










大家好,今天,我要向大家介绍四个个免费的ComfyUI工作流网络,非常适合初学者使用。
ComfyUI是一个基于节点的稳定扩散AI绘图工具,它提供了一个用户友好的Web界面。它类似于Substance Designer,通过将扩散过程分解成多个节点,使得用户能够定制自己的工作流程,提高可重复性。虽然这种基于节点的工作流可能需要一些时间来学习,但ComfyUI的内部流程已经过优化,可以提高图片生成速度10%到25%,具体取决于显卡类型。
ComfyUI在处理大型图像时表现稳定,不会因为显存不足而崩溃,但可能会因为分块处理导致图像出现一些碎片。该工具支持基于图形、节点和流程图的界面设计,能够执行高级的稳定扩散管道
1.OPENart flow (https://openart.ai/home)
首先,如果你会魔法,那就直接用这个OPENart flow
这个是个老牌的workflow网站,
进来直接点击这个comfyui workflows
可以看到这里都是免费的工作流。
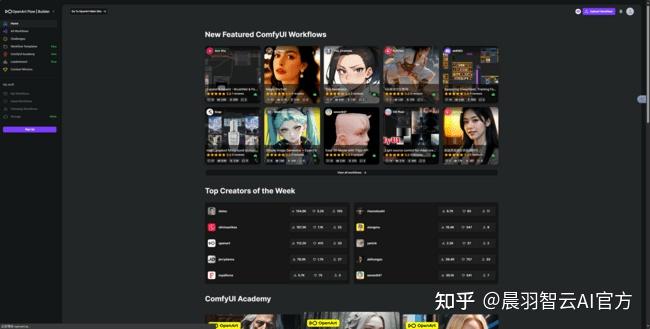
2.Comfy Workflows(https://comfyworkflows.com)
第二个Comfy Workflows,
一个你不需要魔法就能使用的网站,
这里都是免费的工作流
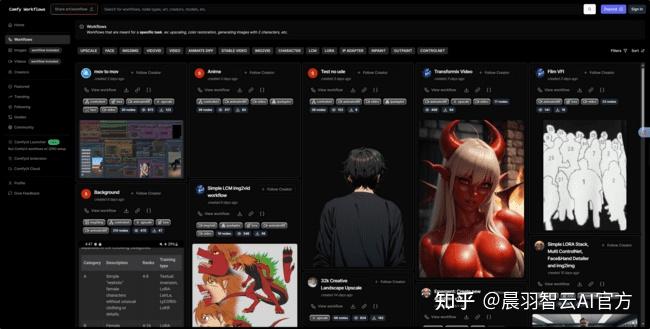
以上的两个国外网站看自己的情况选择就可以了,
资源都是很丰富的。
3.civital(https://civitai.com)
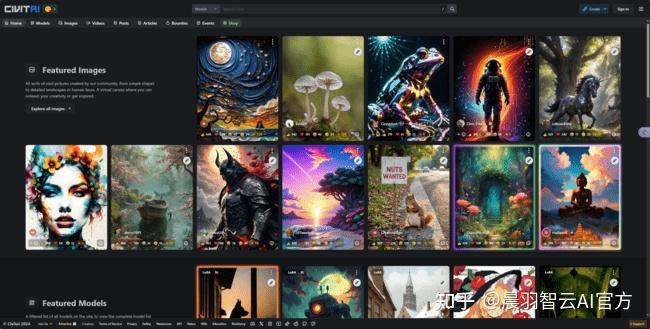
第三个,civital ,虽然我们知道C站主要还是一个提供模型下载的网站,
但是里面也有一些很不错的AI工作流值得我们学习使用
我们可以再这个过滤器中勾选出workflow,
然后像下载模型一样就可以了。
4.esheep (https://www.esheep.com)
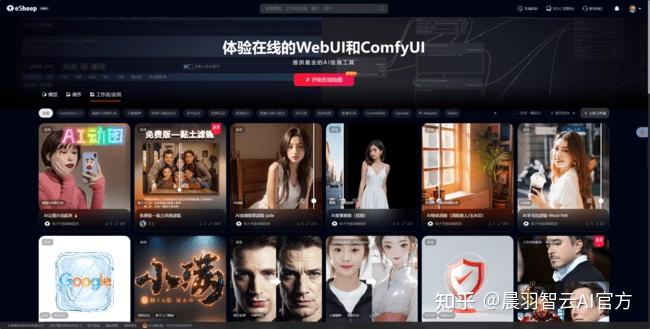
第四个,是咱们国内自己的工作流网站esheep
跟前面的差不多,但是不需要魔法速度也更快更适合我们中国宝宝。
提醒一下,如果电脑配置不高,
想用云端部署的玩comfyui的宝子们,
就用这个网站,里面的comfyui打开就能用,快去试试吧。https://www.suanyun.cn/console/pod/f2b2ba7aa9de42639150abc6872ebb4b
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









