sql语句
connect.commit() # 提交
cur.close() # 关闭游标
connect.close() # 关闭连接
except Exception as e: # 异常处理
print(e) # 打印异常
connect.rollback() # 回滚
print('存储成功到mysql数据库') # 提示存储成功
def shuju_txt_csv(mode='txt'): # 存储数据到txt文件
if mode == 'txt': # 判断模式
with open('/豆瓣读书top250.txt','w',encoding='utf-8') as f:
try :
for i in range(0,10):
final_lst = get_page_content(i) # 获取数据
for j in range(len(final_lst)):
f.write(f'{final_lst[j]['name']},{final_lst[j]['author']},{final_lst[j].get('yizhe','')},{final_lst[j]['chu_ban_she']},{final_lst[j]['date']},{final_lst[j]['price']},{final_lst[j]['mingju']}\n')# 写入数据
except Exception as e:
print(e)
print('存储成功到txt文件')
elif mode == 'csv': # 判断模式
with open('豆瓣读书top250.csv','w',encoding='utf-8') as f:
try :
for i in range(0,10):
final_lst = get_page_content(i) # 获取数据
for j in range(len(final_lst)):
f.write(f'{final_lst[j]['name']},{final_lst[j]['author']},{final_lst[j].get('yizhe','')},{final_lst[j]['chu_ban_she']},{final_lst[j]['date']},{final_lst[j]['price']},{final_lst[j]['mingju']}\n')# 写入数据
except Exception as e:
print(e)
print('存储成功到csv文件')
# 使用方法 如果要存储csv文件或txt文件 请调用 shuju_txt_csv() 函数 需要提交参数 mode='csv' 或者 mode='txt',默认为txt
# 如果要存储到mysql数据库 请调用 shuju_mysql() 函数 需要提前按照sql语句创建表,并修改数据库配置
# shuju_txt_csv() # 调用存储函数 存储数据到txt文件或者csv文件
# shuju_mysql() # 调用存储函数 存储数据到mysql数据库感谢阅读!!!!

















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









